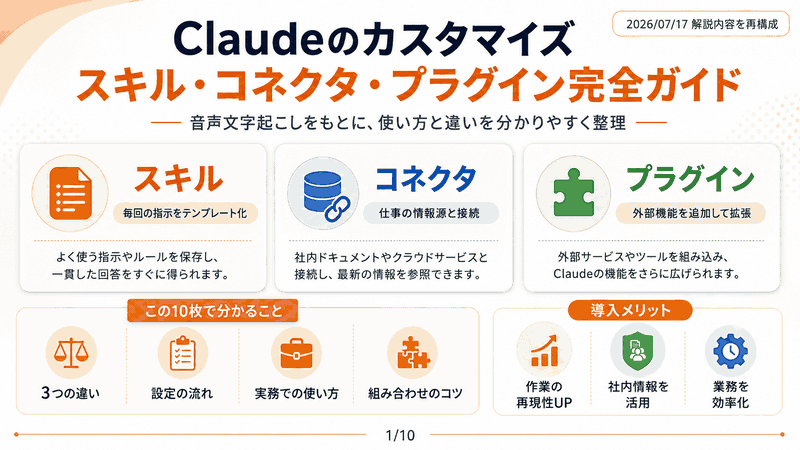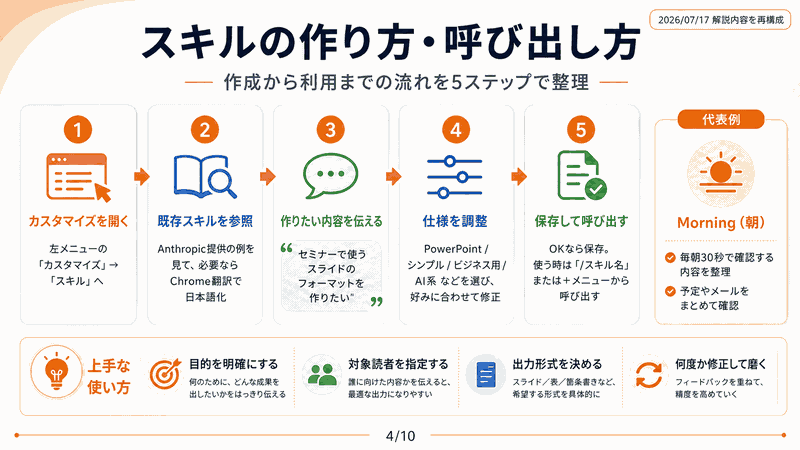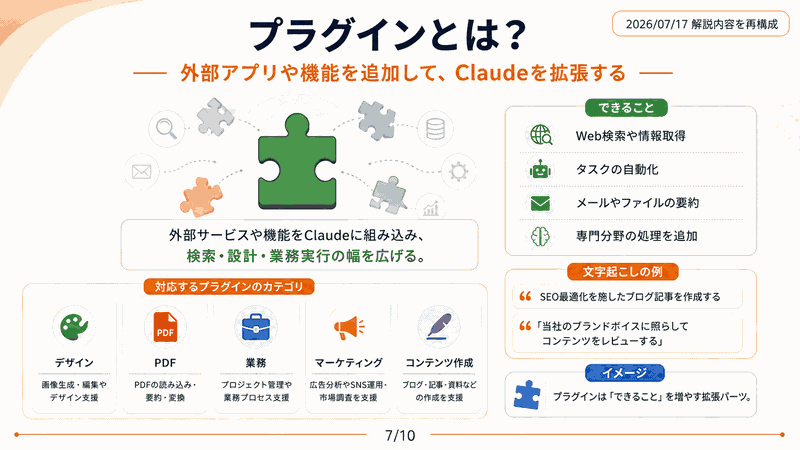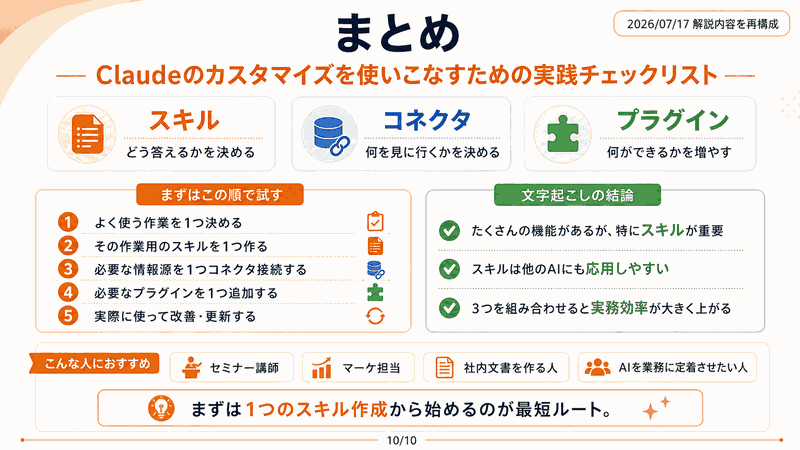
GoogleのGemini 2.5 Flash Image Preview(Nano-Banana)無料

鬼滅も見たい!けどね
この自撮りも合成できるねw
イーンスパイアの横田です。
https://www.enspire.co.jp

さて、本題です。
2025年08月27日、GoogleのGeminiに
超高品質な画像編集AIが無料で搭載!
https://gigazine.net/news/20250827-gemini-2-5-flash-image/
以前にChatGPT GPT Image-1で試したことを
https://chatgpt.com/c/6842b2cd-6dc8-8007-a7cd-5ff948a680ff
今回のGoogle Geminiでも試してみました。
https://gemini.google.com/app/7c4d217ba0a400b1
Xでも話題になっている投稿を参考ください。
https://x.com/search?q=Gemini%202.5%20Flash%20Image&src=typed_query
僕も早速Geminiをレビューしてみました。
https://www.youtube.com/watch?v=1bXBMGKd3jE
Google Gemini 2.5 Flash Image Preview(Nano-Banana)作品集
Google Gemini 2.5 Flash Image Preview(Nano-Banana)に
関する気になるブログ記事やニュースなどを追記します。
https://note.com/it_navi/n/n9a76ccb959c2
Google Gemini 2.5 Flash Image Preview(Nano-Banana)無料
📸 Googleが無料で画像編集AI公開!生成から編集の時代へ進化
🆕 重大発表
📅 2025年8月27日リリース
Google Gemini 2.5 Flash Image Preview
通称「Nano-Banana」が無料で利用開始!
🔑 重要なポイント:
画像生成AIではなく画像編集AI
既存の写真を編集・変換することがメイン機能
画像生成AIではなく画像編集AI
既存の写真を編集・変換することがメイン機能
⚡ ChatGPT vs Google Gemini
ChatGPT 💰
• GPT Image-1使用
• 有料版のみ
• 1日数枚制限
顔の再現性は低め
• GPT Image-1使用
• 有料版のみ
• 1日数枚制限
顔の再現性は低め
Google Gemini 🆓
• 完全無料アカウント
• 1日約50回利用可能
• 顔の再現性が改善
キャラクター継続性に優位
• 完全無料アカウント
• 1日約50回利用可能
• 顔の再現性が改善
キャラクター継続性に優位
⬇️ 実際の検証結果 ⬇️
🧪 検証結果まとめ
- バナー画像の人物差し替え – ChatGPTより似顔絵再現度UP
- 服装変更 – 派手な服への着せ替え成功
- 家具配置 – 空部屋におしゃれ家具を配置完了
- 建物生成 – パンフレットから家を建てるのは失敗
- チラシ作成 – 日本語再現度に課題あり
- ジブリ風変換 – セミナー講師をアニメ化成功
🎭 驚きの新機能:ストーリー継続性
アニメ女の子 + 実写男性
↓
同テイストツーショット
↓
同テイストツーショット
「1時間後をイメージして」
↓
カフェでお茶デート
(女の子が2杯注文😅)
↓
カフェでお茶デート
(女の子が2杯注文😅)
「さらに1時間後を」
↓
女の子がまた1杯追加
男性はケーキ放置
↓
女の子がまた1杯追加
男性はケーキ放置
「その後は?」
↓
ソファで女の子居眠り
なぜか毎回寝る😴
↓
ソファで女の子居眠り
なぜか毎回寝る😴
🎯 これがすごい!
