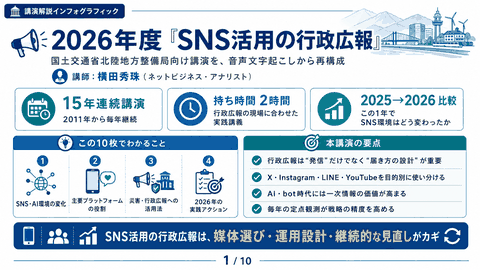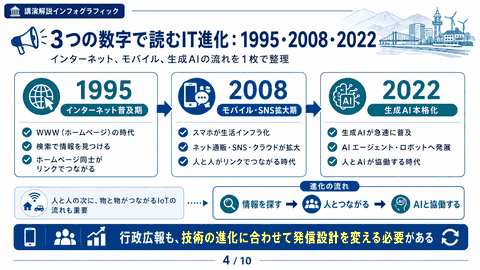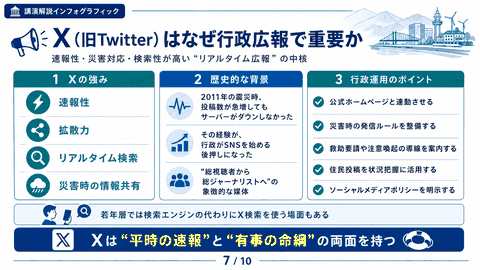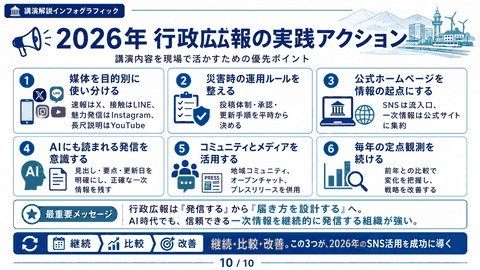
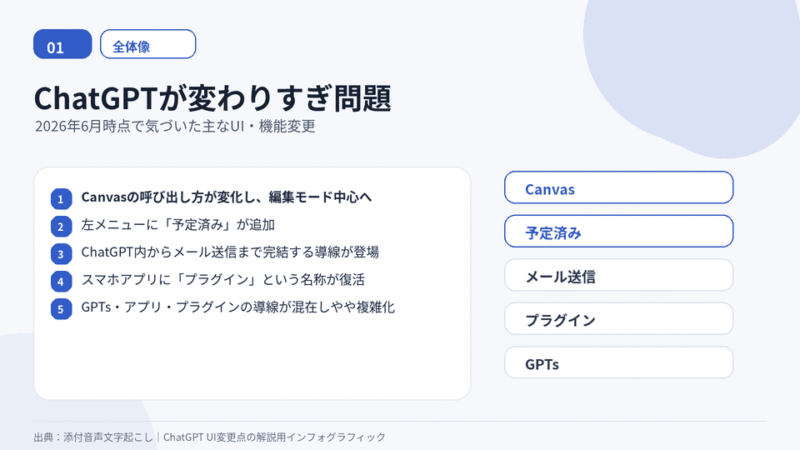
検索エンジン・SNS・LLM(生成AI)×得意・苦手マトリックス分析

こないだの電車メシです(笑)
新幹線でご飯を食べる男(汗)
イーンスパイアの横田です。
https://www.enspire.co.jp

新潟から1合ずつ小分けした袋から米を、
焼津商工会議所に講演用で頂いた水を
セットして名古屋から新神戸あたりの
新幹線で炊飯し(笑)、岡山駅の1階
スーパーで刺身2点を買いマイ醤油と
共に頂きました。
さて、本題です。
ChatGPTが普及した未来、プログラマーに求められることとは? 生成AIの普及と落とし穴
https://codezine.jp/article/detail/19166?p=3
という記事が面白かったので紹介します。
プログラマー視点で考えると
プロンプトエンジニアリングは
簡単かもしれないって話です。
https://www.youtube.com/watch?v=iNR536CzLA0
検索エンジン・SNS・LLM(生成AI)×得意・苦手マトリックス分析
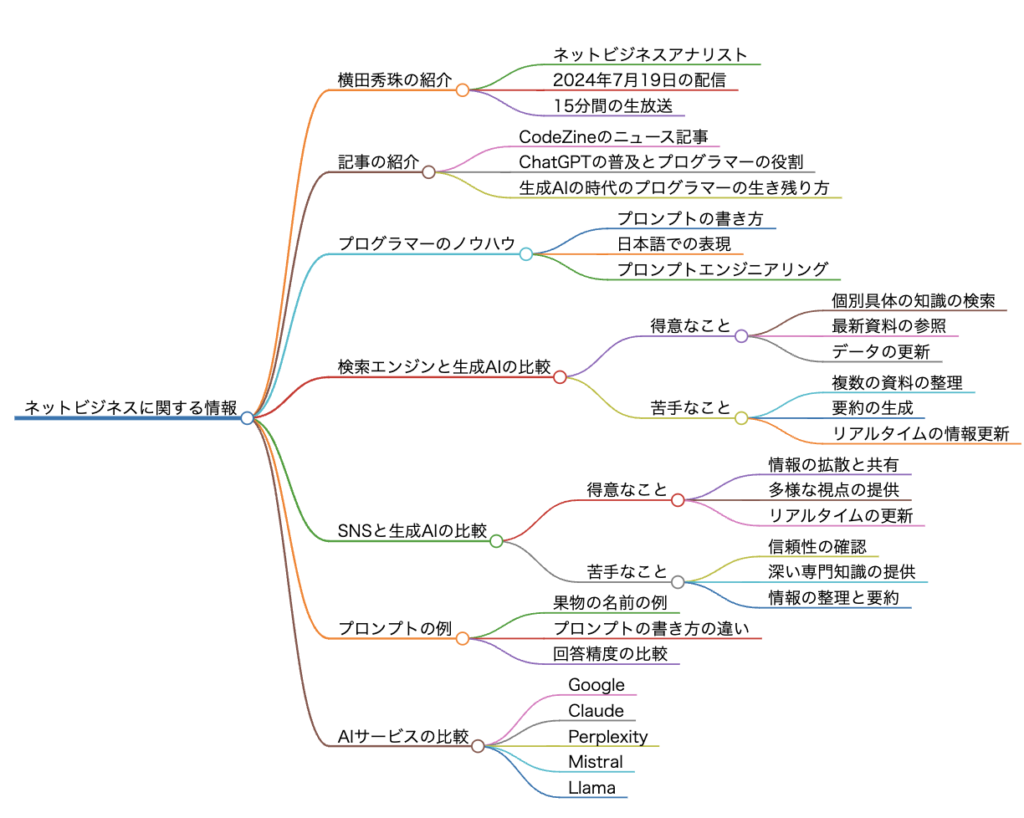
ネットビジネスアナリスト横田秀珠が、2024年7月19日の配信で、検索エンジン、SNS、LLM(生成AI)の得意と苦手を比較し、プログラマーがプロンプトを正しく書くことの重要性を強調。プロンプトの書き方の違いがAIの回答精度に影響を与える例も紹介し、プログラマーのノウハウを活かすプロンプトエンジニアリングの重要性を説明。
検索エンジン・SNS・LLM(生成AI)×得意・苦手マトリックス分析

検索エンジン、LLM、SNSの比較とプロンプトエンジニアリング重要性
- はじめに
- 検索エンジン、LLM、SNSの特徴
- 各技術の得意分野と苦手分野
- プロンプトエンジニアリングの重要性
- AIモデル間の性能比較
- おわりに
- よくある質問
はじめに
デジタル時代の情報収集と処理方法は、日々進化を遂げています。検索エンジン、大規模言語モデル(LLM)、そしてソーシャルネットワークサービス(SNS)は、私たちが情報を探索し、理解し、共有する方法を根本から変えました。これらの技術は、それぞれ独自の強みと弱点を持っており、適切に使い分けることで、より効果的な情報活用が可能となります。
本記事では、これら3つの技術の特徴を詳しく比較し、それぞれの得意分野と苦手分野を明らかにします。さらに、AIとの効果的なコミュニケーション方法であるプロンプトエンジニアリングの重要性にも焦点を当てます。技術の進化とともに、私たちユーザーも賢く適応していく必要があります。この記事を通じて、情報技術の現状と未来について、新たな視点を得ていただければ幸いです。
検索エンジン、LLM、SNSの特徴
検索エンジンの特徴
