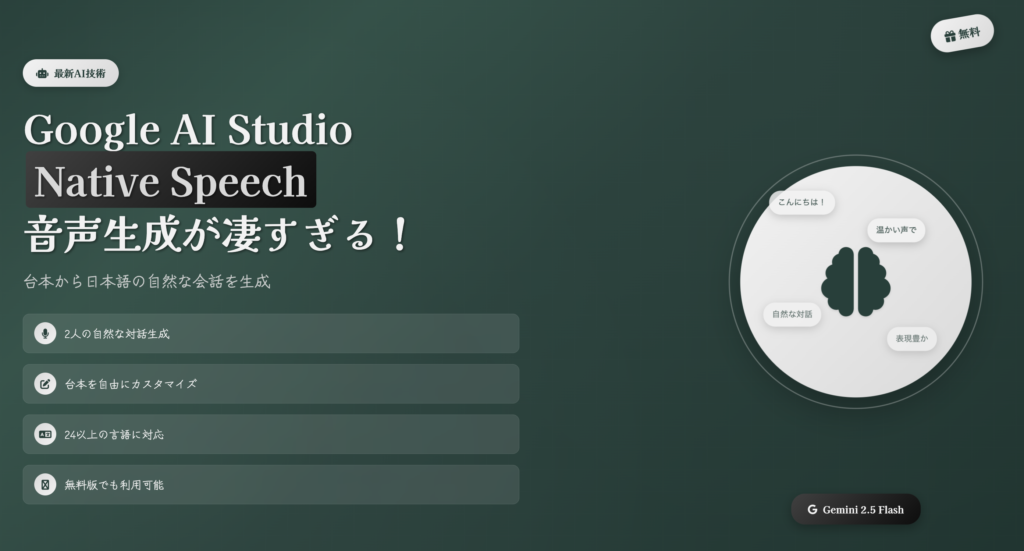
Google AI Studio2人の会話を台詞テキスト読み上げ音声合成

FM新津の放送日は8/10で決定。
近くなったら、また連絡します!
イーンスパイアの横田です。
https://www.enspire.co.jp

さて、本題です。
2025年5月21日、Google I/Oで発表された
https://blog.google/intl/ja-jp/company-news/technology/google-gemini-updates-io-2025/
Gemini 2.5 Flash Preview TTSを活用して
2人の会話を台詞テキスト読み上げ音声合成
できるGoogle AI Studioを紹介します。
https://aistudio.google.com/u/3/generate-speech
実際に作ってみた音声もあるのでご覧ください。
https://www.youtube.com/watch?v=6xPHiji49Fk
Google AI Stuidoで2人の会話を台詞テキスト読み上げ音声合成
📢 GoogleのAI技術で台本から自然な日本語音声会話を無料生成する革新的な手法
🚀 Google AI Studioの新機能登場
Native speech generationで複数話者による自然な音声対話が可能に!
✨ 24以上の言語対応
✨ 表現力豊かな音声生成
✨ 無料版でも利用可能
✨ 24以上の言語対応
✨ 表現力豊かな音声生成
✨ 無料版でも利用可能
💡 従来のNotebookLMとの違い:台本を一言一句指定でき、トーンも自由自在!