同じキャラクターを維持して連続ストーリーが作れる!
4コマ漫画やアニメ制作への応用可能
同じキャラクターを維持して連続ストーリーが作れる!
4コマ漫画やアニメ制作への応用可能
📋 その他の検証項目
16個LINEスタンプ作成 – 背景透明化は課題
YouTubeサムネイル – アスペクト比16:9対応困難
4コマ漫画生成 – 白黒2×2レイアウト成功
カルーセル投稿 – SVG非対応、PNG可能
✋ 現在の制限事項
🇯🇵 日本語再現度
テキスト入り画像での日本語表示に課題あり
📐 アスペクト比指定
16:9などの縦横比指定が困難、スクエアになりがち
💾 ファイル形式
GIF、SVG形式は非対応
🤖 プロンプト
「画像を作って」の明示的指示が必要
💡 活用アイデア
- 撮影角度変更 – 左から右へ、上からの視点変更
- スタイル変換 – 実写→アニメ→イラスト→漫画
- 色彩変更 – 塗り替え、背景除去
- ファッション – 服装・髪型・ポーズ変更
- 手書き指示 – 手描きメモで直接編集指示
- 商品イメージ – 使用シーン、持ち方変更
🔮 今後の期待
日本語対応強化
テキスト入り画像での日本語再現度向上
テキスト入り画像での日本語再現度向上
アスペクト比対応
16:9、4:3など柔軟な縦横比設定
16:9、4:3など柔軟な縦横比設定
ファイル形式拡張
GIF、SVG、透明PNG完全対応
GIF、SVG、透明PNG完全対応
UI改善
自動画像生成モード実装
自動画像生成モード実装
Google Gemini 2.5 Flash Image Preview(Nano-Banana)無料
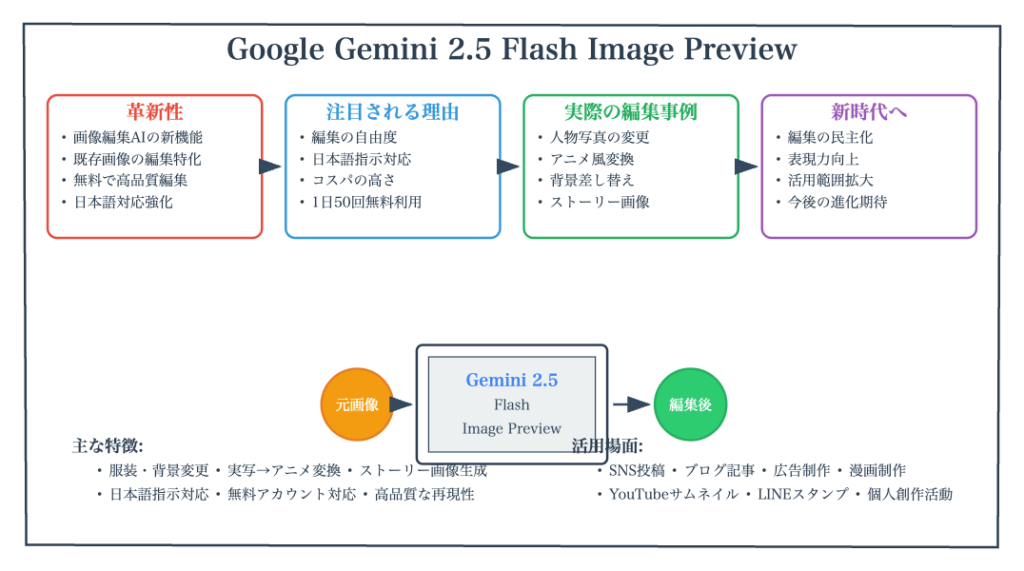
ネットビジネス・アナリスト横田秀珠氏が、2025年8月27日にGoogleがリリースした無料の画像編集AI「Google Gemini 2.5 Flash Image Preview」を紹介。従来の画像生成AIとは異なり、既存の写真を編集できる点が特徴。ChatGPTの画像編集機能と比較検証した結果、顔の再現性はGoogle版が優秀だが、日本語の再現やアスペクト比の指定に課題があることが判明。ストーリー性のある連続画像やアニメ風変換、4コマ漫画作成など多彩な機能を持ち、無料アカウントで1日50回程度利用可能。画像編集AIの新たな可能性を示すツールとして注目される。
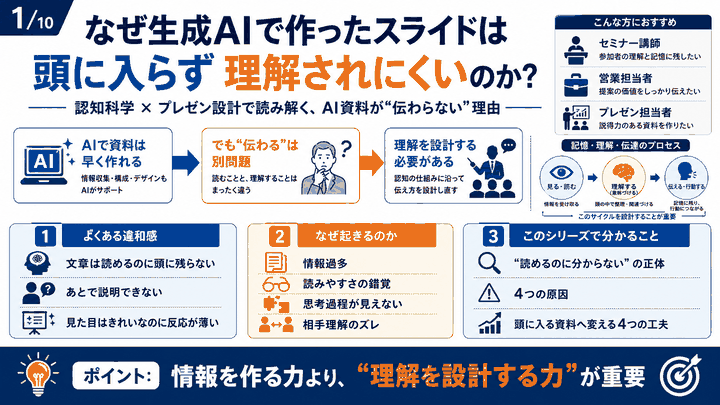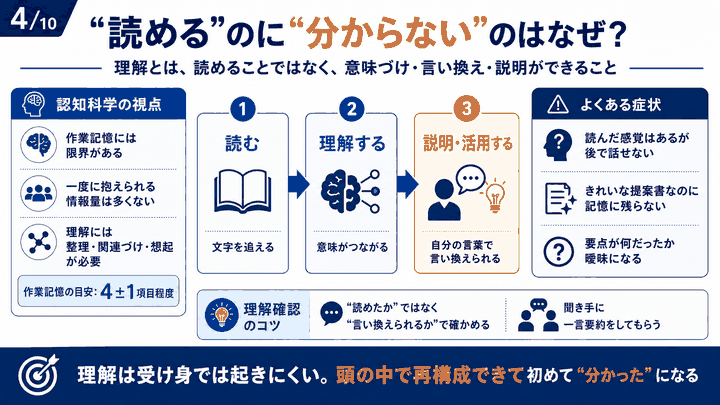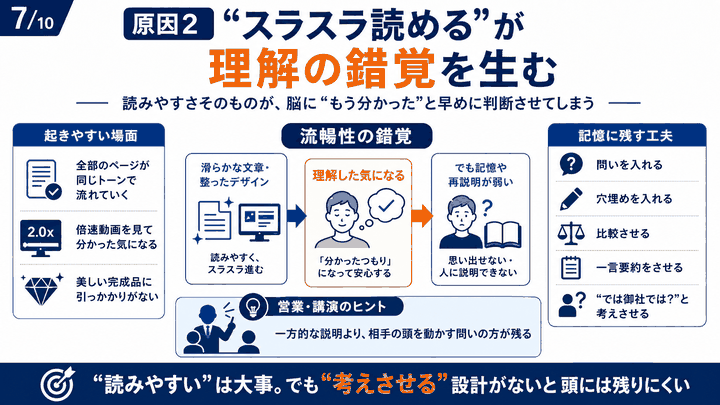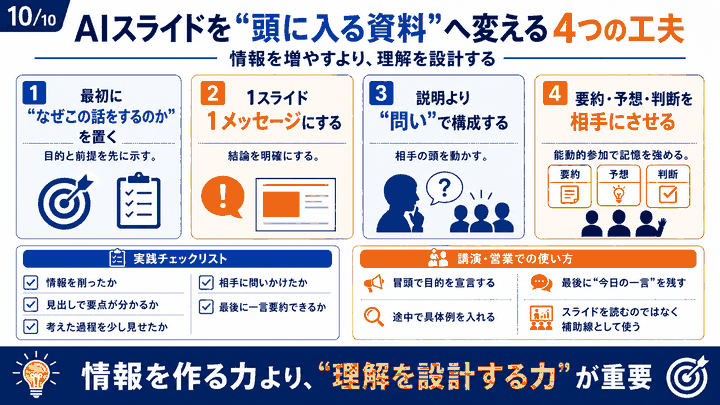
- はじめに
- Google Gemini 2.5 Flash Image Previewとは?画像編集AIの新時代
- ChatGPTとの徹底比較:実際に使って分かった違い
- 驚きの新機能発見!キャラクター一貫性とストーリー生成
- 現実的な課題と今後の可能性を探る
- おわりに
- よくある質問(FAQ)
はじめに
2025年8月、AI画像生成の世界に新たな革命が起こりました。Googleが発表した「Google Gemini 2.5 Flash Image Preview」(愛称:Nano-Banana)は、従来の画像生成AIとは一線を画す「画像編集AI」として注目を集めています。
特に驚くべきは、この高性能なAIツールが完全無料で利用できるという点です。ChatGPTの有料版でも1日数枚の制限があった画像生成が、なんと1日50回程度まで無料で使用可能になったのです。
しかし、「無料だから品質は劣るのでは?」「本当に実用的なのか?」といった疑問をお持ちの方も多いでしょう。本記事では、実際に様々な編集作業を試行し、ChatGPTの画像生成機能と詳細に比較した結果をお伝えします。画像編集AIの新時代の幕開けを、一緒に体験していきましょう。

Google Gemini 2.5 Flash Image Previewとは?画像編集AIの新時代
画像「生成」から「編集」への転換点
2025年8月27日、Googleが発表したこのツールの最大の特徴は、名称にも現れている「画像編集AI」という位置づけです。従来の「画像生成AI」が白紙の状態から新しい画像を作り出すのに対し、このツールは既存の写真や画像を元に、ユーザーの指示に従って編集・変換を行います。
具体的には、以下のような編集が可能です:
- 服装の変更(「この服を浴衣に変えて」)
- 背景の差し替え(「背景を花火大会の会場にして」)
- テイストの変換(「アニメ風にして」)
- ポーズや表情の調整
- 画像の構図変更
無料で利用できる革新性
最も注目すべきは、これらの高度な編集機能が完全無料で提供されていることです。GoogleのGemini無料アカウントがあれば、誰でもすぐに利用開始できます。画面下部の「画像」ボタンをクリックし、編集したい画像をアップロードして指示を入力するだけで、高品質な編集結果を得ることができます。
従来のAI画像生成サービスでは、高品質な出力を得るために月額料金が必要でしたが、この常識を覆す無料提供により、個人クリエイターから企業まで、幅広い層がAI画像編集の恩恵を受けられるようになりました。
技術的な進歩と可能性
Google Gemini 2.5 Flash Image Previewは、単なる画像フィルターツールではありません。深層学習技術を活用し、画像の文脈を理解した上で、自然な編集を実現しています。例えば、人物の顔を別の人物に差し替える際も、元画像の照明条件や角度を考慮し、違和感のない仕上がりを目指します。
また、日本語での指示に対応している点も、日本のユーザーにとって大きなメリットです。「浴衣に変えて」「花火の背景にして」といった自然な日本語で指示を出すことができ、AI画像編集のハードルを大幅に下げています。
ChatGPTとの徹底比較:実際に使って分かった違い
顔の再現性比較実験