検索エンジンは、インターネット上の膨大な情報から必要なものを素早く見つけ出す強力なツールです。その主な特徴は以下の通りです:
- 個別具体の知識の検索
- ウェブ上に存在する特定の情報や事実を効率的に見つけ出すことができます。
- キーワードベースの検索により、ユーザーの意図に合った情報を提供します。
- 最新の資料を参照する能力
- 新しい情報が常にインデックスに追加されるため、最新の情報にアクセスしやすいです。
- クローラーが定期的にウェブサイトを巡回し、数時間単位でデータを更新します。
- 古い情報の価値も認識
- 古い情報でも、引用が多いなど価値があると判断された場合は、検索結果で高順位に表示されることがあります。
- ドメインパワーやバックリンクの数など、様々な要因が考慮されます。
しかし、検索エンジンにも限界があります:
- 複数の資料の整理や推論が苦手
- 個々の記事や情報は提供できますが、それらを横断的に分析したり、総合的な結論を導き出したりすることは困難です。
- ウェブページの要約機能の限界
- 検索結果のディスクリプションは、必ずしも適切な要約になっていない場合があります。
- AIによる要約機能の導入が期待されています。
- 抽象概念や常識の獲得が困難
- 個別の情報は提供できても、それらを包括的に理解し、新たな知見を生み出すことは難しいです。
LLM(大規模言語モデル)の特徴
LLMは、膨大なテキストデータから学習し、人間のような自然言語処理能力を持つAIモデルです。その主な特徴は以下の通りです:
- 複数の情報源からの知識統合
- 様々なウェブサイトや文書から学習した知識を統合し、包括的な回答を提供できます。
- 抽象的な概念や一般的な常識を理解し、活用することができます。
- 複数の資料の整理、演算、推論能力
- 与えられた情報を分析し、論理的な推論を行うことができます。
- 複数の情報源から得た知識を組み合わせて、新たな洞察を導き出すことができます。
- 自然な対話と質問応答
- ユーザーの質問に対して、自然な言葉で回答することができます。
- 文脈を理解し、フォローアップの質問にも適切に対応できます。
しかし、LLMにも課題があります:
- 最新情報の反映に時間がかかる
- モデルの更新には時間がかかるため、最新の情報が即座に反映されるわけではありません。
- 通常、数ヶ月単位でのデータ更新が必要です。
- 事実確認の難しさ
- 生成された回答の正確性を直接確認することが難しい場合があります。
- 「ハルシネーション」と呼ばれる、事実ではない情報を生成してしまう問題があります。
- 個別具体の情報源の明示が困難
- 学習データ全体から得た知識を基に回答するため、特定の情報源を明示することが難しいです。
SNS(ソーシャルネットワークサービス)の特徴
SNSは、ユーザー間のコミュニケーションと情報共有を促進するプラットフォームです。その主な特徴は以下の通りです:
- 情報の拡散と共有の速さ
- ユーザー間で情報が瞬時に共有され、広範囲に拡散されます。
- リアルタイムで情報が更新されるため、最新のトレンドや出来事を把握しやすいです。
- 多様な視点の提供
- 様々なバックグラウンドを持つユーザーが情報を発信するため、多角的な視点が得られます。
