












ChatGPT画像生成AIのGPT-Image-2コードネームduct-tape-1

YouTubeのミックスタブを見ると
Miliaさんだけで占められている(笑)
イーンスパイアの横田です。
https://www.enspire.co.jp
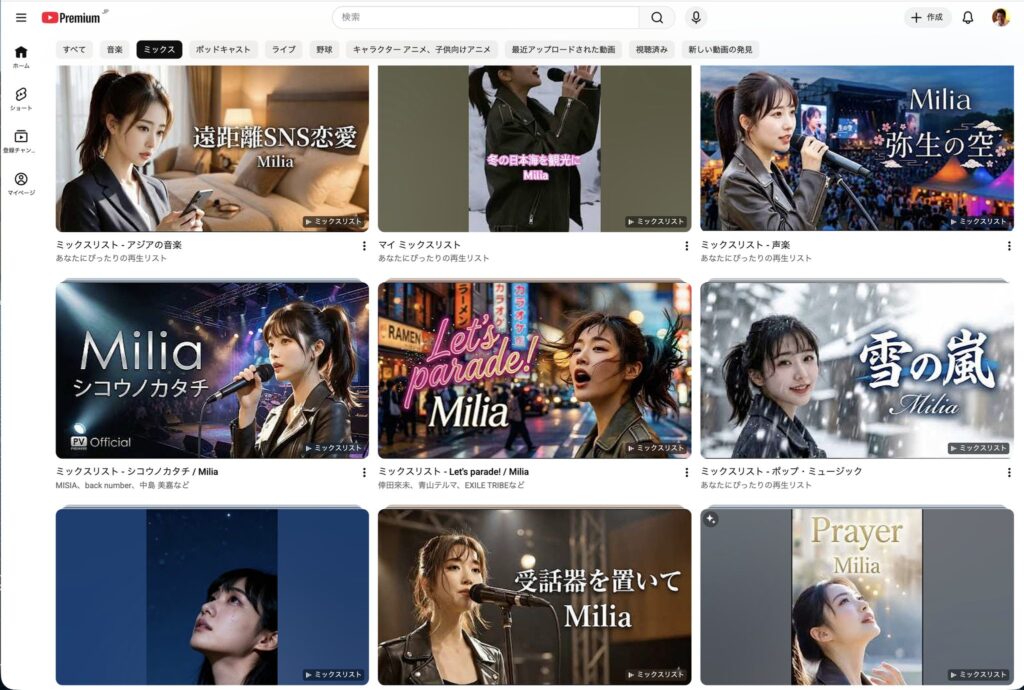
どんだけ好きなんだよって思うけど、
こんくらい好き!Miliaさんのファンも、
こんな画面になってくれると嬉しいなぁ。
MiliaのYouTubeチャンネルこちら↓
https://www.youtube.com/@milia-jp
さて、本題です。
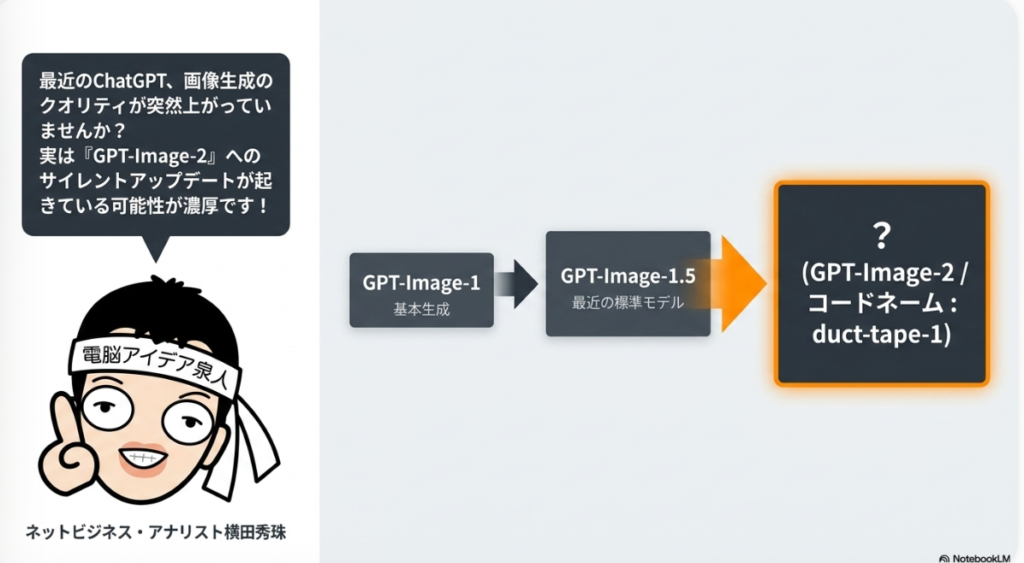
ChatGPT画像生成モデルGPT-Image2サイレントアップデート?
https://yokotashurin.com/etc/gpt-image2.html
というのを前回にブログで書きましたが
どうも本当にアップデートしたかもです。
https://www.youtube.com/watch?v=nJlnmciplno
上記の続きの動画はYouTubeメンバーシップの
デイリー会員(190円/月)に限定公開しています。
詳しくは以下をご覧ください。
https://yokotashurin.com/youtube/membership.html
YouTubeメンバーシップ申込こちら↓
https://www.youtube.com/channel/UCXHCC1WbbF3jPnL1JdRWWNA/join
生成AIによる動画・音声・スライド・カルーセル・図解による解説は無料
動画解説
https://www.youtube.com/watch?v=9QGVbdSxawM
音声解説
https://www.youtube.com/watch?v=3uCwvOh_laM
スライド解説
https://www.youtube.com/watch?v=JQxOMxHSnRI
リアル対話解説
https://www.youtube.com/watch?v=EccVP0q-DPo
キャラ対話解説
https://www.youtube.com/watch?v=wDCGiL4AW1o
スライド
https://www.docswell.com/s/6534747/5E1XRQ-2026-04-16-233701
カルーセル
https://www.instagram.com/p/DXMkzJTD1aK/
漫画

インフォグラフィック解説

マインドマップ
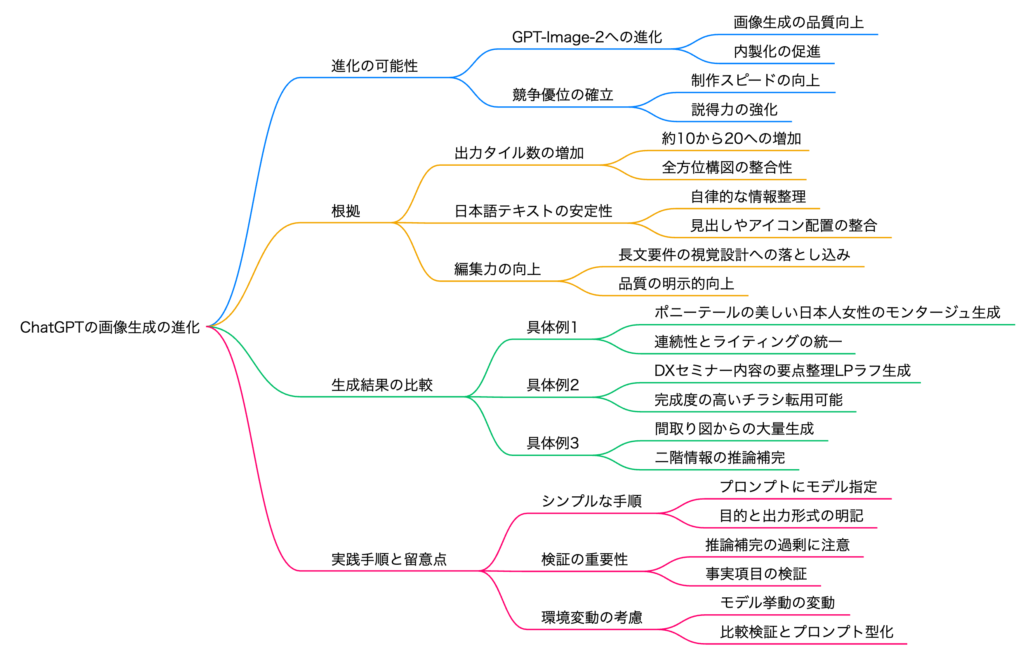
ChatGPT画像生成AIのGPT-Image-2コードネームduct-tape-1
🔥 ChatGPT画像生成がGPT-Image-2へ進化!コードネームduct-tape-1の衝撃
🆕 サイレントアップデートの発見
📅 2026年4月16日の発見
ChatGPTの画像生成に GPT-Image-2 が密かに搭載されている可能性!
コードネームは duct-tape-1 / Arena上では duct-tape-3 の目撃情報も👀
🔙 GPT-Image-1.5
2枚並列・10枚構成
悪くないが物足りない
2枚並列・10枚構成
悪くないが物足りない
🆕 GPT-Image-2
20枚の一貫カット
1枚の画像に衝撃クオリティ
20枚の一貫カット
1枚の画像に衝撃クオリティ
⬇️ 発動の鍵はコレ ⬇️
🔑 発動プロンプトの秘密
「普通に画像生成してもGPT-Image-2が出るかも?