両ツールの性能を客観的に評価するため、同じ編集作業を依頼して結果を比較しました。まず、バナー画像の人物を別の人物に差し替える実験では、興味深い結果が得られました。
ChatGPTのGPT-Image1では、顔の特徴が大きく変わってしまい、元の人物との類似性が低い結果となりました。一方、Google Gemini 2.5 Flash Image Previewは、完璧ではないものの、より元の人物に近い顔の再現を実現しました。
特に印象的だったのは、服装変更の実験です。「派手な服を着せて」という指示に対して、ChatGPTでは服は変わるものの顔が別人になってしまうことが多かったのに対し、Googleのツールでは顔の特徴を保ちながら服装の変更に成功するケースが多く見られました。
空間認識と物体配置の精度
家具の配置実験では、両ツールとも一定の成果を示しました。「ガランとした家に家具を配置して、日本人の若い夫婦をリアルな写真で描いて」という複雑な指示に対して、Googleのツールは家具の配置に加えて、自然に寛いでいる夫婦の姿を描写することに成功しました。
しかし、より複雑な建築物の生成では課題も見えました。「空き地にパンフレットの家を建てて」という指示では、両ツールとも期待通りの結果を得ることが困難でした。複数回の試行でも満足のいく結果は得られず、建築物の精密な再現には現時点で限界があることが判明しました。
日本語テキストの処理能力
最も大きな差が現れたのは、日本語テキストの処理能力です。セミナーのチラシ作成実験では、両ツールとも人物写真の合成は比較的成功しましたが、日本語の文字情報の再現では大きな課題が残りました。
Googleのツールは、ChatGPTと比較して日本語の文字配置や読みやすさの面で若干優れた結果を示しましたが、それでも実用レベルには達していません。現状では、日本語テキストが重要な要素となる画像編集では、後からCanvaなどの別ツールで文字を追加する方法が現実的です。
処理速度と利用制限の比較
利用体験の面では、Googleのツールが大きく優位に立っています。ChatGPTの有料版でも1日数枚の制限があるのに対し、Google Gemini 2.5 Flash Image Previewは無料アカウントで1日50回程度の利用が可能とされています。
また、処理速度も比較的高速で、複数の編集作業を連続して行う際のストレスが少ない印象です。これにより、試行錯誤を重ねながら理想的な結果を追求することが容易になります。
驚きの新機能発見!キャラクター一貫性とストーリー生成
革新的なキャラクター一貫性機能
Google Gemini 2.5 Flash Image Previewの最も印象的な機能の一つが、キャラクターの一貫性を保ったまま連続的な画像生成を行えることです。この機能は、ChatGPTの画像生成では実現が困難だった領域です。
実験では、アニメ風の女性キャラクターと実写の男性を組み合わせたツーショット画像から開始しました。「左のイラストに映る女性の横に、次に添付した男性を同じイラストのテイストにしてツーショット写真に変えて」という指示により、見事に統一されたテイストのツーショット画像が生成されました。
ストーリー展開の連続生成
さらに驚くべきは、このツーショット画像を起点として、時系列でのストーリー展開を連続生成できることです。「このツーショットの1時間後をイメージして描いて」という指示により、カフェでお茶をしている場面が生成されました。
興味深い細部として、女性キャラクターが同じドリンクを2つ注文している描写がありました。これは人間的な観点では少し不自然ですが、AIなりの解釈として面白い要素でした。
続けて「さらに1時間後をイメージして描いて」という指示により、ソファーでくつろぐ場面へと展開しました。ただし、この段階でイラストが写真風に変化し、キャラクターも別人になるという課題も発生しました。
テイスト維持の課題と対策
この問題に対して、より具体的な指示「先ほどの写真のテイストのままでさらに1時間後をイメージして描いて」を試したところ、イラストテイストを維持しながら次の場面を生成することに成功しました。カフェでの続きの場面では、女性がさらに別のドリンクを飲み、男性がケーキとコーヒーを楽しんでいる様子が描かれました。
この機能の応用可能性は非常に広く、4コマ漫画の制作、アニメーションの絵コンテ作成、商品紹介のストーリー展開など、様々な用途での活用が期待できます。
実写からアニメへの変換実験
プロフィール写真をジブリ風のアニメキャラクターに変換する実験も行いました。「ジブリ風にしてセミナーの講師をしている様子に変えて」という指示により、確かにジブリ風のテイストでセミナー講師の姿が生成されました。
ただし、元の人物との顔の類似性や、日本語の文字情報の再現には課題が残りました。現段階では、大まかなイメージの変換は可能だが、細部の精度には改善の余地があるという評価が適切です。
4コマ漫画生成の可能性
「やばい買い物をしたのを忘れて、また同じものを買ってしまった」という日常的なシチュエーションを4コマ漫画で表現する実験も実施しました。「4コマ漫画を白黒で、縦2コマ、横2コマの4コマで描いて」という指示により、確かに4コマの構成で漫画が生成されました。
完璧なオチがあるかは別として、基本的な4コマ漫画の構造は理解していることが確認できました。セリフの日本語表示には課題があるため、画像生成後にCanvaなどで文字を追加する手法が現実的です。
現実的な課題と今後の可能性を探る
アスペクト比制御の限界
実用性の観点で重要な課題の一つが、アスペクト比(縦横比)の制御精度です。「16:9で作って」という明確な指示を行っても、多くの場合でスクエア(正方形)の画像が生成されることが確認されました。
この問題は、YouTubeサムネイル作成やブログのカバー画像制作など、特定のアスペクト比が求められる用途において大きな制約となります。現段階では、生成後にトリミングや調整が必要なケースが多いのが実情です。
日本語テキスト表示の課題