- 専門家から一般ユーザーまで、幅広い層からの情報が集まります。
- ユーザー生成コンテンツの豊富さ
- 個人の経験や意見が直接共有されるため、公式な情報源では得られない洞察が得られることがあります。
- 画像や動画など、多様なフォーマットでの情報共有が可能です。
しかし、SNSにも注意点があります:
- 信頼性の確認が難しい
- 誤情報やデマが急速に拡散する可能性があります。
- 情報の出所や真偽を確認するのが困難な場合があります。
- 深い専門知識の提供が限定的
- 短文や簡潔な投稿が主流のため、詳細な専門知識の共有には適していない場合があります。
- 専門的な内容が簡略化されすぎて、誤解を招く可能性があります。
- 情報の整理と要約が困難
- 大量の投稿から必要な情報を抽出し、整理することが難しいです。
- トピックごとの体系的な情報収集が容易ではありません。
これら3つの技術は、それぞれ独自の強みと弱みを持っています。効果的な情報収集と活用のためには、これらの特徴を理解し、適切に組み合わせて使用することが重要です。
各技術の得意分野と苦手分野
検索エンジンの得意分野と苦手分野
検索エンジンの得意分野:
- 個別具体の知識の検索
- ウェブ上の膨大な情報から、特定のキーワードや質問に関連する情報を素早く見つけ出すことができます。
- 学術論文、ニュース記事、ブログ投稿など、様々な種類の情報源にアクセスできます。
- 最新の資料を参照する能力
- クローラーが定期的にウェブを巡回し、新しい情報を収集・インデックス化するため、最新の情報にアクセスしやすいです。
- ニュースや最新のトレンドに関する情報を効率的に見つけることができます。
- 広範囲の情報源へのアクセス
- インターネット上のあらゆるウェブサイトから情報を収集するため、多様な視点や情報源にアクセスできます。
- 専門的な情報から一般的な情報まで、幅広いトピックをカバーしています。
検索エンジンの苦手分野:
- 複数の資料の整理、演繹、推論
- 個々の情報を提供することはできますが、それらを統合して新たな洞察を生み出すことは難しいです。
- ユーザーが自ら情報を読み解き、結論を導き出す必要があります。
- ウェブページの要約
- 検索結果のスニペット(短い説明文)は必ずしも適切な要約になっておらず、ページの内容を正確に反映していない場合があります。
- ユーザーが実際にページを開いて内容を確認する必要があります。
- 抽象概念や常識の獲得と適用
- 検索エンジンは情報の索引付けと検索に特化しているため、人間のような理解や推論能力は持ち合わせていません。
- 文脈や意図を理解した上での情報提供は困難です。
LLM(大規模言語モデル)の得意分野と苦手分野
LLMの得意分野:
- 複数の情報源からの知識統合
- 膨大なテキストデータから学習した知識を活用し、包括的な回答を生成できます。
- 異なる分野の情報を組み合わせて、新たな洞察を提供することができます。
- 複数の資料の整理、演算、推論
- 与えられた情報を分析し、論理的な推論を行うことができます。
- 複雑な質問に対しても、段階的な思考プロセスを示しながら回答することができます。
- 自然な対話と質問応答