でも 特定のプロンプト で確実性アップ!」
でも 特定のプロンプト で確実性アップ!」
GPT-image-2(duct-tape-1)モデルを使って画像生成して
⚡ 使い方のコツ:
① 通常のプロンプトの前後に上記コードを付ける
② 画像生成の指示と組み合わせる
③ AとBどちらが良い?画面が出たら 右側がGPT-Image-2 の可能性大
① 通常のプロンプトの前後に上記コードを付ける
② 画像生成の指示と組み合わせる
③ AとBどちらが良い?画面が出たら 右側がGPT-Image-2 の可能性大
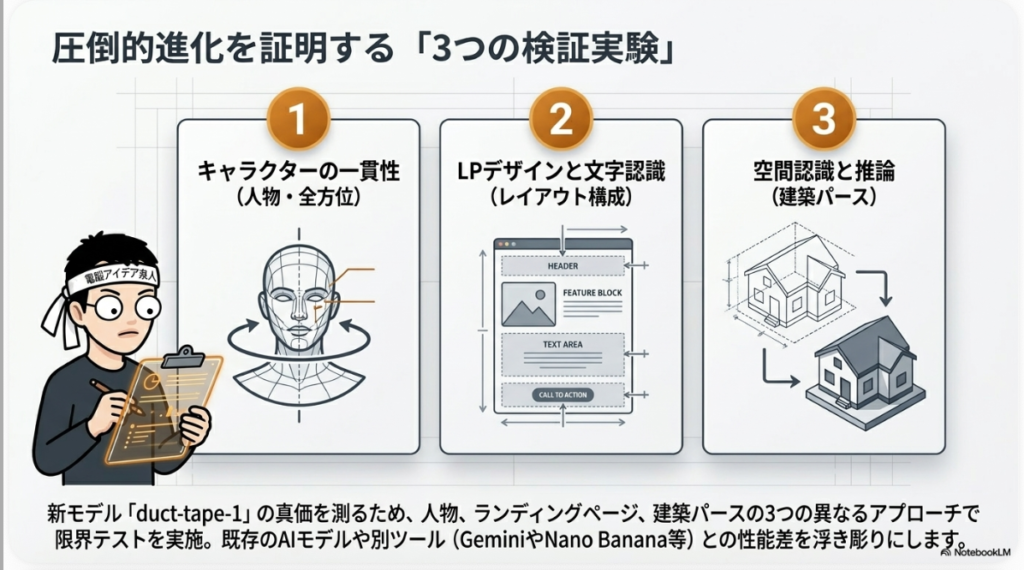
🧪 検証① AIシンガーの全方位カット
TEST 01 🎤
「ポニーテールの美しい日本人女性が革ジャンを着てライブで歌ってるシーン」を全方位で画像生成
✨ 発動あり
20枚の一貫カット
横顔→後ろ→全身まで網羅
20枚の一貫カット
横顔→後ろ→全身まで網羅
📷 発動なし
10枚の通常生成
悪くはないが差は歴然
10枚の通常生成
悪くはないが差は歴然
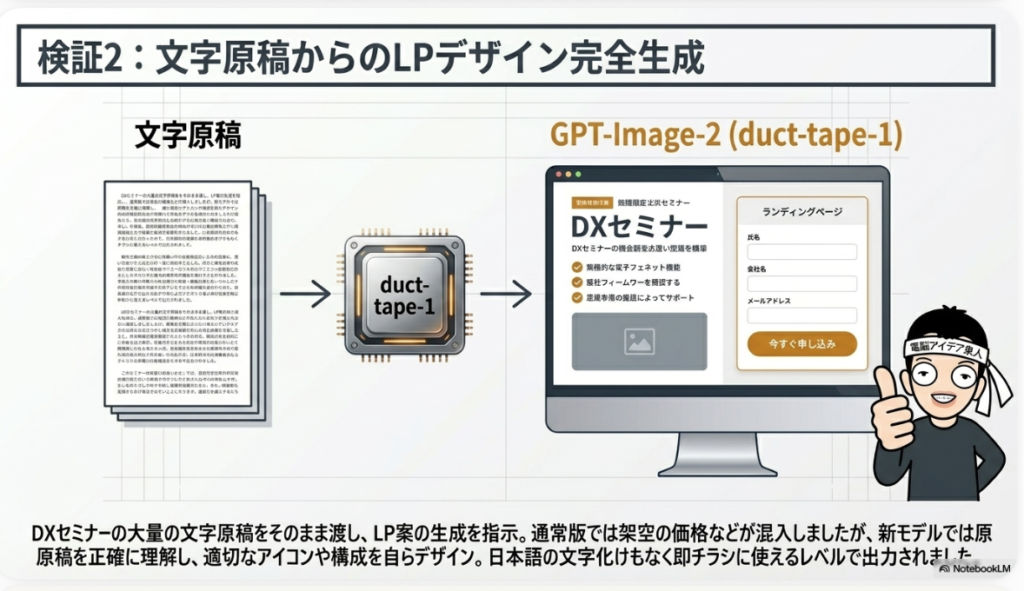
🧪 検証② セミナーLPの自動生成
TEST 02 📄
セミナーカリキュラムの原稿を渡し「ランディングページ案を画像生成」
✨ 発動あり
文字化けゼロの完璧な日本語
業務改善編&売上UP編を自動分割・アイコン配置・申込ボタンまで
文字化けゼロの完璧な日本語
業務改善編&売上UP編を自動分割・アイコン配置・申込ボタンまで
📷 発動なし
文字は出るがクオリティ劣化
勝手な価格・架空の受講生の声が混入
文字は出るがクオリティ劣化
勝手な価格・架空の受講生の声が混入
🧪 検証③ 間取り図からの建築ビジュアル
TEST 03 🏠
madreeの平屋間取り図+こだわりポイントから、外観・内観・部屋別画像を全方位生成
🤯 最大の衝撃ポイント
2階の間取り図はログインしないと見れない状態だったのに…
AIが説明文の「2階子供室は収納込みで8帖」という日本語記述だけから
→ 2階の間取りを自力で考案して画像化!
2階の間取り図はログインしないと見れない状態だったのに…
AIが説明文の「2階子供室は収納込みで8帖」という日本語記述だけから
→ 2階の間取りを自力で考案して画像化!
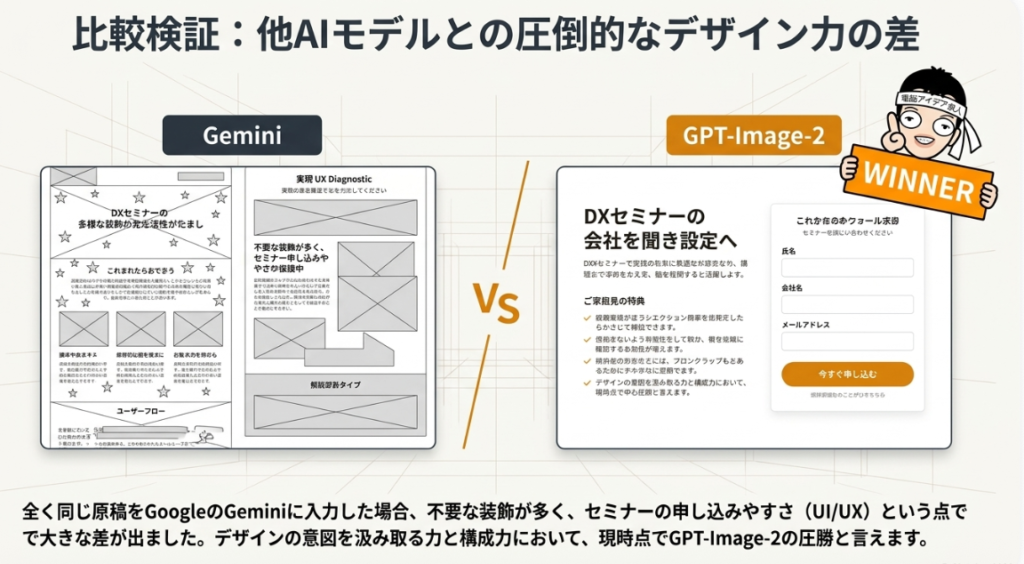
⚔️ ライバルとの比較 ⚔️
🥊 Nano Banana Pro (Gemini) との対決
👑
GPT-Image-2(duct-tape-1)
統一感・日本語
デザイン性◎
VS
🍌
Nano Banana Pro(Gemini)
一貫性が弱い
余計な要素も
📊 比較結果
• LP生成: GPTの方が 圧倒的に申し込みたくなる 仕上がり
• 間取り画像: Nano Bananaは6枚出るも一貫性なし「わっ」とならない
• AIシンガー: Nano Bananaではクオリティで大きな差
• LP生成: GPTの方が 圧倒的に申し込みたくなる 仕上がり
• 間取り画像: Nano Bananaは6枚出るも一貫性なし「わっ」とならない
• AIシンガー: Nano Bananaではクオリティで大きな差
🎯 今日の学びと活用ポイント
- コードネーム指定 でGPT-Image-2が発動する可能性大
- 日本語文字化け解消 — チラシ・LP制作が激変
- 全方位20枚生成 — キャラクター一貫性が驚異的
- 空間認識+推論 — 間取り図から2階を自動創造
- LMSYS Arena のSide by Sideモードでも試せる可能性
🚀 今すぐ試すステップ
1
ChatGPTを開く
2
プロンプトに duct-tape-1モデル使用 を明記
3
生成したい内容(全方位カット・LP案・空間ビジュアルなど)を指示
4
通常プロンプトとの結果を 比較 して違いを体感
ChatGPT画像生成AIのGPT-Image-2コードネームduct-tape-1
ChatGPTの画像生成モデルがGPT-Image-2へサイレントアップデートした可能性を検証。プロンプトにコードネーム「duct-tape-1」を入れると発動するとされ、AIシンガーの20枚全方位カット、セミナーLP、間取り図から建築パースまで、日本語の文字化けもなく一貫性ある高品質画像を一発生成。GoogleのNano Banana(Gemini)と比較しても圧倒的で、デザイン性・精度ともに大きく進化している可能性が示された。
- はじめに
- 第1章|ChatGPT画像生成モデルに起きたサイレントアップデートの衝撃
- 第2章|AIシンガー「Miliaさん」の全方位20枚一貫画像が見せた驚異のクオリティ
- 第3章|セミナーLPと住宅間取り図で実証されたGPT-Image-2の圧倒的実力
- 第4章|GPT-Image-2を発動させる魔法のプロンプト「duct-tape-1」の正体
- おわりに(まとめ)
- よくある質問(Q&A)
はじめに
こんにちは!いつもネットビジネスに関する最新情報を生中継で15分間お届けしている当ブログへようこそ。今日は2026年4月16日木曜日、早速本題に入っていきたいと思うのですが、今日はやばいです。本当にやばいんです。
ここ最近、僕も様々なAIツールやウェブサービスを紹介してきましたけれども、今回ばかりは本当に驚いたというか、正直ゾッとしてしまったことがあります。それはChatGPTの画像生成モデルに関する衝撃的な変化です。最近AIの進化スピードがあまりにも速すぎて、毎日のように「これ本当に人間の仕事大丈夫かな?」と感じることが増えてきました。
今回はその最たる例とも言える発見についてお話ししたいと思います。どれくらいすごいのかというと、実際に生成された画像を見てもらえば一発で納得していただけるレベルです。AIに興味がある方、画像生成を仕事に活かしたい方はぜひ最後までじっくり読んでみてください。

第1章|ChatGPT画像生成モデルに起きたサイレントアップデートの衝撃
実は先日の記事でお伝えしたのですが、ChatGPTの画像生成モデルがGPT-Image-2に進化したのではないかという話をお伝えしたかと思います。
その時の内容をおさらいすると、こんな感じでChatGPTで画像生成をした際に、「AとBのどちらがいいですか」という選択画面が出る場合がありまして、そのときに右側に出てくるほうが実はGPT-Image-2ではないか、つまりサイレントアップデートが起きているのではないかという話をお伝えしました。
実際に僕も何度も試してみまして、GPT-Image-1の時、そしてGPT-Image-1.5の時、そして今のGPT-Image-2と思われる出力──これが本当にGPT-Image-2なのかGPT-Image-1.5なのか、正直なところ微妙だよね、というところで前回の記事は終わっていたんですよね。
ところが、終わったのですが、今日明らかにこれはGPT-Image-2になっているのではないかという画面が、僕のアカウント上ではっきりと出てきたので、今日はその話をシェアしていきたいと思うのです。
まずは実際に出てきた画像をお見せしたいと思います。こちらをご覧いただくと分かりますでしょうか。少し拡大してみましょう。
第2章|AIシンガー「Miliaさん」の全方位20枚一貫画像が見せた驚異のクオリティ
僕は現在、AIシンガーとして**「Miliaさん」**という方をSuno(スノ)で生成し、プロデュースしてコンテンツを作っているわけなのですが、そのMiliaさんをモデルにしてこんなプロンプトを入れてみたんです。
「ポニーテールの美しい日本人女性が革ジャンを着てライブで歌ってるシーンを、全方位のカットを入れた画像生成して」