最も深刻な課題は、日本語テキストの表示精度です。複数の実験を通じて、以下の問題が確認されました:
- 文字の形状崩れ:ひらがな、カタカナ、漢字の形が正確に表示されない
- レイアウトの問題:文字の配置や行間が不自然になる
- 内容の不一致:指定したテキストと異なる内容が表示される
この課題は、日本語圏でのビジネス利用において大きな障壁となります。チラシ、ポスター、SNS投稿画像など、テキスト情報が重要な用途では、現時点では後処理が必須です。
LINEスタンプ制作の試行結果
「16個のLINEスタンプを作って」という実験では、基本的なスタンプの形状は生成できましたが、以下の課題が明らかになりました:
- 背景透過の問題:「背景を透明にして」という指示に対して、見た目上は透明に見えるものの、実際にはPNG形式での透過画像として出力されない
- セリフ配置の理解不足:LINEスタンプに適したセリフの配置やサイズ感の理解が不十分
- 統一性の課題:16個すべてのスタンプで一貫したキャラクター表現を維持することの難しさ
URL読み込み機能の限界
ブログ記事のURLを指定してカバー画像を作成する実験では、URLの内容を読み込んで要約した画像を生成しようとする姿勢は確認できました。しかし、日本語の内容理解と視覚的な表現への変換には大きな課題が残りました。
また、指定したアスペクト比での出力ができない問題も、この用途では特に重要な制約となります。
手書き指示機能の可能性
一方で、興味深い発見もありました。手書きでの指示や簡単な図解を添付することで、より具体的な編集指示を出せることが確認されました。この機能は、言葉では説明しにくい細かな調整や、レイアウトの指定において有効活用できる可能性があります。
商品画像編集の実用性
商品を使用している場面の画像生成や、商品のイメージ画像作成では、比較的良好な結果が得られました。「商品を持っている写真に変えて」「使っているような感じに変えて」といった指示に対して、自然な合成結果を得ることができ、ECサイトやマーケティング資料での活用可能性を示しています。
今後の改善期待点
現在確認されている課題の多くは、技術的な改善により解決可能と考えられます:
- アスペクト比制御:より正確な縦横比指定機能の実装
- 日本語表示:フォント処理とレイアウト機能の向上
- 透過画像対応:PNG形式での真の透過画像出力
- 精度向上:人物の顔再現性やオブジェクトの配置精度の改善
Googleの技術力と開発速度を考慮すると、これらの課題は段階的に解決されていくことが期待されます。

おわりに
Google Gemini 2.5 Flash Image Previewの登場は、AI画像編集の世界に新たな可能性をもたらしました。無料で提供される高品質な画像編集機能は、個人クリエイターから企業まで、幅広い層に恩恵をもたらしています。
特にキャラクターの一貫性を保った連続画像生成機能は、従来のAI画像生成ツールでは実現困難だった領域を開拓しており、4コマ漫画制作やストーリーボード作成など、新しいクリエイティブワークフローの創出につながる可能性を秘めています。
一方で、日本語テキストの表示精度やアスペクト比制御など、実用面での課題も明確になりました。これらは現時点での限界として理解し、他のツールとの組み合わせによって補完していくことが現実的なアプローチです。
重要なのは、この技術が急速に進歩していることです。現在の課題の多くは技術的な改善により解決可能であり、定期的に新機能や改善がリリースされることが予想されます。無料で利用できる今のうちに、様々な用途での活用方法を探り、将来的な本格活用に備えることをお勧めします。
AI画像編集の新時代は始まったばかりです。今後の技術進歩に注目しながら、創造性を活かした新しい表現方法を模索していきましょう。
よくある質問(FAQ)
Q1: Google Gemini 2.5 Flash Image Previewは完全無料で使えるのですか?
A: はい、Googleの無料アカウントがあれば追加料金なしで利用できます。1日約50回程度の利用が可能とされており、ChatGPTの有料版と比較しても非常に優遇された利用条件となっています。ただし、利用回数の上限は変更される可能性があるため、最新の情報をGoogleの公式サイトで確認することをお勧めします。
Q2: ChatGPTの画像生成機能と比べて、どちらが優秀ですか?
A: 用途により異なりますが、顔の再現性とキャラクターの一貫性保持においてはGoogle Gemini 2.5 Flash Image Previewが優位性を示しています。特に連続的なストーリー展開を含む画像生成では、Googleのツールが大きく勝っています。一方、細部の精密性や一部の生成品質では、ChatGPTが優れている場面もあります。無料で利用できる点を考慮すると、Googleのツールは非常にコストパフォーマンスが高いと言えます。
Q3: 日本語のテキストが含まれる画像は正確に作れますか?
A: 現時点では日本語テキストの正確な表示には大きな課題があります。文字の形状が崩れたり、指定したテキストと異なる内容が表示されることが多くあります。そのため、日本語テキストが重要な画像を作成する場合は、AI生成後にCanvaやPhotoshopなどの別ツールで文字を追加する方法が現実的です。この課題は今後の技術改善により解決される可能性が高いと考えられます。
Q4: 商用利用は可能ですか?また、著作権はどうなりますか?
A: GoogleのGemini利用規約に従って商用利用が可能です。ただし、生成された画像の著作権については、入力した元画像の権利状況や生成内容により複雑な問題となる場合があります。特に人物写真を使用する場合は肖像権、他者の著作物を含む場合は著作権の問題が発生する可能性があります。商用利用の前には、必ずGoogleの最新の利用規約を確認し、必要に応じて法的専門家に相談することをお勧めします。
Q5: スマートフォンでも利用できますか?操作方法は簡単ですか?