- ユーザーの質問を理解し、自然な言葉で回答することができます。
- 文脈を考慮しながら、フォローアップの質問にも適切に対応できます。
LLMの苦手分野:
- 最新情報の即時反映
- モデルの更新には時間がかかるため、最新の出来事や急速に変化する情報を即座に反映することは困難です。
- 通常、数ヶ月単位でのデータ更新が必要となります。
- 個別具体の情報源の明示
- 学習データ全体から得た知識を基に回答するため、特定の情報源を明確に示すことが難しいです。
- 回答の根拠を具体的に示すことが求められる場合、課題となる可能性があります。
- ウェブの直接閲覧による事実確認
- 生成された回答の正確性を直接確認することが難しい場合があります。
- 「ハルシネーション」と呼ばれる、事実ではない情報を生成してしまう問題があります。
SNS(ソーシャルネットワークサービス)の得意分野と苦手分野
SNSの得意分野:
- 情報の拡散と共有
- ユーザー間で情報が瞬時に共有され、広範囲に拡散されます。
- 緊急ニュースや社会的なトレンドを素早く把握することができます。
- 多様な視点の提供
- 様々なバックグラウンドを持つユーザーが情報を発信するため、多角的な視点が得られます。
- 公式な情報源では得られない、個人の経験や意見に基づく洞察を得ることができます。
- リアルタイムの更新
- ユーザーが常に新しい情報を投稿するため、最新の出来事や状況をリアルタイムで追跡できます。
- ハッシュタグなどを使用して、特定のトピックに関する最新の議論や反応を追うことができます。
SNSの苦手分野:
- 信頼性の確認
- 誤情報やデマが急速に拡散する可能性があり、情報の真偽を確認するのが困難な場合があります。
- ソースの信頼性や情報の正確性を評価するスキルが必要です。
- 深い専門知識の提供
- 多くのSNSプラットフォームは短文や簡潔な投稿を推奨しているため、詳細な専門知識の共有には適していない場合があります。
- 複雑なトピックが簡略化されすぎて、誤解を招く可能性があります。
- 情報の整理と要約
大量の投稿から必要な情報を抽出し、整理することが難しいです。
トピックごとの体系的な情報収集や、長期的な傾向分析が容易ではありません。
ノイズ(関連性の低い投稿)が多く、本当に価値のある情報を見つけるのに時間がかかる場合があります。
これらの特徴を理解することで、各技術の長所を活かし、短所を補完するような使い方が可能になります。例えば、検索エンジンで基本的な事実を確認し、LLMで深い分析や推論を行い、SNSで最新のトレンドや多様な意見を把握するといった組み合わせが考えられます。
プロンプトエンジニアリングの重要性
プロンプトエンジニアリングとは、AIモデル(特にLLM)に対して効果的な指示や質問を行うための技術です。この技術の重要性が増している理由と、その具体的な方法について説明します。
プロンプトエンジニアリングの重要性
- AIの能力を最大限に引き出す
- 適切なプロンプトを使用することで、AIの潜在能力を最大限に活用できます。
- 曖昧な質問では不十分な回答しか得られませんが、明確で具体的なプロンプトを使用することで、より正確で有用な情報を得ることができます。