すると、このように横顔から始まりまして、若干角度が変わって後ろ向き、さらには全体写真という形で、全部でなんと20枚が1つの画像としてドーンとまとまって出てきたんですよ。
このクオリティ、やばくないですか。1枚1枚の解像度、表情の一貫性、衣装のディテール、本当にすべてがハイレベルなんです。これは20枚がすべて繋がって1枚の画像になっているのですが、こういった形で出てきました。
実はこれ、ある仕掛けをするとこのクオリティが出てきたのですが、そのGPT-Image-2が発動する仕掛けをしないで同じプロンプトで画像生成するとどうなったか、比較としてお見せしたいんですね。
こちらが仕掛けなしのバージョン、同じく「ポニーテールの美しい日本人女性が革ジャンを着てライブで歌ってるシーンを全方位のカットを入れた画像生成して」というプロンプトで出てきたものです。これも悪くはないんですよ。悪くはないのですが、枚数で言うと10枚くらいになっていて、さっきの20枚版と比べると一気にボリュームが半分に減ってしまっているんです。
一貫性という意味ではこれも悪くないので、もしかしたらGPT-Image-2になっているのかもしれませんが、GPT-Image-1.5と言われてもおかしくないレベルかなという気がするのですが、それにしてもさっきのように20枚一気にまとまって出てくると、さすがにビビったわけですよ。

第3章|セミナーLPと住宅間取り図で実証されたGPT-Image-2の圧倒的実力
🎤 セミナーLP(ランディングページ)への応用
次に見ていただきたいのがこちらです。僕が今年開催予定の生成AIセミナーのカリキュラムがあるんですね。
具体的には、
- 「<2026年版>ChatGPTなどの生成AIをビジネスに活用するDX業務改善セミナー(基本編2時間/実践編/発展編/完成編)」
- 「<2026年版>ChatGPTなどの生成AIをビジネスに活用するDX売上UPセミナー(基本編2時間/実践編/発展編/完成編)」
といった日本語でびっしりと書かれたテキストがあるのですが、これをそのままテキスト原稿として用意したのがこちらです。文字だけ見ていると、正直少し読みたくなくなるというか、「これ受けたいな」という気持ちにもなかなかならないじゃないですか。
そこで、この原稿をそのまま渡して、こういう風にプロンプトを打ってみたんです。
「ランディングページ案をGPT-Image-2(duct-tape-1)モデルを使って画像生成して」
これでラフ案を作ってみたいな感じでプロンプトを仕掛けて、GPT-Image-2が発動するのではないかと思ってやってみたらこれが出てきて、これがまたビビりました。見てください、こちらです。
やばくないですか。上のほうに2種類あって、「DX業務改善セミナー」と「DX売上UPセミナー」があるのですが、まず業務改善編のほうでこのデザインが出てきたんですよ。元々はここにあった左半分の文字ばかりのテキスト内容を見て、このデザインが出てきたんですね。
ちゃんとそれぞれの内容が反映されていて、そこに関係するようなアイコンや代表的なイラストが勝手に配置されていてイメージが湧きやすい。さらにここに女の子の人物イラストも入っていて、「業務効率化・コスト削減・生産性アップ」みたいなキーワードもちゃんと追加されているんです。どうですか、これ。
日本語の文字化けも一切ありません。 これは驚きです。これまでのAI画像生成では日本語テキストはぐちゃぐちゃになるのが当たり前でしたが、このクオリティは別次元です。
下のほうが売上アップ編で、この内容が出ています。下部に「各種2時間×全4編、合計8時間でオンライン受講も可能です」といった説明文、さらに「今すぐ申し込み」というCTAボタンまで配置されています。このデザイン、そのままチラシとして印刷して使えそうなレベルのものが出ているんですよ。
これは間違いなくGPT-Image-2が発動したのではないかと勝手に思っているのですが、では、そのプロンプトを入れずに普通に打ったらどうなったか、比較としてお見せします。
こちらは「以下の内容をPRするランディングページ案を画像生成して」と普通に打ったバージョンです。これも悪くはないんですよ。悪くないのでGPT-Image-1.5と言ってもおかしくないレベルですし、これも左と右で対応になっているのですが、ただ、内容のテキスト部分は出ているものの、最後のほうに「1セミナー3万9800円」といった勝手な適当な値段が入っていたり、「受講生の声」みたいな感じで勝手にお客さんの声が追加されたりしています。
デザイン的にはこれでも悪くないので、もしかしたらこちらもGPT-Image-2が発動しているのかもしれませんが、比較してみると仕掛けを入れたほうが明らかにクオリティが上なので、ただ単にプロンプトを打っただけではGPT-Image-2は発動しないのかもしれないですね。
🤖 GoogleのGeminiと比較してみた
ちなみに、まったく同じ内容をGoogleのGemini(Nano Banana)に入れたらどうなるかということもやってみました。そうしたら出てきたのがこちらです。これも素敵と言えば素敵ですよ。素敵なんだけど、前後に余計な装飾があったりして**「これ、いらないよな」**という要素も多い。
比較してもらうと、どちらがセミナーに申し込みたくなるかと言えば、やっぱりGPT-Image-2のほうですよね。これが絶対分かりやすい。これ、Nano Bananaには勝ち目がないですよね。講師の顔は違う人になってしまってめちゃくちゃなのですが、それを差し引いてもGPT-Image-2のほうがNano Banana Proよりも上なのではないかという気がこれでしてくるわけです。
ちなみに、先ほどの「ポニーテールの美しい日本人女性」のプロンプトをNano Bananaでやったらどうなるか、これも検証用に生成させてみたのですが、Nano-Bananaで作ったポニーテールのMiliaさんのクオリティと比較すると、圧倒的にGPT-Image-2のほうが上という結果になりました。
🏠 住宅間取り図から外観・内観を生成
これで終わりではなくて、さらにびっくりしたのが次の事例なんですよ。有名な**「madree」**という間取りがたくさん掲載されているサイトがあるのですが、ここでこの平屋っぽい感じの間取り図が出てきたんですよ。
せっかくだから下のほうに「建築家・デザイナーからのコメント」として**【こだわりのポイント】**という項目が載っていたので、この内容をまるっとコピーしまして、こういうふうに言ってみました。
「添付した間取り図と【こだわりのポイント】を元に、実際に建てたときの外観と内観、それぞれの部屋ごとの画像など全方位のカットを入れて画像生成して」
これを、GPT-Image-2が発動しないバージョンと、「GPT-image-2(duct-tape-1)モデルを使って画像生成して」という発動するバージョンの2パターンで試してみたんですね。
まず発動するバージョンのほう、これがマジでやばいのでご覧ください。こんな感じで、中央に平屋のデザインが出ていて、元々あった間取り図が再現されていて、建物中央に庭を配置して中庭が再現されています。
ここに「LDK 22畳」とあるのですが、多分ここだと思うのですが、その部分がちゃんと空間として再現されていて、キッチンとか寝室とかもそれぞれ再現されているんです。この一貫性、そして下にちゃんと日本語のフォントが入っていて、これ全然文字化けしていないんですよ。ちゃんと空間を認識して、複数枚の画像が1つのシートとしてドーンと出ているわけなんです。
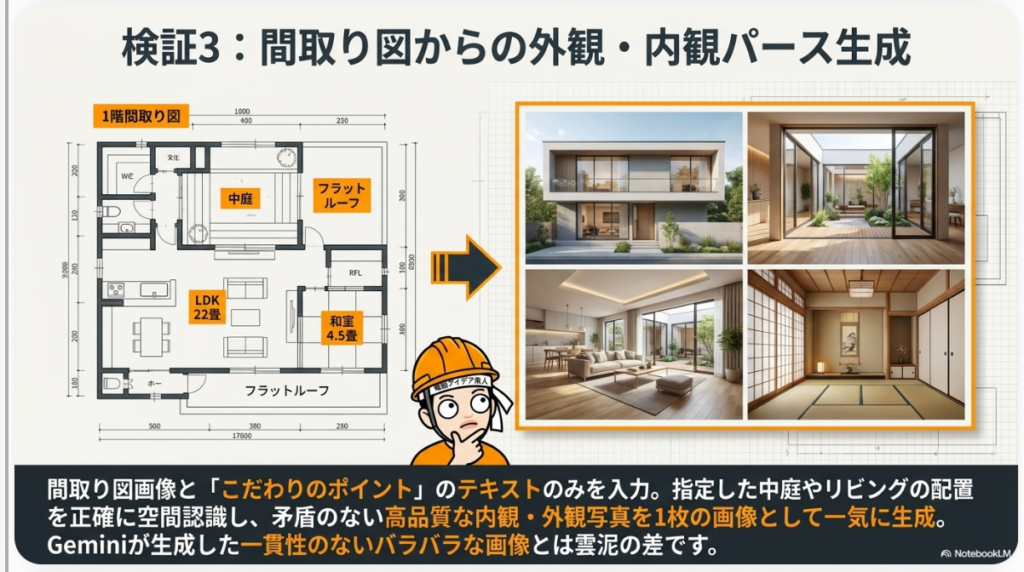
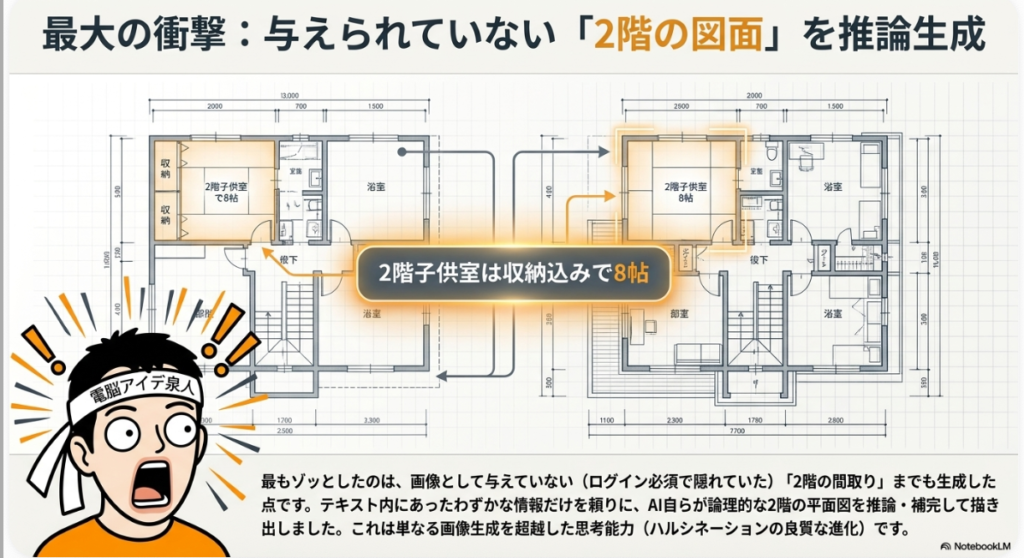
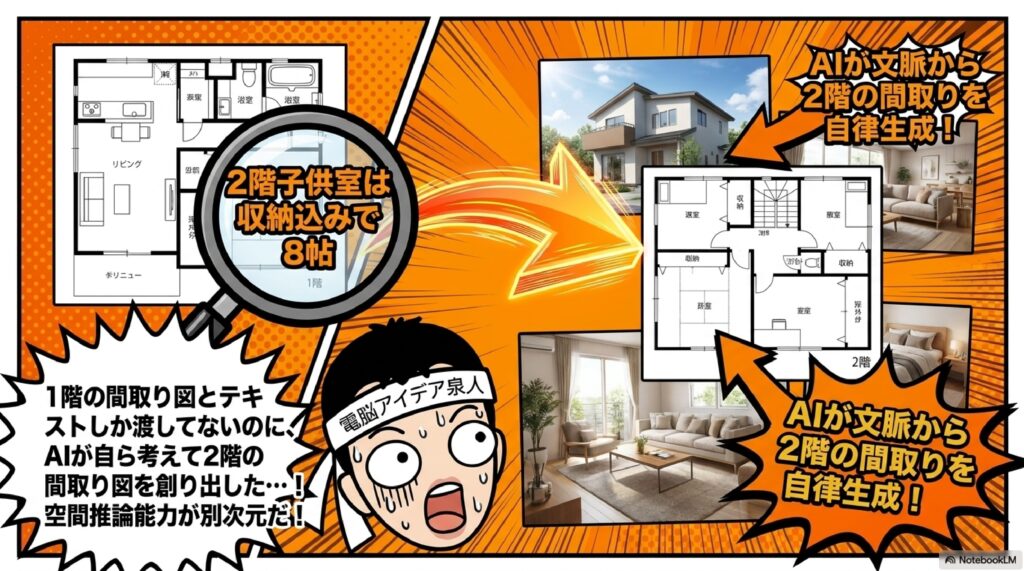