🎯 実際の音声デモ体験
「Miliaさん、こんにちは。今日も元気いっぱいだね」
「先生、こんにちは!インスタのカルーセル投稿について教えて〜」
「先生、こんにちは!インスタのカルーセル投稿について教えて〜」
自然な会話の流れ、感情豊かな表現、日本語特有のニュアンスまで完璧に再現
⬇️
📝 作成手順ステップガイド
1
Google AI Studioにアクセス
Generate Media → Generate speech → Native speech generation を選択
Generate Media → Generate speech → Native speech generation を選択
2
モデル設定
Gemini 2.5 Flash Preview TTS を選択
🔹 Single-speaker(1人)or Multi-speaker(2人)モード選択
Gemini 2.5 Flash Preview TTS を選択
🔹 Single-speaker(1人)or Multi-speaker(2人)モード選択
3
台本作成のコツ
🎭 キャラ設定:「優しい男性社長」「好奇心旺盛な女子学生」
📏 時間制限:5分程度が最適(5分20秒が上限)
🎭 キャラ設定:「優しい男性社長」「好奇心旺盛な女子学生」
📏 時間制限:5分程度が最適(5分20秒が上限)
4
Geminiで台本生成
テンプレート形式をコピー→内容指定→自動生成
テンプレート形式をコピー→内容指定→自動生成
5
音声設定&実行
🎤 Speaker 1, 2の声を選択
▶️ Runボタンで音声生成完了
🎤 Speaker 1, 2の声を選択