- AIの限界を理解し、対処する
- AIモデルの特性や制限を理解することで、より効果的な質問や指示を出すことができます。
- 例えば、最新の情報を求める場合は検索エンジンを併用するなど、AIの弱点を補完する戦略を立てることができます。
- 効率的な情報収集と問題解決
- 的確なプロンプトを使用することで、必要な情報を素早く取得したり、複雑な問題を効率的に解決したりすることができます。
- 時間と労力を節約しつつ、質の高い結果を得ることができます。
プロンプトエンジニアリングの具体的な方法
以下に、効果的なプロンプトエンジニアリングの例を示します。この例では、「名前が3文字の果物を10個挙げる」というタスクを取り上げます。
- 素人的なプロンプト:
名前が3文字の果物を10個教えてください。
このプロンプトでは、AIモデルが「3文字」の定義を誤解したり、不適切な回答を生成したりする可能性があります。 - プログラマー的なプロンプト:
以下の手順に従って、名前が3文字の果物を10個リストアップしてください: 1. 果物の名前を挙げる 2. その名前が何文字か数える 3. 3文字の場合のみ記録する 4. 1-3を繰り返し、記録が10個になるまで続ける 5. 記録された10個の果物名をリストとして出力する 各ステップごとに処理内容を表示してください。このプロンプトの特徴:- タスクを明確な手順に分解しています。
- 各ステップでの処理内容を表示するよう指示しているため、AIの思考プロセスを追跡できます。
- 条件(3文字)を明確に定義し、それを満たす場合のみ記録するよう指示しています。
- 目標(10個)を明確に設定しています。
このようなプロンプトを使用することで、AIはより正確で信頼性の高い回答を提供できます。また、プロセスが可視化されるため、エラーが発生した場合にも容易に問題を特定し、修正することができます。
プロンプトエンジニアリングのスキルを磨くことで、AIとのより効果的なコミュニケーションが可能になり、様々なタスクや問題解決においてAIの能力を最大限に活用することができます。
AIモデル間の性能比較
異なるAIモデル間で性能を比較することは、各モデルの強みと弱みを理解し、適切な使用方法を見出すために重要です。ここでは、先ほどの「3文字の果物を10個リストアップする」タスクを例に、複数のAIモデルの性能を比較します。
比較対象のAIモデル
- ChatGPT (OpenAI)
- Google Gemini
- Claude (Anthropic)
- Perplexity AI
- Mixtral
- LLaMA (Meta)
比較結果と考察
- ChatGPT:
- 初期の簡単なプロンプトでは不正確な回答を生成。
- 詳細なプロンプトを使用すると、正確な結果を生成できた。
- プロンプトの質に応じて性能が大きく変わることが示された。
- Google Gemini:
- 簡単なプロンプトでも比較的良好な結果を示した。
- 詳細なプロンプトを使用した場合、正確な結果を生成。
- 日本語の理解力が比較的高いことが示唆された。
- Claude:
- 詳細なプロンプトを使用しても、一部の果物名の文字数を誤って判断。