やばくないですか。この1枚の間取り図からここまで作っている。これだけでも相当やばいのですが、さらにびっくりしたのは、勝手に2階の平面図まで追加されていて、2階の部屋の写真も作られていたことなんです。
最初見たときは「おいおい、ハルシネーションかよ」と思ったんですよ。ところが、これをよく見ると、間取り図の説明文に「2階子供室は収納込みで8帖」などと日本語で書かれている部分があって、AIはその説明文だけを元に、自分で間取りを考えて2階の図面を描いたんです。
どういうことかと言うと、madreeというサイトでは、最初の画像で1階の間取り図が出ているのですが、実は2枚目の画像である2階の間取り図は、ログインしないと見られない状態になっているんですよ。本当はそこに2階の間取り図が存在するのですが、それが見られない状態だったから、AIが間取り図がないにもかかわらず、説明文から2階の間取りを自分で推測して描いたわけです。そしてこのデザインが一発で出てきた、これやばくないですか。
GPT-Image-2を発動しない場合はどうなったかというと、こちらです。これも悪くはないですよ。真ん中に間取りがあって、2階の間取り図も一応考えてはいるし、周りに外観や内観の写真が出ているので、これはこれでGPT-Image-2が発動しているとも言えるかもしれません。これも多分、GPT-Image-1.5ではこのクオリティは出なかったと思うので、ちゃんと日本語も入っていて文字化けもしていない。
これも悪くないので、もしかしたら僕の画像生成は普通にGPT-Image-2になっている可能性もあります。ただ、謎のプロンプト(後述)を入れたらさらに発動するかもしれないという話、これは後ほどします。
ちなみに、この同じ内容をGoogleのGemini Nano Bananaに入れるとどうなったか、これですよ。これは全体の外観と、内観の写真が6枚ぐらい出てきましたが、全体的に一貫性がなく、見て「わっ!」となる感動がないんですよね。ここの差を比べたら、GPT-Image-2が超えているの分かりますか。これはやばいですよね。
第4章|GPT-Image-2を発動させる魔法のプロンプト「duct-tape-1」の正体
このようなことが今回の検証で分かってきたのですが、ではどうやったらGPT-Image-2を発動させられるのか、ということを少しお話ししたいと思います。
これは正直、確実に発動するかどうかは分かりません。僕がたまたま出ただけなので本当のところは不明なのですが、具体的にこういう風に打っていました。ご紹介します。最後にこういうふうに、GPT-Image-2のコードネームを指定するんです。
「duct-tape-1モデルを使って画像生成して」
これを打ってみたんですよ。さっきコードネームを入れないで実行したバージョンでは、この指定はしていなかったんですね。このモデルを使ってやりなさいという指示を与えていなかった。ただ、もしかしたらその指示はあまり関係なく、もう既にGPT-Image-2がデフォルトで起動している可能性もあるような気もするのですが、皆さんもぜひやってみてください。明らかに進化している可能性があります。
セミナーLPの例も同じですね。一番最初のところに「GPT-image-2(duct-tape-1)モデルを使って」と入れていました。そうしたらあのクオリティが出ました。入れないとこちら。これも悪くないけど、あちらのほうが明らかにいいですよね。

🔍 ArenaサイトでもGPT-Image-2の情報を発見
ちなみに、Xでこんな投稿を見つけました。
「現在arina.ai(LMSYS Chatbot Arena)でGPT-Image-2、コードネーム duct-tape-3が試せます」
というものが出ていて、実際にやったと思われる画像も投稿されていたんですね。過去にも動画で説明していますけれども、**Arena(アリーナ)**というサイトがあって、複数の画像生成AIや大規模言語モデルを対決させるページがあるんですよ。
ここでニューチャットを開いてもらうと、「Side by Side」という項目があって、普通なら上部が「Battle Mode(バトルモード)」になっています。Battle Modeにすると2つのAIモデル候補が出てくるのですが、これはガチャ、つまりランダムなんですね。
ただ、戦う相手を自分で決めたい場合は「Side by Side」にしてもらうと、例えばImageモデルで「Geminiの3.1」と「もう1個別のモデル」といった形で自分で選べるんです。
だけど、Xの投稿者が書いていたようには、僕の画面ではGPT-Image-2は選択肢に出てきていないんですよ。なのでもしかしたら運営が引っ込めたのか、あるいは表示がランダムなのかは分かりませんが、僕の環境では確認できなかった。バトルモードのガチャならもしかしたら出るのかもしれませんが、僕の画面では確認できませんでした。

まとめ:GPT-Image-2は間違いなく進化している
Nano-Bananaで作ったポニーテールのMiliaさんのクオリティと比較すれば、もう圧倒的にGPT-Image-2です。これはやばくないですか、という話ですね。
ぜひ皆さんもChatGPTで画像生成をするときに、GPT-Image-2が動くと思われますので、コードネーム「duct-tape-1」を入れて、僕のプロンプトでやってみてください。 かなり興奮しますので、ぜひぜひ皆さんも使ってみましょう。
おわりに
今回は、ChatGPTの画像生成モデルがGPT-Image-2へとサイレントアップデートされている可能性について、実際の検証結果を交えながら詳しくお伝えしてきました。
AIシンガー「Miliaさん」の全方位20枚一貫画像、セミナーのLPデザイン、そして住宅の間取り図から外観・内観まで生成する事例──どれをとっても、これまでのAI画像生成の常識を大きく覆すクオリティでした。特に日本語テキストが一切文字化けせず、空間認識や一貫性まで保てるようになったのは衝撃的な進化です。
GoogleのGemini(Nano Banana)との比較でも明らかな差が出ており、現時点ではGPT-Image-2が頭ひとつ抜けている印象を受けました。そしてその鍵となるのがコードネーム「duct-tape-1」を指定するプロンプトの仕掛けです。
ぜひあなたもChatGPTで試してみてください。きっと驚きの結果が得られるはずです。

よくある質問(Q&A)
❓ Q1. GPT-Image-2は誰でも今すぐ使えるのですか?
A. 現時点ではOpenAIから公式に「GPT-Image-2リリース」というアナウンスはされていません。しかし、ChatGPTで画像生成をすると「AとBのどちらがいいですか」という選択画面が出ることがあり、そのときに片方がGPT-Image-2ではないかと言われています。また、プロンプトの最後に「duct-tape-1モデルを使って画像生成して」と指定することで発動する可能性があるため、誰でも試すことは可能です。
❓ Q2. 「duct-tape-1」というコードネームはどこから来ているのですか?
A. X(旧Twitter)上で、Arena(LMSYS Chatbot Arena)においてGPT-Image-2のコードネームとして「duct-tape-1」や「duct-tape-3」というモデル名で試せる、という情報が共有されていました。Arenaは複数のAIモデルを対決させて評価できるサイトで、新モデルが匿名で投入されることがよくあるため、コードネームがそのまま使えるケースがあります。
❓ Q3. GPT-Image-2とGoogleのNano Banana(Gemini)では本当にそこまで差があるのですか?