A: はい、スマートフォンのブラウザからGoogleのGeminiにアクセスすることで利用可能です。操作方法も非常にシンプルで、画面下部の「画像」ボタンをタップし、編集したい画像をアップロードして日本語で指示を入力するだけです。特別なアプリのインストールは不要で、Googleアカウントがあればすぐに始められます。ただし、細かい編集作業や結果の確認には、パソコンの大画面の方が適している場合が多いです。
詳しくは15分の動画で解説しました。
https://www.youtube.com/watch?v=GDjfAO3S9Co

0:00 📱 導入・Google Gemini 2.5 Flash Image Preview紹介
0:45 📰 ニュース解説・画像編集AIの特徴
1:54 🔍 ChatGPTとの比較・過去事例の振り返り
2:57 🎨 実際の検証開始・基本的な画像生成機能
4:06 ✨ Google独自機能・イラスト連携とストーリー生成
6:21 📚 連続画像生成・漫画アニメ制作の可能性
7:26 🎤 セミナー講演画像変換・顔再現性の課題
8:37 💌 ラインスタンプ制作・背景透明化検証
9:38 📝 ブログカバー作成・アスペクト比の問題
10:44 📺 YouTubeサムネイル作成・日本語再現の限界
11:46 🎭 4コマ漫画・Instagram投稿用画像作成
12:55 💡 総合的な活用方法・追加機能の紹介
14:01 🏁 まとめ・ChatGPTとの比較総評
上記の動画はYouTubeメンバーシップのみ
公開しています。詳しくは以下をご覧ください。
https://yokotashurin.com/youtube/membership.html
YouTubeメンバーシップ申込こちら↓
https://www.youtube.com/channel/UCXHCC1WbbF3jPnL1JdRWWNA/join
Google Gemini 2.5 Flash Image Preview(Nano-Banana)無料
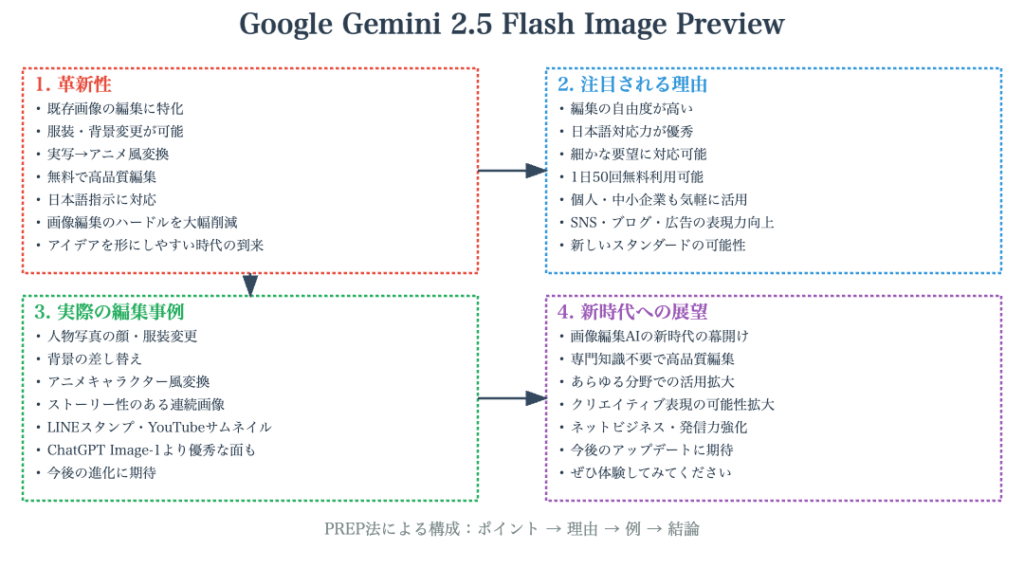
🤖 Google Gemini 2.5 Flash Image Preview Googleが2025年8月にリリースした画像編集AI。従来の画像生成AIとは異なり、既存の写真や画像を指示に従って編集・変換できる機能を持つ。無料で利用でき、様々な画像処理が可能な革新的なツール。
🎨 画像編集AI 従来の画像生成AIとは異なり、既存の画像を元に編集や変換を行うAI技術。服装の変更、背景の変更、アニメ風変換、ポーズ変更など多岐にわたる編集機能を持ち、クリエイティブな作業を支援する。
💰 無料 Google Gemini 2.5 Flash Image Previewは無料アカウントで利用可能。ChatGPTが1日数枚の制限があるのに対し、1日50回程度の使用が可能とされ、コストパフォーマンスに優れた画像編集ツール。
⚔️ ChatGPT比較 ChatGPTのImage-1機能との性能比較検証。顔の再現性ではGoogle版が優秀だが、日本語の文字再現性やアスペクト比の指定精度では課題があることが実証され、それぞれに得意分野がある。
👤 顔の再現性 元の人物の顔を保持しながら画像を編集する能力。Google版はChatGPTより優秀だが、完全な再現は困難で、時々別人になってしまう課題がある。人物を含む画像編集の重要な評価指標。
🇯🇵 日本語再現 画像内の日本語テキストの再現能力。現在のGoogle Gemini 2.5 Flash Image Previewでは日本語の正確な再現が困難で、文字化けや不正確な表示が頻発し、実用性に課題がある分野。
📚 ストーリー性 一つのキャラクターを一貫して保持しながら連続的な場面を作成する能力。デートの流れを時系列で描くなど、漫画やアニメ制作に応用できる革新的な機能で、ChatGPTでは困難な連続性を実現。
🎭 アニメ風変換 実写写真をアニメやイラスト調に変換する機能。ジブリ風への変換も可能で、写真を様々なテイストのイラストに変換できる。クリエイティブな表現の幅を大きく広げる機能の一つ。
📖 4コマ漫画 指定されたテーマで4コマ漫画形式の画像を自動生成する機能。縦2コマ×横2コマの形式で作成可能。セリフは後から追加する必要があるが、漫画のストーリー構成を自動化できる画期的な機能。
📐 アスペクト比 画像の縦横比の指定機能。16:9などの特定の比率を指定しても、実際にはスクエア(正方形)になることが多く、YouTube用サムネイルやInstagram投稿用画像作成では改善が必要な課題領域。
超要約1分ショート動画こちら↓
https://www.youtube.com/shorts/AG05T5p-m44

Google Gemini 2.5 Flash Image Preview(Nano-Banana)無料
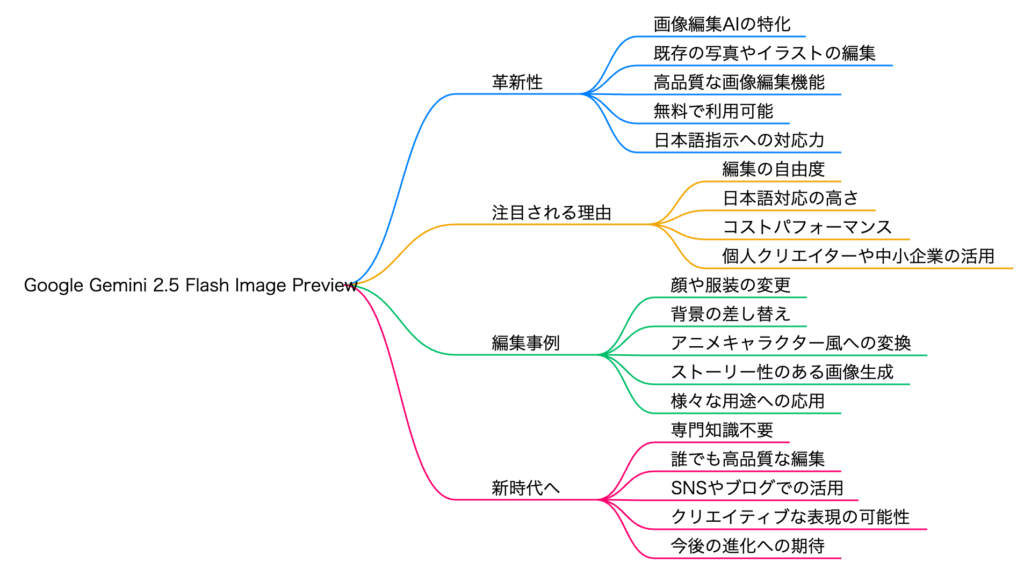
Googleの最新AIモデル「Gemini 2.5 Flash Image Preview」(通称Nano-Banana)は、従来の画像生成AIの枠を超え、高度な画像編集と一貫性維持に特化した画期的なモデルです。その中核をなすのは、マルチモーダルな推論能力、プロンプトベースの精密なターゲット編集、複数の画像を統合する融合機能、そして単一の被写体の外見を保つキャラクターの一貫性維持機能です 。
本モデルは、低レイテンシ・高スループットを特徴とするGemini 2.5 Flashシリーズの一部であり、その高速性(約120k px/sec)は、競合モデル(GPT-4o/GPT Image 1の約30k px/sec)と比較して際立っています 。この速度と、自然言語による編集の精度、そして特にキャラクターの一貫性維持能力において、現行の主要な画像編集モデルの性能を凌駕していると評価されています 。
しかし、まだプレビュー段階であるため、いくつかの課題も存在します。特に、抽象的な芸術様式へのスタイル変換や、日本語を含む画像内テキストの正確なレンダリングには、まだ改善の余地が見られます 。
総合的に見て、本モデルは単なる画像生成ツールではなく、Googleの広範なエコシステム(Gemini API、Vertex AI)に深く統合された、より高度なビジュアルAIソリューションとしての戦略的価値を確立しています。これにより、開発者は迅速なプロトタイプ作成から本番環境でのエンタープライズ利用まで、一貫したAIワークフローを構築することが可能となります 。