- 例:「リンゴ」を4文字と判断し、記録しなかった。
- 日本語の文字数カウントに課題がある可能性が示された。
- Perplexity AI:
- このタスクに対して不正確な結果を生成。
- 特定のタスクや言語での性能に課題がある可能性が示された。
- Mixtral:
- このタスクに対して不正確な結果を生成。
- 特定のタスクや言語での性能に課題がある可能性が示された。
- LLaMA:
- このタスクに対して不正確な結果を生成。
- オープンソースモデルとして、さらなる改善の余地があることが示唆された。
考察
- プロンプトの重要性:
- 詳細で明確なプロンプトを使用することで、多くのモデルの性能が向上しました。
- プロンプトエンジニアリングのスキルが重要であることが再確認されました。
- 言語理解の差異:
- 日本語の処理、特に文字数のカウントに関して、モデル間で差異が見られました。
- 多言語対応の精度向上が今後の課題として浮かび上がりました。
- モデルの特性:
- 各モデルが得意とする分野や苦手とする分野が異なることが示されました。
- タスクの性質に応じて適切なモデルを選択することの重要性が確認されました。
- 継続的な改善の必要性:
- すべてのモデルに改善の余地があることが示されました。
- 特に、オープンソースモデルや新しいモデルは、今後の更新や改良により大きく性能が向上する可能性があります。
- 評価基準の重要性:
- 単一のタスクだけでなく、多様なタスクや言語での評価が必要です。
- 定量的および定性的な評価方法の開発と適用が求められます。
この比較結果は、AIモデルの選択や使用方法を検討する際の参考になります。また、各モデルの開発者にとっても、改善すべき点を特定するための有用な情報となるでしょう。
おわりに
本記事では、検索エンジン、大規模言語モデル(LLM)、ソーシャルネットワークサービス(SNS)の特徴と、それぞれの得意分野・苦手分野について詳しく比較しました。また、AIとの効果的なコミュニケーション方法であるプロンプトエンジニアリングの重要性や、異なるAIモデル間の性能比較についても深く掘り下げました。
これらの技術は日々進化しており、私たちの情報収集や問題解決の方法を大きく変えつつあります。各技術の特徴を理解し、適切に組み合わせて活用することで、より効果的な情報処理が可能になります。
特に、プロンプトエンジニアリングのスキルを磨くことは、AIの能力を最大限に引き出すために不可欠です。明確で具体的なプロンプトを使用することで、より正確で有用な情報を得ることができ、複雑な問題解決にもAIを効果的に活用できるようになります。
今後も技術の進化は続くでしょう。ユーザーとして、これらの技術の特徴と可能性を理解し、賢く活用していくことが重要です。同時に、各技術の限界も認識し、批判的思考力を養うことで、情報の真偽を見極め、より良い意思決定ができるようになるでしょう。
デジタル時代の情報リテラシーは、これらの技術を理解し、適切に活用する能力と言えるかもしれません。私たちは、技術の進化に適応しながら、より豊かで効率的な情報社会を築いていく責任があります。
よくある質問
Q1: 検索エンジン、LLM、SNSのうち、最も信頼性の高い情報源はどれですか?