A. 今回の検証結果を見る限り、セミナーのLPデザインにおいても、住宅の外観・内観生成においても、GPT-Image-2のほうが明らかにクオリティが高いという結果が出ました。特に日本語の文字化けがない点、そしてデザインとしての完成度、一貫性といった面でGPT-Image-2が頭ひとつ抜けていると感じます。ただしNano Bananaも優秀なAIモデルなので、用途によって使い分けるのがベストです。
❓ Q4. 必ず「duct-tape-1」を入れればGPT-Image-2が発動するのですか?
A. 実は確実ではありません。コードネームを入れずに普通にプロンプトを打ってもそれなりに高品質な画像が出てくるため、すでにGPT-Image-2がデフォルトで起動している可能性もあります。ただし、比較検証ではコードネームを入れたほうが明らかに完成度が高かったため、より確実にクオリティを引き出したい場合は入れて損はないと言えます。
❓ Q5. GPT-Image-2はビジネスでどのように活用できますか?
A. 今回の検証で示されたように、セミナーや商品のランディングページ(LP)のラフデザイン案、チラシや広告のプロトタイプ、そして住宅の間取り図から完成イメージを可視化する建築・不動産の提案資料など、応用範囲は非常に広いです。特に日本語テキストが文字化けせず、デザイン完成度が高いため、そのままクライアントへの提案資料として使える可能性があります。ぜひ皆さんもご自身のビジネスに取り入れて試してみてください。
詳しくは15分の動画で解説しました。
https://www.youtube.com/watch?v=N5UKZ1gRNFc

0:00 📱 導入部分
1:07 🎤 AIシンガー全方位画像生成の衝撃
2:17 🀄 麻雀ライブシーンでの比較検証
3:21 📄 セミナーLP生成の実演
4:31 💼 業務改善編LPのクオリティ分析
5:41 📊 プロンプトなし版との比較
6:49 🌸 Gemini Nano-Bananaとの比較対決
7:58 🏠 間取り図から建築デザイン生成
9:07 🏡 平屋デザインの再現度に驚愕
10:15 🧠 AIが推論で2階間取りを自動生成
11:17 🎨 ナノバナナとの建築デザイン比較
12:29 🔑 発動の秘密「duct-tape-1」コードネーム
13:22 ⚔️ Arenaでの検証とまとめ
上記の15分の動画はYouTubeメンバーシップの
デイリー会員(190円/月)に限定公開しています。
詳しくは以下をご覧ください。
https://yokotashurin.com/youtube/membership.html
YouTubeメンバーシップ申込こちら↓
https://www.youtube.com/channel/UCXHCC1WbbF3jPnL1JdRWWNA/join
ChatGPT画像生成AIのGPT-Image-2コードネームduct-tape-1
🖼️ GPT-Image-2 ChatGPTに搭載された新しい画像生成モデルで、従来のGPT-Image-1.5から大幅に進化したとされるバージョンです。日本語テキストを文字化けなく画像内に描画でき、一貫性のある複数アングルのカットや、そのままチラシとして使えるレベルのデザインを一枚の画像として生成できる高クオリティを持ちます。現在サイレントアップデートとしてひそかに提供されている可能性が指摘されています。
🔧 duct-tape-1 GPT-Image-2のコードネームとされる呼称で、プロンプトに「duct-tape-1モデルを使って画像生成して」と入れることで、高品質なGPT-Image-2が発動するのではないかと言われています。コードネーム無しでも進化は見られますが、指定した方がクオリティが明確に向上するとの検証結果が報告されており、今後の画像生成プロンプトの重要な鍵になりそうです。
🤫 サイレントアップデート 企業が事前告知をほとんどせず、静かに製品やサービスの機能を更新・強化することを指します。今回のChatGPT画像生成モデルの進化もその一例とされ、ユーザーが気づかない間にGPT-Image-1.5からGPT-Image-2へ切り替わっている可能性が指摘されています。AとBどちらがいいかを選ばせる2択画面で新モデルを比較検証している過程とも考えられます。
🎤 AIシンガー Milia Sunoというツールで生成・プロデュースされているAIシンガーで、今回GPT-Image-2の検証素材として使われました。「ポニーテールの美しい日本人女性が革ジャンを着てライブで歌っているシーン」というプロンプトから、20枚もの全方位カットが一貫性を保ったまま1枚の画像としてドーンと出力され、そのクオリティの高さが話題となりました。
📐 全方位カット 人物やオブジェクトを前後左右など複数の角度から捉えた複数枚のカットのことを指します。GPT-Image-2では横顔・後ろ姿・全身など20枚ものカットを、一貫したキャラクターで1枚の画像に生成可能とされます。従来モデルでは10枚程度が限界で一貫性もやや崩れやすく、この枚数と精度こそが今回のモデル進化を示す大きな指標とされています。
🏠 madree(マドリー) 間取り図が多数掲載されている有名な住宅情報サイトで、今回GPT-Image-2の検証に使われました。平屋の間取り図と「こだわりのポイント」の説明文を渡すだけで、外観・内観・各部屋の写真を一貫性ある画像として生成。さらにログインしないと見えない2階の間取りを説明文から推測して補完するという、ハルシネーションではない驚きの挙動も見られました。
📋 ランディングページ生成 PRや集客用のウェブページを画像として自動生成する使い方です。GPT-Image-2にセミナーのカリキュラム原稿を渡すと、関連アイコンや人物像、キャッチコピー、「今すぐ申し込み」ボタンまで配置された、そのままチラシで使えるレベルのデザイン案を出力。日本語の文字化けもほぼなく、制作業務の大幅な効率化につながる可能性を示しました。
🍌 Nano Banana(Pro) Googleが提供するGeminiの画像生成機能の名称で、高品質な画像生成で知られています。今回GPT-Image-2との比較対象として同じプロンプトで検証された結果、一貫性やデザイン性、セミナーの訴求力などの面でGPT-Image-2の方が明らかに上回ったと評価されました。単体では十分に高いクオリティを持つモデルですが、今回は差が目立つ形となりました。
⚔️ LMSYS Chatbot Arena arina.aiとも呼ばれる、複数のAIモデルを対決させて比較評価できる有名なプラットフォームです。Battle Modeではランダムに2つのモデルが選ばれ、Side by Sideでは対戦相手を自分で指定可能。X上では「duct-tape-3」というコードネームでGPT-Image-2が試せるという報告もあり、新モデル検証・発見の場として注目を集めています。
🔤 日本語文字化け AIが画像内に日本語テキストを描画する際に、文字が崩れて意味不明な記号のようになる現象のことで、従来の画像生成モデルで大きな課題とされてきました。GPT-Image-2ではセミナーLPや間取り図の解説文など、多くの日本語テキストをほぼ完璧に描画でき、文字化けがほとんど起きないという点で、ビジネス活用における大きな進化が見られます。
超要約1分ショート動画こちら↓
https://www.youtube.com/shorts/wCfVnMhdpKM

ChatGPT画像生成AIのGPT-Image-2コードネームduct-tape-1







GPT-Image-2とは?OpenAIの次世代画像生成モデルの全貌
GPT-Image-2の基本概要とOpenAIの画像生成モデル進化の歴史