▶️ Runボタンで音声生成完了
💼 実践例:工務店インタビュー
設定例
👨 横田工務店社長(優しい男性)
👩 Milia(長岡造形大学生、好奇心旺盛)
📋 テーマ:失敗しない家づくりについて
👨 横田工務店社長(優しい男性)
👩 Milia(長岡造形大学生、好奇心旺盛)
📋 テーマ:失敗しない家づくりについて
生成された対話は自然で、専門知識を分かりやすく説明する内容に。最後にチャンネル登録の呼びかけも自動挿入!
⚡ 活用シーン&注意点
💡 活用方法
🎥 YouTube動画
🎙️ ポッドキャスト
📱 インスタグラム投稿
📢 プレゼンテーション
🎥 YouTube動画
🎙️ ポッドキャスト
📱 インスタグラム投稿
📢 プレゼンテーション
⚠️ 注意点
漢字の読み間違いがある場合はカタカナに変更
一発完成を目指すなら事前チェックが重要
漢字の読み間違いがある場合はカタカナに変更
一発完成を目指すなら事前チェックが重要
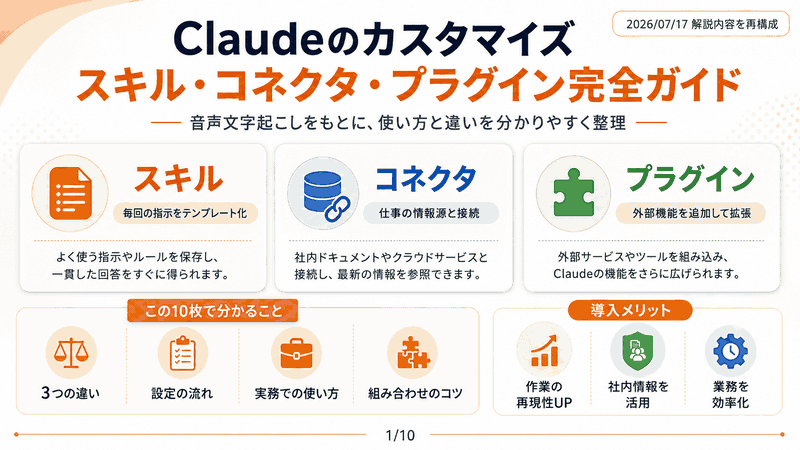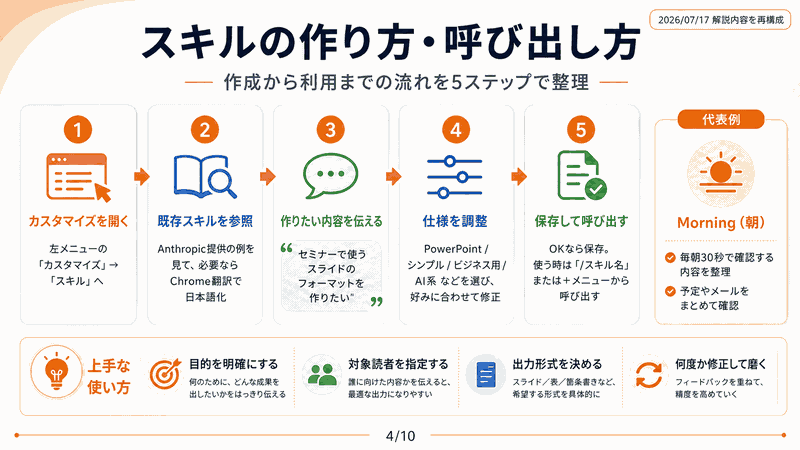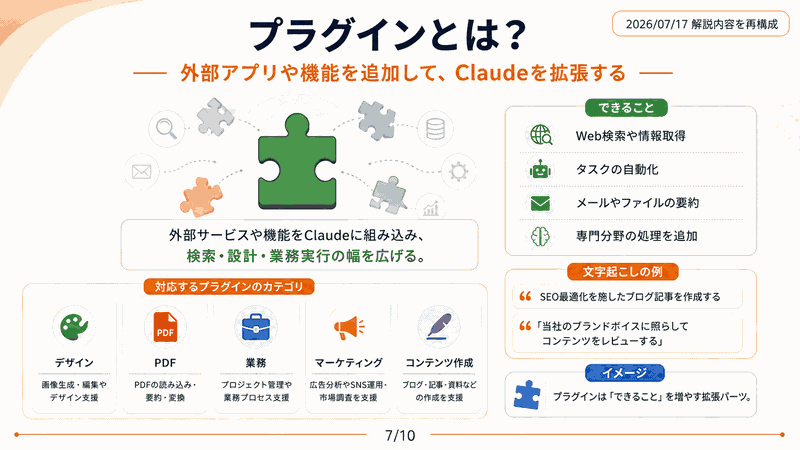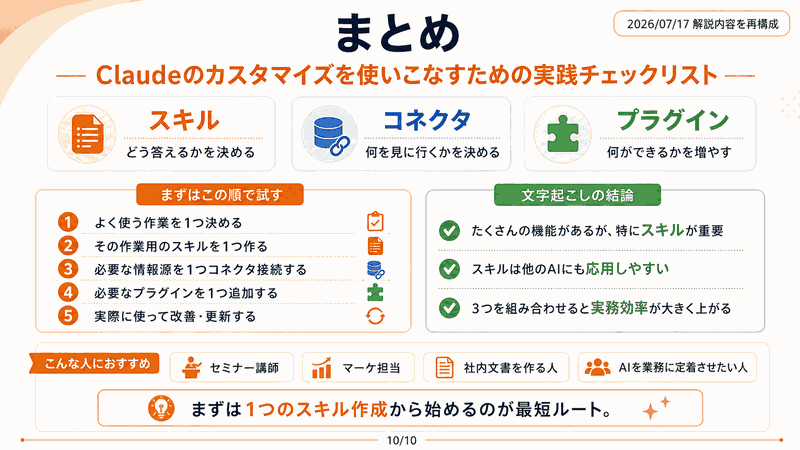
🌟 まとめ:AI音声革命の到来
Google AI StudioのNative speech generationにより、
誰でも簡単に高品質な日本語音声コンテンツを作成可能に!
📌 無料で利用開始
📌 台本完全カスタマイズ
📌 自然な会話表現
📌 多言語対応
誰でも簡単に高品質な日本語音声コンテンツを作成可能に!