A1: 各技術には長所と短所があり、絶対的に最も信頼性が高いものを一つ選ぶことは難しいです。検索エンジンは公式情報や学術論文にアクセスできる点で信頼性が高いですが、LLMは複数の情報源を統合して分析できる利点があります。SNSはリアルタイムの情報を得られますが、誤情報も拡散しやすいです。情報の性質や目的に応じて、適切な情報源を選択し、可能であれば複数の情報源を組み合わせて使用することが望ましいでしょう。
Q2: プロンプトエンジニアリングのスキルを向上させるには、どのような方法がありますか?
A2: プロンプトエンジニアリングのスキルを向上させるには、以下の方法が効果的です:
- 様々なAIモデルを実際に使用し、異なるプロンプトの効果を比較する
- プログラミングの基本的な概念(条件分岐、ループなど)を学び、それらをプロンプトに応用する
- タスクを小さなステップに分解する習慣をつける
- AIの限界と特性を理解し、それに合わせてプロンプトを調整する
- オンラインコミュニティやフォーラムで他のユーザーと知見を共有する
Q3: AIモデル間の性能差は今後どのように変化していくと予想されますか?
A3: AIモデル間の性能差は、今後以下のように変化していく可能性があります:
- 大手企業のモデルとオープンソースモデルの差が縮小する可能性がある
- 特定のタスクや言語に特化したモデルが登場し、それらの分野で高い性能を発揮する
- マルチモーダル(テキスト、画像、音声などを統合的に扱える)モデルの性能が向上し、新たな応用分野が開拓される
- エッジデバイスで動作する軽量モデルの性能が向上し、よりパーソナライズされたAI体験が可能になる
ただし、これらの予測は技術の進歩や研究の方向性によって変わる可能性があります。
Q4: LLMの「ハルシネーション」問題はどのように対処すべきですか?
A4: LLMの「ハルシネーション」(事実ではない情報を生成してしまう問題)への対処方法には以下があります:
- 複数の情報源で事実確認を行う
- AIの回答に具体的な情報源の提示を求める
- クリティカルシンキングを養い、AIの回答を鵜呑みにしない
- 重要な意思決定には、AI以外の情報源も併用する
- AIモデルの開発者は、事実性チェックや不確実性の表示機能を強化する
また、ユーザー側でもAIの限界を理解し、適切な使用方法を学ぶことが重要です。
Q5: 将来的に、検索エンジン、LLM、SNSの機能は統合されていくのでしょうか?