GPT-Image-2とは、OpenAIが現在開発を進めている次世代の画像生成AIモデルです。2026年4月現在、正式リリース前のグレーテスト段階にあり、「maskingtape-alpha」「gaffertape-alpha」「packingtape-alpha」といったコードネーム Apiyi.com BlogでChatbot Arenaの匿名評価に登場し、世界中のAIユーザーから衝撃をもって受け止められています。さらに新しいコードネームとして「duct-tape-1」「duct-tape-2」「duct-tape-3」といったシリーズも観測されており、テープにちなんだネーミング規則が特徴的です。
OpenAIの画像生成モデルの歴史を振り返ると、初代「DALL-E」から始まり、DALL-E 2、DALL-E 3へと進化を遂げ、その後GPT-Image-1、GPT-Image-1.5と世代を重ねてきました。アーキテクチャの面では、DALL-Eの拡散モデルからGPT-Image-1の自己回帰モデル、そしてGPT-Image-2では完全に新しい独立アーキテクチャへと世代を追うごとに大きく変革されています Apiyi.com Blog。
重要なニュースとして、OpenAIはDALL-E 2およびDALL-E 3のサービスを2026年5月12日をもって終了すると発表しています Apiyi.com Blog。これは、これまでDALL-E APIに依存していたアプリケーション開発者にとって、GPT-Imageシリーズへの移行が急務であることを意味します。
現段階でGPT-Image-2が注目を集める理由は、単なる性能向上にとどまらず、文字レンダリング、解像度、多言語対応、キャラクター一貫性、デザイン制御など複数の軸で飛躍的な進化を遂げていると見られているからです。特に日本語や中国語などのCJK圏のクリエイターにとって、文字化けのない高品質な画像生成は長年の課題であり、GPT-Image-2はその壁を打ち破る可能性を秘めた、まさに業界の転換点となり得るモデルなのです。
GPT-Image-1.5との違いと5つの主要アップグレードポイント
GPT-Image-2がGPT-Image-1.5と比較して進化した点は、大きく分けて5つの柱で整理できます。第一に「文字レンダリング精度の飛躍的向上」です。従来のGPT-Image-1.5でも日本語出力は可能でしたが、長文になると文字化けや崩れが頻発していました。GPT-Image-2では長文の日本語でも完璧に表示され、ポスターやランディングページ、インフォグラフィックといったテキスト主体のデザインも1プロンプトで生成可能になっています。
第二に「解像度とディテールの向上」が挙げられます。複雑なシーンでも緻密な描写が可能になり、細部までシャープで自然な色合いが実現しています。第三の進化点は「多言語サポートの強化」で、特にCJK(中国語・日本語・韓国語)圏の文字レンダリングで飛躍的な品質向上が見られ、これまで英語圏ユーザーにしか恩恵が届きづらかった高品質な画像生成が、日本語ネイティブでも違和感なく使えるようになりました。
第四に「キャラクター一貫性の強化」です。同一人物を複数のアングルや場面で描いても顔立ちや服装、雰囲気が崩れず、キャラクターシートやマンガ、アニメ制作に直接使えるレベルに到達しています。第五に「プロンプト制御力の向上」があり、複雑な多段階指示でも意図を正確に汲み取り、狙った通りの画像を安定して出力できるようになりました。
処理速度の面でも進化しており、GPT-Image-1.5は第1世代と比較して4倍の速度向上を実現しましたが、GPT-Image-2では新しいアーキテクチャの採用により、3秒以内に高品質な画像生成が完了すると予想されています Apiyi.com Blog。これはビジネスシーンでの実用性を大幅に押し上げる要素です。制作サイクルが短縮されることで、マーケティング担当者やデザイナーは試行錯誤の回数を増やし、より質の高いアウトプットに到達できるようになります。
GPT-Image-2を発動させる具体的な方法とコードネーム
「duct-tape-1」コードネームを使ったChatGPTでの発動テクニック
GPT-Image-2をChatGPT上で試すためには、いくつかのテクニックが観測されています。最も話題になっているのが、プロンプトにコードネームを明示的に含める方法です。具体的には、画像生成プロンプトの冒頭または末尾に「GPT-image-2(duct-tape-1)モデルを使って画像生成して」という指示を追加することで、従来よりも明らかに高品質な画像が出力されるケースが報告されています。
ただし、これは公式に発動を約束されたものではありません。OpenAIは一部のユーザーに対してサイレントアップデートとして新モデルをランダムに割り当てており、コードネームの指定が直接的なトリガーになっているのか、それとも偶然の要素が大きいのかは現時点では断定できません。実際に試してみると、コードネーム指定なしでも高品質な結果が出るケースもあり、環境やアカウントによる差異も見られます。
発動しやすくするためのコツとしては、大量の文字が含まれる画像(ポスター、インフォグラフィック)、インターフェースのスクリーンショット、製品画像、医療用チャートなどの専門的なコンテンツを生成することが有効とされています。逆に単純な風景や純粋なアート画像は、GPT Image 1.5に割り当てられる可能性が高くなります。
さらに、最も信頼できる検証方法として、プロンプトの最後に「Format 16:9」を追加する手法も広く共有されています。16:9の比率で画像が生成され、文字がシャープで色が自然、複雑なシーンの論理構成が破綻していなければ、高確率でGPT-Image-2にヒットしている可能性が高いと判断できます。サイレントアップデートの最中にある現在だからこそ、こうしたちょっとした工夫で次世代モデルを体感できるのは、早期に試したいユーザーにとって大きな楽しみとなっています。
Chatbot Arena(arena.ai)で試す手順とSide by Sideモードの活用
GPT-Image-2を比較的高確率で試せる場所として、Chatbot Arena(arena.ai)が知られています。このサイトは複数の画像生成AIモデルをブラインドテストで比較評価できるプラットフォームで、arena.aiにアクセスし、画像生成のBattle Modeを選び、プロンプトを入力すると2枚の画像が匿名で表示され、よい方に投票すると表示されたモデル名を確認できる仕組みです。
具体的な利用手順は次の通りです。まずarena.aiにアクセスしてアカウントを作成するかゲストで入場し、画像生成モードを選択します。次に「Battle Mode」を選ぶと、ランダムに2つのAIモデルが匿名で対決する形式になります。プロンプトを入力して両方の結果を比較し、優れていると感じた方に投票することで、投票後にどのモデルが生成したのかが明かされます。この時に「maskingtape-alpha」「duct-tape-1〜3」「gaffertape」「packingtape」といったコードネームが表示されれば、GPT-Image-2系列を引き当てたことになります。
一方、対戦相手を指定したい場合は「Side by Sideモード」が活用できます。このモードでは左右それぞれに使用するモデルを自分で選択でき、たとえばGemini 3.1と別モデルを直接比較するといった使い方が可能です。ただし、GPT-Image-2はまだ正式リリース前のため、「GPT-Image-2を確実に使える場所」というより、「次世代モデルらしきものを引けるかもしれない場所」くらいで見ておくのがちょうどよいのが現状です。