第1部: Gemini 2.5 Flash Image (Nano-Banana) の概要と技術的背景
1.1. モデルの技術的背景と位置付け
Gemini 2.5 Flash Imageは、Googleが開発したAIモデルのスイートであるGemini 2.5シリーズの中でも、特に高速性とコスト効率を追求した「Flash」モデルの画像特化版です 。その応答速度は、1秒間に約120,000ピクセルを処理できるとされており、これは他の主要なモデル(例:GPT-4o)の約4倍にあたる速度です 。この高速性は、リアルタイム性が求められるアプリケーションや、大量の画像を処理する商業的ユースケースにおいて大きな利点をもたらします 。
このモデルの中核をなす技術的特徴は以下の4点に集約されます。
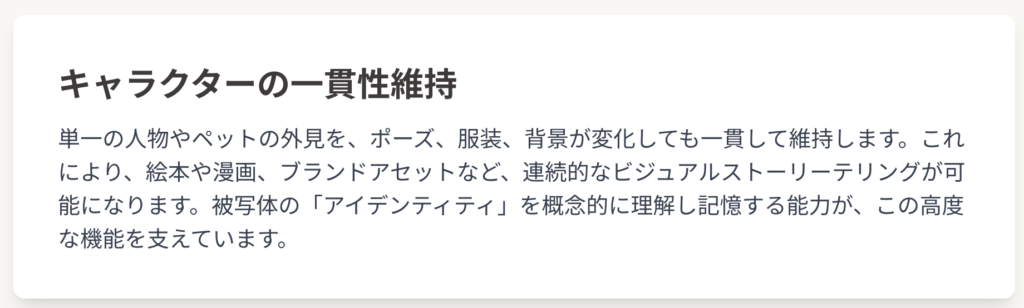
- キャラクターの一貫性維持: 単一の人物やペットの外見を、ポーズ、服装、背景といった環境が変化しても一貫して維持する能力を備えています。この機能は、絵本や漫画、あるいは企業のブランドアセットなど、連続的なビジュアルストーリーテリングを必要とする場面で極めて重要な役割を果たします 。
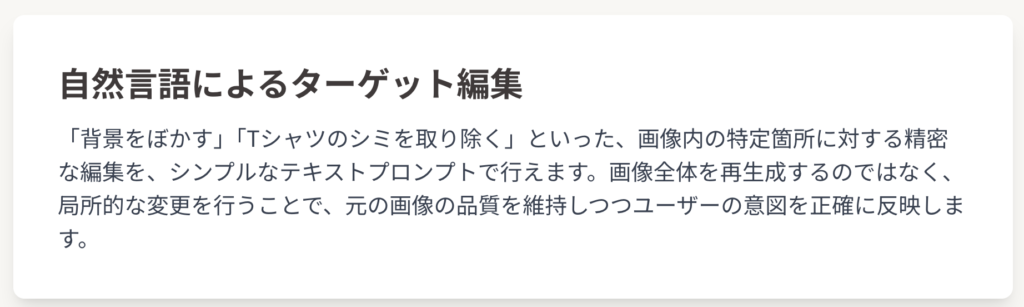
- 自然言語によるターゲット編集: 「背景をぼかす」「Tシャツのシミを取り除く」「人物のポーズを変える」といった、画像内の特定の箇所に対する精密な編集を、複雑なUI操作ではなく、シンプルなテキストプロンプトで行うことができます 。
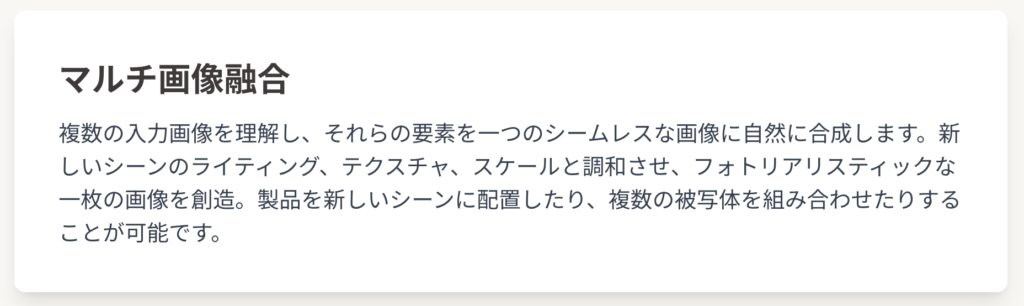
- マルチ画像融合: 複数の入力画像を理解し、それらの要素を一つのシームレスな画像に自然に合成する機能です。これにより、製品を新しいシーンに配置したり、複数の被写体を組み合わせて新しい構図を作成したりすることが可能になります 。
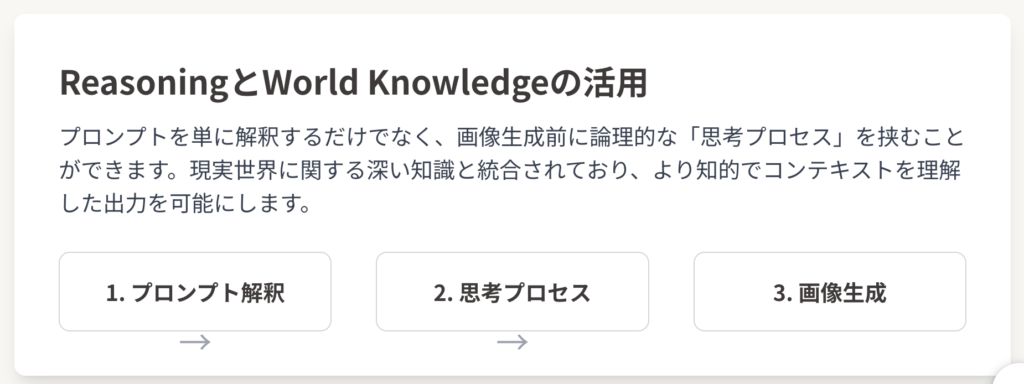
- ReasoningとWorld Knowledgeの活用: Gemini 2.5 Flashは、プロンプトを単に解釈するだけでなく、画像生成前に論理的な「思考プロセス」を挟むことができます。また、現実世界に関する深い知識を統合しており、手描きの図形を読み取って複雑な編集指示に従うなど、単なる美的な画像生成を超えた、より知的でコンテキストを理解した出力を可能にしています 。
1.2. 提供形態と利用コスト
Gemini 2.5 Flash Imageは、開発者や企業向けにGoogle AI Studio、Vertex AI、そしてGemini APIを介して提供されています 。これにより、迅速な実験やプロトタイプ開発から、本番環境での大規模なアプリケーションへの統合まで、多様な開発ニーズに応えることができます。個人ユーザー向けには、Geminiアプリに画像編集機能として統合されており、誰もが手軽にその機能を利用することが可能です 。
料金体系については、100万出力トークンあたり30.00に設定されており、画像1枚あたり1290出力トークン(約0.039)として計算されます 。これは、開発者にとってコスト効率の高い選択肢となります 。
また、開発者向けには、画像データをAPIリクエストに直接含める「インラインデータ」形式と、大きなファイルや再利用する画像向けに効率的な「File API」を介してアップロードする形式が提供されており、ワークフローに応じて選択できます 。
第2部: 主要機能と実証事例の徹底分析
以下に、ユーザーから提示された検証項目を網羅し、各機能の具体的な活用事例と、その背後にある技術的特性を詳細に分析します。
表1: Gemini 2.5 Flash Imageの主要機能と検証事例一覧
| 検証項目 | 該当セクション | 調査結果の概要 |
| ポーズ・表情・服装・背景の変更 | 2.1 | 顔の雰囲気を維持したまま服装やポーズを自然に変更可能。 |
| ストーリーボード作成 | 2.2 | 複数コマでキャラクターの一貫性を維持。ただし、テキストレンダリングに課題。 |
| イラストの線画抽出 | 2.5 | 既存画像を線画に変換可能。 |
| 線画の着色 | 2.5 | 線画を任意のスタイルや色で再着色可能。 |
| ラフの線画化 | 2.5 | ラフスケッチから線画を生成可能。 |
| 複数画像による指示 | 2.4 | 複数の画像を融合し、新しい構図やシーンを創造。 |
| 実写背景との合成 | 2.4 | 人物や物を実写背景に自然に配置可能。 |
| 消しゴムマジック | 2.3 | 不要な人物や物体を自然に削除可能。影の削除にも対応。 |
| 写真を漫画調・アニメ調に変換 | 2.5 | 特定のスタイルやテクスチャの適用は得意だが、抽象的なスタイル転送は苦手。 |
| 時間帯やカメラ角度の変更 | 2.6 | 「斜め上45度」などの指示で視点を変更可能。 |
| 2コマ漫画生成 | 2.2 | キャラクターの一貫性を維持しつつ、視覚的なストーリーを生成。 |
2.1. 画像編集の核心:ポーズ・表情・服装・背景の変更
Gemini 2.5 Flash Imageは、被写体の外見を一貫して保ちながら、その状況を自在に変化させる能力において、特に優れています。 例えば、人物の顔の雰囲気を維持したまま、「ビジネススーツに変えて」や「腕を組んだポーズに」といった指示を与えるだけで、衣服の質感やシワ、そして手や腕のバランスが自然に再現された画像を生成できます 。また、元の画像に全身が写っていなくても、「ピースサインをしてください」という具体的なポーズの指示で、リアルな全身像を生成することも可能です 。
背景の変更に関しても、既存の部屋の壁紙を新しいものに変えたり、人物を世界のどこにでも配置したりすることができます 。
これらの編集が自然に行われる背景には、モデルが単なるピクセル操作を超え、被写体の「アイデンティティ」を概念的に理解し記憶する能力が働いています 。これは、本モデルの「キャラクターの一貫性維持」機能が、高度なビジュアル編集タスクにおいて、被写体の物理的特徴が崩れることを防ぐ直接的な要因となっています。この能力は、ユーザーが同一の被写体を異なる状況で再利用することを可能にし、クリエイティブなワークフローを劇的に効率化します 。
2.2. ストーリーテリングの可能性:漫画・ストーリーボードの生成
本モデルは、連続したビジュアルコンテンツを生成する能力に長けており、ストーリーテリングに不可欠な機能を提供します 。開発者向けドキュメントには、キャラクターの一貫性とシーンの説明に基づいて、コミックパネルやストーリーボードを作成するためのテンプレートプロンプトが記載されています 。