A5: 将来的に、これらの技術の機能が部分的に統合されていく可能性は高いです。例えば:
- 検索エンジンにLLMの機能を組み込み、より自然な質問応答を可能にする
- SNSプラットフォームにAI支援機能を追加し、情報の信頼性評価や個人化を強化する
- LLMにリアルタイムのウェブ検索機能を統合し、最新情報へのアクセスを可能にする 4. 統合プラットフォームが登場し、検索、対話型AI、ソーシャル機能を一つのインターフェースで提供する
ただし、完全な統合には技術的・倫理的な課題があるため、各技術の独自性も一定程度維持されると予想されます。ユーザーのプライバシー保護や情報の多様性確保のため、一定の分離が必要とされる可能性もあります。将来的には、これらの技術を状況に応じて柔軟に組み合わせて使用できるエコシステムが形成されるかもしれません。
詳しくは15分の動画で解説しました。
https://www.youtube.com/watch?v=U4vbCdmuwVo
0:00 👋 導入部分
1:06 💡 プログラマーと生成AIの関係
2:11 🔍 検索エンジンの得意分野
3:18 🧩 検索エンジンの苦手分野
5:33 🤖 LLMの得意分野
6:40 📚 LLMの苦手分野
9:01 📢 SNSの得意分野
10:07 🛑 SNSの苦手分野
11:16 🔄 プロンプトの書き方比較
13:32 💻 天秤AIでのテスト結果
14:34 📝 まとめとプロンプトエンジニアリングの重要性
上記の動画はYouTubeメンバーシップのみ
公開しています。詳しくは以下をご覧ください。
https://yokotashurin.com/youtube/membership.html
YouTubeメンバーシップ申込こちら↓
https://www.youtube.com/channel/UCXHCC1WbbF3jPnL1JdRWWNA/join
検索エンジン・SNS・LLM(生成AI)×得意・苦手マトリックス分析の鍵
💡ネットビジネス
ネットビジネスとは、インターネットを通じて行われるビジネス全般を指します。このビデオでは、ネットビジネスアナリストである横田秀珠さんが、ネットビジネスに関する情報を提供しています。特に、プログラマーがAIの進化と共にどのように生き残るかというテーマに焦点を当てています。
💡プログラマー
プログラマーとは、コンピュータプログラミングを職業とする人のことです。ビデオでは、生成AIの普及によりプログラマーの役割が変化していると述べており、プログラマーがどのようにAIと協調して働くかが重要な議題となっています。
💡生成AI
生成AIとは、テキストや画像、音声などを生成する人工知能のことで、特に自然言語処理(NLP)分野で進歩しています。ビデオでは、生成AIがプログラマーのスキルにどのように影響を与えているか、またプログラマーが生成AIを使いこなすためにどのようなスキルが必要かが議論されています。
💡プロンプト
プロンプトとは、生成AIに入力するテキストや質問のことで、AIの応答や生成内容に大きな影響を与えます。ビデオでは、プロンプトの書き方とその精度の関係、プログラマーがプロンプトを効果的に使用する方法について触れています。
💡検索エンジン
検索エンジンとは、インターネット上の情報やウェブページを検索するためのシステムです。ビデオでは、検索エンジンが得意とする具体的な知識の検索や最新情報の提供について説明しており、生成AIとの比較も行われています。
💡SNS
SNSとは、ソーシャルネットワークサービスの略で、FacebookやTwitterなどのソーシャルメディアを指します。ビデオでは、SNSがリアルタイムの情報更新や多様な視点の提供においてどのような役割を果たしているかが議論されています。
💡LLM(ラージランゲージモデル)
LLMとは、ラージランゲージモデルの略で、複雑な言語パターンを学習し、自然言語を理解する人工知能のモデルです。ビデオでは、LLMが複数のウェブページから抽象概念や常識を獲得し、それらを総合して応答する能力について説明されています。
💡データ更新
データ更新とは、検索エンジンやAIシステムが最新の情報に合わせてデータをアップデートすることを指します。ビデオでは、検索エンジンやLLMがデータ更新にどの程度の時間を要するか、またリアルタイム性がどの程度重要かが議論されています。
💡デマ
デマとは、誤った情報や根拠のない噂を広める行為です。ビデオでは、SNSでの情報拡散がデマの拡散につながることがあると警告し、生成AIや検索エンジンがデマの検出や抑制に役立つ可能性についても言及されています。
💡プロンプトエンジニアリング
プロンプトエンジニアリングとは、生成AIに最適なプロンプトを設計する技術や戦略のことで、プログラマーがAIと効果的にコミュニケーションを取るために重要なスキルです。ビデオでは、プロンプトの書き方と生成AIの応答精度の関係について具体的な例を用いて説明されています。