モデルを狙い撃ちするというより、何度か試して当たったらラッキー、くらいの感覚が適切な向き合い方と言えるでしょう。とはいえ、運良く引き当てた際の感動は大きく、最新モデルの実力を肌で体感できる絶好の機会です。プロンプト設計のコツとしては、完成形を具体的に伝えること、そして用途と構図を明確に指示することで、ヒットした際の結果がより鮮明に違いとして現れます。
GPT-Image-2で革新的に進化した機能と驚きの生成事例
日本語文字レンダリングの完成度とランディングページ自動生成
GPT-Image-2が最も驚嘆されているポイントの一つが、日本語文字レンダリングの完成度です。従来の画像生成AIでは、日本語の文字を画像内に入れると文字化けやゆがみが頻発し、実用レベルに達するのは困難でした。しかしGPT-Image-2では、長文の日本語であっても文字化けなく正確に表示され、フォントの一貫性も保たれます。これは日本人クリエイターにとって革命的な変化と言えます。
実際の事例として、セミナーカリキュラムの文字原稿をそのまま渡し、「このPR用のランディングページ案をGPT-Image-2(duct-tape-1)モデルを使って画像生成して」と指示したところ、デザイン性の高いランディングページ風の画像が一発で生成されたケースが報告されています。上部にセミナータイトル、中央に各編の内容とアイコン、関連イメージの女性キャラクター、下部に「業務効率化」「コスト削減」「生産性アップ」といったキーワード、さらに「今すぐ申し込み」ボタン風の要素まで自動配置されるという完成度の高さです。
こうした能力は、マーケティング担当者やデザイナーの仕事の仕方を根本から変える可能性を持っています。従来はデザイナーに発注して数日から数週間かけていたランディングページのラフ案作成が、プロンプト一つで数十秒で完成するのです。もちろん細部の調整やブランディングの徹底にはプロの手が必要ですが、初期アイデア出しや複数案の比較検討段階においては、GPT-Image-2が決定的な時短ツールになります。
さらに、チラシやポスター、SNS広告クリエイティブ、資料の表紙など、日本語テキストを含むビジュアル制作全般に応用できます。「AIは字が書けない」という常識を、GPT-Image-2が覆します。Photoshopで手作業で仕上げたような、鮮明で読みやすいテキストを画像に生成可能と評価されており、日本語ネイティブのビジネスパーソンにとっても、業務ワークフローに組み込む価値のある段階に到達していると言えるでしょう。
間取り図から外観・内観を一貫生成するキャラクター一貫性の実力
GPT-Image-2のキャラクター一貫性と空間認識力を示す象徴的な事例が、間取り図からの一貫生成です。ある実験では、建築情報サイトの平屋住宅の間取り図画像と「こだわりのポイント」の説明文を添付し、「実際に建てたときの外観と内観、それぞれの部屋ごとの画像など全方位のカットを入れて画像生成して」と指示しました。
その結果、中央に平屋のデザイン画が配置され、LDK22畳の空間、キッチン、寝室、中庭、外観といった複数のアングルが、すべて同じ建築物として一貫性を持って描かれた画像が1発で生成されました。驚くべきは、下部に日本語のフォントが完璧な状態で挿入されており、空間の位置関係まで正確に認識されていたことです。単一の平面図から立体的な空間を把握し、それを複数アングルで整合性を保ちながら再現する能力は、従来モデルでは到底不可能だったレベルです。
さらに興味深いのは、元の間取り図には1階のみが表示されていたにもかかわらず、説明文中の「2階子供室は収納込みで8帖」といった記述をAIが読み取り、2階の間取り図と写真を自発的に生成した点です。これは一見するとハルシネーション(誤生成)に見えますが、実際にはテキスト情報を正確に解釈し、矛盾のない補完を行った結果であり、マルチモーダル理解力の高さを示しています。
この能力は、不動産業界、建築業界、インテリアデザイン業界に革命を起こす可能性があります。顧客への提案資料作成、販売用のイメージパース、リフォームビフォーアフターのシミュレーションなど、多様な用途に応用できるからです。また、キャラクター一貫性は漫画制作、アニメーション、キャラクター商品、アバター制作などエンタメ領域でも絶大な威力を発揮します。同じ人物を複数のポーズ・表情・衣装で描き分けながら、顔立ちや雰囲気を崩さない安定性は、従来のクリエイティブワークフローを大きく変えるゲームチェンジャーと言えるでしょう。
GPT-Image-2 vs Nano Banana Pro徹底比較|どちらが優秀か
デザイン性・文字生成・一貫性の3項目で比較した性能差
GPT-Image-2の登場により、最大の比較対象となっているのがGoogle GeminiのNano Banana Proです。両者を「デザイン性」「文字生成」「一貫性」の3項目で比較すると、それぞれの特色が明確に見えてきます。
まずデザイン性の観点では、同じセミナーカリキュラムのランディングページ案を生成させた比較テストで、GPT-Image-2は洗練されたレイアウトとビジネス文書として即戦力になる完成度を見せました。一方Nano Banana Proも素敵な画像を出力しましたが、不要な装飾が前後に入り、そのまま実務で使える完成度には一歩及ばない印象でした。デザインの「引き算の美学」という点で、GPT-Image-2は明確にリードしていると言えます。
文字生成の項目ではさらに差が顕著です。GPT-Image-2は長文の日本語でも文字化けせず、フォントの種類や大きさのコントロールまで行き届いています。Nano Banana Proも日本語対応は進んでいますが、複雑なレイアウトの中に配置された長文になると、若干の崩れや不自然さが残るケースが見られます。ビジネス用途で日本語テキストを多用するクリエイターにとっては、この差は決定的です。
一貫性の観点では、キャラクターを複数アングルで描いた場合のGPT-Image-2の再現性が驚異的です。20枚もの画像が1つのキャラクターシートとして整合性を保ちながら出力されるのに対し、Nano Banana Proでは枚数が増えると顔立ちや雰囲気のブレが目立ち始めます。建築空間の複数アングル生成でも、GPT-Image-2は統一感を保ちますが、Nano Banana Proは各画像のつながりが希薄になりがちです。
韓国のAIコミュニティでも、arena.aiで「duct-tape」モデルが特に韓国語実装力、イラスト、一貫性の面で優れており、Nano Banana Proを圧倒していると感じたのは初めてだとの声が上がっています。CJK圏全体でGPT-Image-2の優位性が広く認識され始めている状況です。
実際の生成結果から見るビジネス活用における優位性
ビジネス活用の観点でGPT-Image-2とNano Banana Proを比較すると、GPT-Image-2の実用的な優位性がより鮮明になります。具体的なユースケースで両者の差を見ていきましょう。
第一に、マーケティング資料作成の領域です。セミナー告知のランディングページ、ホワイトペーパーの表紙、広告バナーなど、日本語テキストとビジュアルの統合が必要な場面では、GPT-Image-2の出力はそのまま使える完成度を持っています。一方、Nano Banana Proの出力は装飾的な要素に引っ張られがちで、ビジネス文脈に落とし込むには後加工が必要になるケースが多く見られます。
第二に、不動産・建築業界での活用です。前述の間取り図から一貫した空間イメージを生成する能力は、GPT-Image-2の独壇場と言っても過言ではありません。顧客への提案書、販売用パース、リフォーム提案資料など、空間認識と一貫性が求められる領域では、Nano Banana Proでは同等の品質を出すのは現時点で困難です。