実際に、「翻訳者とAI」というテーマで4コマ漫画を生成した検証事例では、各コマでキャラクターの外見が一貫して維持される点が特に高く評価されています 。この能力は、絵本や漫画、広告キャンペーンのキャラクター制作において絶大な効果を発揮します 。
しかし、同じ検証事例は、モデルの出力における重大な課題も同時に示しています。キャラクターの見た目は一貫している一方で、日本語のテキストレンダリングが「判読不能」であるという結果が報告されています 。これは、モデルが視覚的なコンテキストは理解できても、文字情報の正確な生成にはまだ課題があることを明確に示しています。Redditのユーザーレビューでも同様に、テキストレンダリングの精度は競合モデルであるGPT Image 1に劣るという指摘がなされています 。
興味深いことに、同じプロンプトでも、日本語版と英語版で生成される漫画のスタイルやキャラクターの表情に違いが見られるという観察結果もあります 。これは、モデルが訓練データを通じて特定の言語圏の文化的・視覚的表現を学習している可能性を示唆しており、将来的にローカライズされたクリエイティブ生成の可能性を秘めていると考えられます。
2.3. スマート編集機能:「消しゴムマジック」と局所的編集
Gemini 2.5 Flash Imageは、Google Pixelの「消しゴムマジック」機能と同様の、不要な物体や人物を画像から違和感なく削除する能力を持っています。写真に写り込んだ人物や影、あるいは邪魔なコップなどを、背景に自然に溶け込ませて消去することが可能です 。
この機能は、単に「オブジェクトを削除する」というシンプルな操作を、より柔軟な自然言語プロンプトで実現している点に特徴があります。これにより、ユーザーは「この人を消して」だけでなく、「この人物の影だけを消して」といった、より細かな指示を出すことができ、編集の自由度が向上します 。
この機能が優れているのは、画像全体を再生成するのではなく、局所的な変更を行うことで、元の画像の品質を維持しつつ、ユーザーの意図を正確に反映できる点です。これは、DALL-Eのような「テキストから画像を生成する」モデルとは異なる、Gemini 2.5 Flash Imageの強力な差別化要因の一つです 。
2.4. 複数画像の融合と新構図の創造
本モデルは、複数の入力画像を理解し、それらの要素を一つの新しい画像に統合する「マルチ画像融合」機能を備えています 。これは単なる切り貼りやコラージュとは一線を画すもので、入力された複数の被写体の要素を、新しいシーンのライティング、テクスチャ、スケールと調和させて、フォトリアリスティックな一枚の画像に合成します 。
例えば、自身の写真と飼い犬の写真をアップロードし、「バスケットボールコートに二人を配置したポートレートを作成して」と指示することで、二人を同じシーンに自然に融合させることが可能です 。また、空の部屋の画像に、別の画像にあるソファを追加するインテリアデザインの事例も示されており、被写体が新しい環境に論理的に配置されることが確認されています 。
このような高度な合成能力は、モデルが画像内の要素とその意味論的な関係を深く理解していることを示しています。複数の要素を調和させるためには、「この人物は背景に比べてこのサイズが自然だ」「このソファはこの壁に沿って配置すべきだ」といった論理的な推論が行われていると考えられます。これは、第1部で言及した、モデルが持つ「思考プロセス」が、高度なクリエイティブタスクに具体的に応用されている証拠と言えるでしょう 。
2.5. 線画の抽出・着色とスタイル変換
本モデルは、既存の画像を線画に変換し、さらにその線画を着色するといった多段階の変換にも対応しています 。これは、クリエイティブなプロセスの初期段階を効率化する上で有用です。
しかし、「写真から漫画・アニメ調に変換する」といったスタイル変換機能については、ユーザーの検証事例と公式の主張との間に乖離が見られます。公式発表では、ある画像から色やテクスチャを抽出し、別の画像に適用する「デザインミックス」機能やスタイル適応機能が紹介されています 。
一方で、Redditでのユーザーレビューでは、抽象的な芸術様式(例えば「水彩画」)へのスタイル転送は非常に苦手であり、この点においては旧モデルであるGemini 2.0 Flash Imageの方が優れているという明確な指摘がなされています 。
この乖離は、「スタイル変換」という言葉に、比較的単純な「テクスチャや色の適用」と、複雑な「芸術様式全体の模倣」という二つの意味合いが含まれていることを示唆しています。Gemini 2.5 Flash Imageは前者には優れているものの、後者は不得意である可能性が高いです。その理由の一つとして、本モデルがフォトリアリズムと一貫性を重視して設計されているため、抽象的な表現やテクスチャのドリフトを意図的に抑制している可能性が考えられます。これは、写実的な編集には有利に働く一方で、スタイル転送のようなタスクでは、モデルの「思考」が創造性を妨げる結果につながる、一種の技術的なトレードオフと言えます。
2.6. カメラアングルや時間帯の変更
Gemini 2.5 Flash Imageは、画像内のシーンの三次元的な配置を理解していることを示唆する機能を提供しています。例えば、「斜め上45度から」といった指示で、元画像の視点を自然に変更することが可能です 。
この能力は、単なる2次元的なピクセル操作を超えた、モデルの空間理解の深さを示しています。これにより、単一のテキストプロンプトから、製品を様々な角度から撮影したかのような画像を生成できるため、製品カタログの作成や建築ビジュアライゼーションなど、現実世界での具体的な応用例が広がります。これにより、高価な撮影や3Dモデリングのコストを大幅に削減できる可能性を秘めています 。
第3部: Gemini 2.5 Flash Imageの優位性と限界
3.1. 主要AI画像生成モデルの比較
以下の表は、Gemini 2.5 Flash Image Previewを市場の主要な競合モデルと客観的に比較したものです。
| 項目 | Gemini 2.5 Flash Image Preview (Nano-Banana) | Gemini 2.0 Flash Image | ChatGPT-4o / GPT Image 1 | Flux Kontext [max] | Qwen Image Edit |