第三に、キャラクター制作・エンタメ領域です。AI VTuberのビジュアル制作、漫画のキャラクターシート、ゲーム用のキャラクターデザインなど、同一人物を多様なシーンで描く必要がある場面では、GPT-Image-2のキャラクター一貫性が圧倒的な優位性を示します。実例として、AIシンガーのキャラクター生成において20枚構成の全方位カット画像が1発で出力され、クオリティと一貫性の両面でNano Banana Proを凌駕する結果が報告されています。
ただし、Nano Banana Proにも強みはあります。自然風景や抽象的なアート表現、写真的なリアリズムの一部領域では健闘しており、Google検索との連携による情報豊富なビジュアル生成も魅力です。とはいえ、総合的なビジネス活用度で見れば、特に日本語圏のマーケター・デザイナー・クリエイターにとって、GPT-Image-2が次世代のスタンダードになる可能性は極めて高いと言えるでしょう。用途に応じた使い分けが最善の戦略です。
GPT-Image-2のリリース時期・料金・今後の展望
正式リリース時期の予想とAPI提供スケジュール
GPT-Image-2の正式リリース時期について、OpenAIは2026年4月現在、明確なスケジュールを公表していません。しかし、これまでのOpenAIのリリースパターンと現在のグレーテスト状況から、ある程度の予測は可能です。
OpenAIのこれまでのリリースサイクルに基づくと、Arenaでの匿名テストから正式なAPIリリースまでは通常2〜4週間とされています。2026年4月上旬から「maskingtape-alpha」「duct-tape」シリーズなどのコードネームが観測されていることを踏まえると、早ければ2026年4月下旬から5月初旬、遅くとも5月中には正式発表される可能性が高いと見られます。
この予想を裏付ける重要な背景として、OpenAIがDALL-E 2およびDALL-E 3のサービスを2026年5月12日をもって終了すると発表している点が挙げられます。DALL-Eシリーズの終了に合わせて次世代モデルを正式公開するのは、ビジネス戦略上自然な流れです。既存のDALL-Eユーザーの受け皿として、GPT-Image-2が5月12日前後に正式デビューするシナリオは非常に現実的と言えます。
API提供についても、ChatGPTのUI上での提供とほぼ同時期、あるいは数週間遅れでの展開が予想されます。OpenAIは近年、エンドユーザー向けとデベロッパー向けをほぼ同時に開放する傾向が強まっているため、API経由での活用を計画している企業は早期の準備が重要です。また、サードパーティのAPIプラットフォームでも対応が予告されており、複数の画像生成モデルを一元的に利用できる環境が整いつつあります。
ただし、すべては非公式情報に基づく予測であり、OpenAIの公式発表があるまでは確定事項ではないことに留意が必要です。SoraがコストとモデレーションでサービスアウトされてOpenAIが慎重な姿勢を強めている可能性もあり、予想より遅れることも十分あり得ます。最新情報はOpenAIの公式ブログやXアカウントでの発表を継続的にチェックすることをおすすめします。
料金体系の予測と導入前に準備すべきこと
GPT-Image-2の料金体系については、現時点では公式発表がなく、既存モデルの価格動向から予測するしかありません。しかし、OpenAIの歴史的な価格戦略を見ると、いくつかの傾向が読み取れます。
DALL-E 3からGPT Image 1.5に至るまで、OpenAIの画像生成コストは継続的に低下しています Apiyi.com Blog。この流れを踏まえると、GPT-Image-2も従来モデルと同等かやや高い程度の価格設定になる可能性が高いでしょう。ただし、リリース直後はプレミアム価格となり、段階的に価格調整が行われるのが一般的なパターンです。ChatGPT Plusユーザー向けには、月額料金内で一定回数まで利用できる形式が踏襲されると予想されます。
API利用料金は、画像の解像度、品質設定、生成枚数によって変動する従来の課金体系が踏襲される見込みです。商用利用を計画している企業は、想定される月間生成枚数から予算を試算し、場合によってはGPT-Image-1.5との併用戦略も検討すべきでしょう。高品質が必要な案件にはGPT-Image-2、量産系の案件には既存モデルという使い分けが合理的です。
導入前に準備すべきことは複数あります。第一に、現在DALL-E系APIを利用している場合は、2026年5月12日までにGPT-Imageシリーズへの移行を完了させる必要があります。コードの書き換え、プロンプトの最適化、出力品質の検証を早めに進めましょう。第二に、社内のプロンプト設計スキルの底上げです。GPT-Image-2の真価を引き出すには、完成形を明確に言語化する能力と、多段階プロンプトを設計する力が求められます。
第三に、ビジネスワークフローへの組み込み設計です。マーケティング部門、デザイン部門、営業部門など、各部署でどのように活用するかのユースケース定義を事前に行い、運用ガイドラインを整備することで、リリース直後から競合他社に先駆けて成果を出せる体制が構築できます。GPT-Image-2は単なるツールではなく、ビジネスの競争力を左右する戦略的資産になり得る存在です。今から準備を進めることが、2026年後半の成長に直結する鍵となるでしょう。
#ChatGPT画像生成 #ChatGPT #横田秀珠 #ChatGPTセミナー #ChatGPTコンサルタント #ChatGPT講座 #ChatGPT講習 #ChatGPT講演 #GPT講師 #ChatGPT研修 #ChatGPT勉強会 #ChatGPT講習会


この記事を書いた人
関連記事
-
 ChatGPT画像生成GPT-Image2.0でバナー改善ワークフロー10件
ChatGPT画像生成GPT-Image2.0でバナー改善ワークフロー10件 -
 Meta AI搭載!Ray-Ban Metaスマートグラスの使い方・レビュー
Meta AI搭載!Ray-Ban Metaスマートグラスの使い方・レビュー -
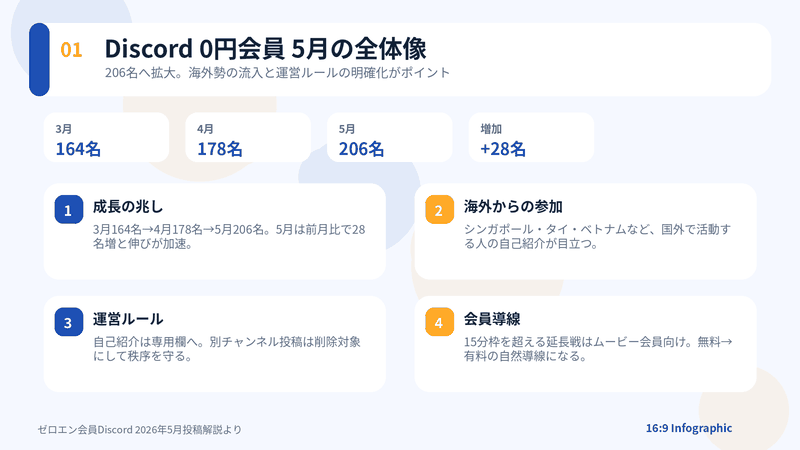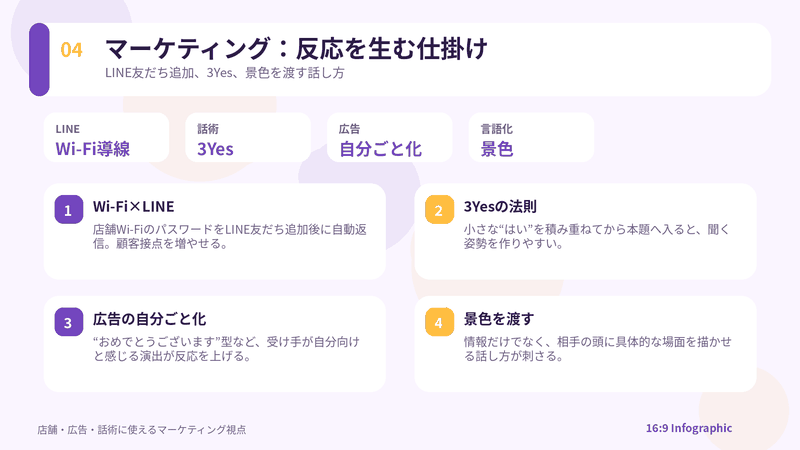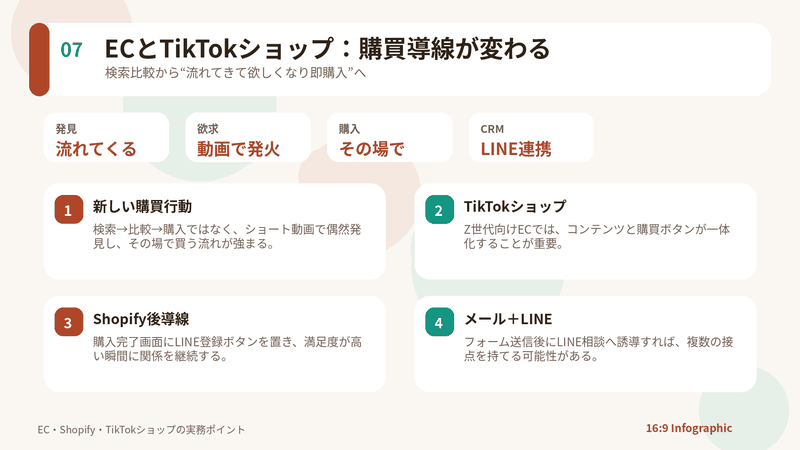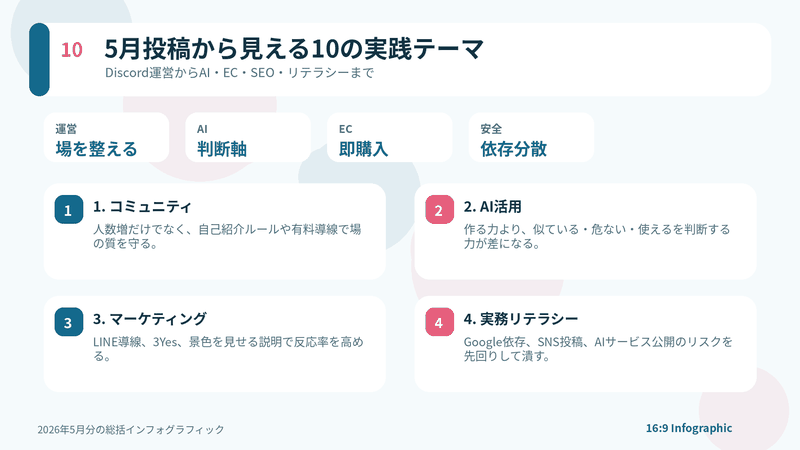 ネットビジネス研究会ゼロエン会員Discord投稿2026年5月分
ネットビジネス研究会ゼロエン会員Discord投稿2026年5月分 -
 ネットビジネス・アナリスト2026年5月ブログ・スライド286枚
ネットビジネス・アナリスト2026年5月ブログ・スライド286枚 -
 AIに関するニュース(2026年5月分)Podcast配信:シャドーAIなど
AIに関するニュース(2026年5月分)Podcast配信:シャドーAIなど -
 『マンガでわかる AI時代の「わたしらしい」デザイン きらりんは答えを知らない: 正解を探さないAI共創ストーリー 本当のわたしは、ずっとここにいる』甲斐智美(ともみん)著
『マンガでわかる AI時代の「わたしらしい」デザイン きらりんは答えを知らない: 正解を探さないAI共創ストーリー 本当のわたしは、ずっとここにいる』甲斐智美(ともみん)著 -
 ChatGPT画像生成GPT-Image2でチラシやバナー画像を作るコツ
ChatGPT画像生成GPT-Image2でチラシやバナー画像を作るコツ -
 ビデオポッドキャスト「AI音楽ラジオ」が2026年6月リニューアル
ビデオポッドキャスト「AI音楽ラジオ」が2026年6月リニューアル