| 総合評価 (ELO) | 1150–1350 (最高) | ~990–1080 (最低) | ~1120–1180 | ~1050–1170 | ~1150 |
| 写実性 | フォトリアリスティック、コンテキスト認識 | 詳細が限られ、平坦な出力 | 良いが、一貫性に欠ける | 写実的だが、時折ドリフト | 写実的だが、不安定 |
| キャラクターの一貫性 | 最強 – 複数の編集にわたって同一性を維持 | 弱い – 頻繁にドリフト | 中程度 – 時々ドリフト | スタイルドリフトが一般的 | 顔が一貫しない |
| 編集精度 | 自然言語による細かい局所編集が可能 | 基本的な編集のみ | 良いが、精度が低い | 大まかな編集、ニュアンスに欠ける | 精度が限られる |
| 世界知識 | Google DeepMindの推論と深く統合 | 限られる | 中程度 | 弱い | 弱い |
| テキスト描画 | 61.1% (バランス) | 72.7% (最高) | 71.80% | 59.70% | 68.50% |
| 速度 / レイテンシ | ~120k px/sec (高速かつバランス) | ~175k px/sec (最速) | ~30k px/sec (遅い) | ~70k px/sec (中程度) | ~90k px/sec (高速、精度は低い) |
| 本表が示すように、Gemini 2.5 Flash Imageは、ユーザーの総合的な評価においてトップクラスに位置づけられています 。特に、「キャラクターの一貫性」と「編集精度」においては、他の追随を許さない強みを持っています。これは、従来の画像生成モデルが抱えていた、被写体の見た目が安定しないという根本的な課題を解決するものです。 |
一方で、データはモデルの設計思想に由来するトレードオフも示しています。例えば、「テキストレンダリング」の精度はGPT Image 1に劣るという定量的なデータが存在します 。これは、モデルが写実性と一貫性を重視するあまり、文字の正確な描画といった特定の分野で弱点となる可能性があることを示唆しています。
3.2. モデル独自の強み:ReasoningとWorld Knowledge
他の主要な画像生成モデルがプロンプトを単に解釈し、パターンを再現する傾向があるのに対し、Gemini 2.5 Flash Imageは生成前に「思考プロセス」を挟むことができます 。この能力により、モデルはユーザーの要求をより深く理解し、非論理的な出力(”nonsense outputs”)を減少させ、出力の信頼性を向上させます 。
また、本モデルは「世界の知識」を統合しており、画像生成を超えた応用例も可能にしています。例えば、手描きのダイアグラムを読み取り、それに関する質問に回答したり、複雑な編集指示を単一のステップで実行したりする教育ツールの事例が示されています 。これは、モデルが単なる美的な画像を生成するだけでなく、意味論的なコンテキストを深く理解し、現実世界の問題を解決するための基盤を持っていることを示しています。
3.3. 運用上の課題と「うまくいかないこと」の総括
本モデルは非常に強力ですが、現時点での運用にはいくつかの課題も存在します。
- 文字の描画: 日本語や細かい文字は判読不能になることが多く、特に漫画の吹き出しなど、正確なテキスト表示が求められるユースケースには適していません 。
- スタイル変換: 抽象的な芸術様式へのスタイル転送は苦手であり、旧モデルの方が優れていたという検証結果も存在します 。
- キャラクタードリフト: 複数回の編集を重ねることで、顔のディテールがわずかに歪む「キャラクタードリフト」がまだ残る場合があります 。
- 「世界の知識」の限界: 全ての概念を完璧に理解しているわけではなく、「チェス盤の初期配置」といった特定の概念を誤って解釈する事例も報告されています 。
- 一時的な不具合: サービスが一時的に過負荷になったり、容量が不足したりすると、画像生成に失敗することがあります 。これに対する対策として、別のモデルに切り替えたり、時間を空けて再試行したり、より明確な指示を与えるといった手法が推奨されます 。
第4部: まとめと今後の展望
4.1. 主要な所見の総括
本レポートの分析から、Gemini 2.5 Flash Imageは、**「編集」と「一貫性維持」という二つの領域において、既存の主要モデルを凌駕する強力なツールであると結論付けられます。その中核にあるのは、画像生成・編集の精度と信頼性を高める「Reasoning」と「World Knowledge」**という独自の技術的基盤です。これにより、単なるテキストからの画像生成だけでなく、既存の画像に対する高度な操作や、複数の画像を組み合わせた新しいクリエイティブなワークフローを可能にしています。
しかし、**「文字描画」や「抽象的なスタイル変換」**といった特定の機能にはまだ明確な課題が残っており、モデルの設計思想が生み出す技術的なトレードオフも存在します。
4.2. ロードマップと提言
本モデルはまだ「プレビュー」段階であり、今後数週間で「stable(安定版)」となる予定です 。Google AI Studioの「build mode」も継続的にアップデートされるとされており、機能の安定性と進化が期待されます 。
このモデルが開発者、クリエイター、および事業責任者にもたらす価値は非常に大きいと見なされます。特に以下のような用途では、本モデルの活用を強く推奨します。
- キャラクターの一貫性を必要とするシリーズコンテンツやブランドアセットの作成。
- インタラクティブな編集アプリやビジュアルを用いた教育ツールなど、APIと統合した新しいアプリケーション開発。
- マルチモーダルなワークフロー(テキストと画像が連携する)を前提としたプロジェクトにおいて、Gemini APIの統一されたエコシステムは、開発効率とコストパフォーマンスの点で大きな利点となります 。
一方で、複雑な芸術作品の生成や、画像内に正確なテキストを含める必要がある場合には、現時点では他のモデルや手動での修正を組み合わせるハイブリッドなアプローチが現実的です。モデルが安定版としてリリースされ、さらなる改善が進むにつれて、その応用範囲は今後さらに拡大していくと考えられます。
#画像編集AI #Geminit #横田秀珠 #Geminitセミナー #Geminitコンサルタント #Geminit講座 #Geminit講習 #Geminit講演 #Geminit講師 #Geminit研修 #Geminit勉強会 #Geminit講習会