📌 無料で利用開始
📌 台本完全カスタマイズ
📌 自然な会話表現
📌 多言語対応
Google AI Stuidoで2人の会話を台詞テキスト読み上げ音声合成
Google AI StudioのNative speech generation機能を使った日本語音声会話の生成方法を紹介。Gemini 2.5 Pro/Flashの新機能で、複数話者による表現豊かな音声読み上げが可能。台本作成にはGeminiを活用し、キャラクター設定や会話内容を指定。無料版でも利用でき、最大5分程度の音声を生成可能。YouTubeやポッドキャスト、SNSコンテンツ制作に活用できる画期的なツール。
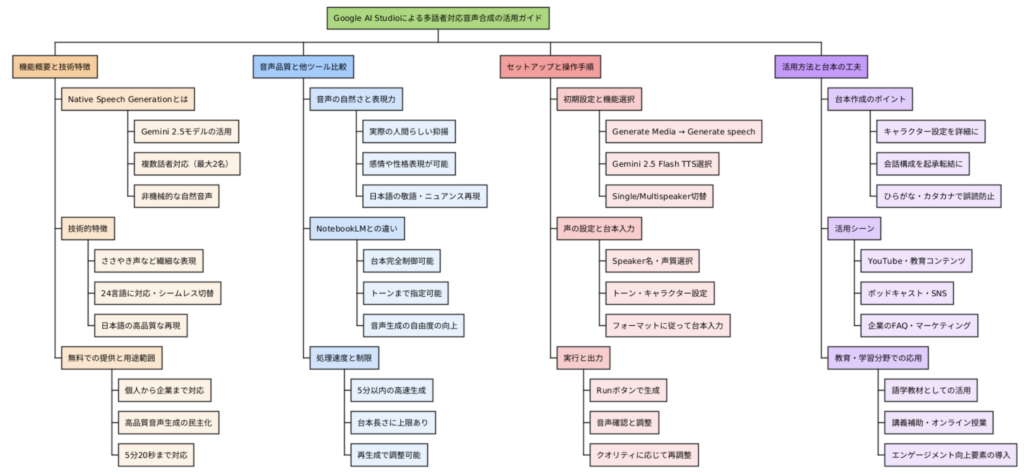
- はじめに
- Google AI StudioのNative Speech Generationとは?
- 実際の音声品質と従来ツールとの違い
- 具体的な使い方とセットアップ手順
- 台本作成のコツと活用方法
- おわりに
- よくある質問(Q&A)
はじめに
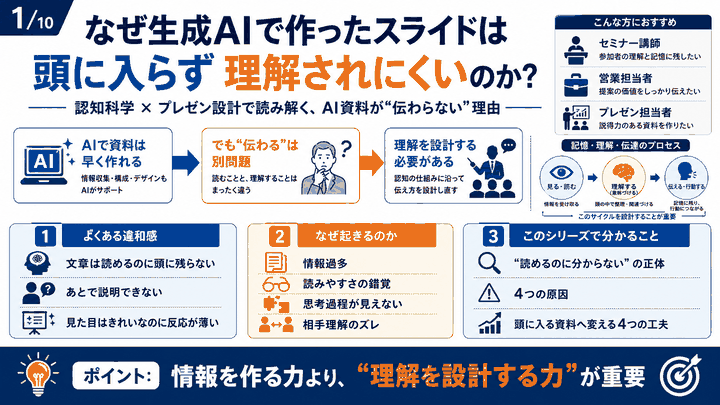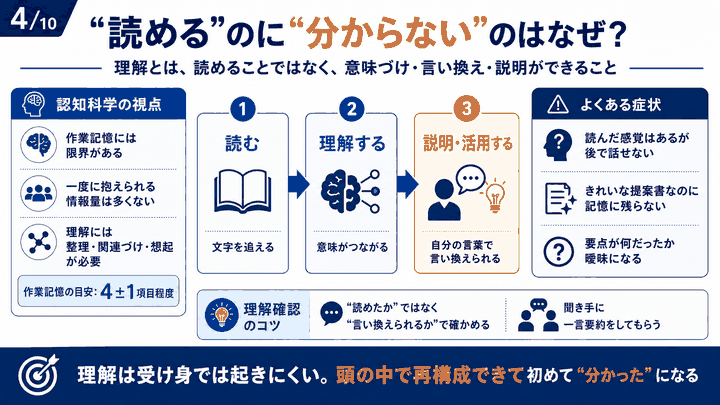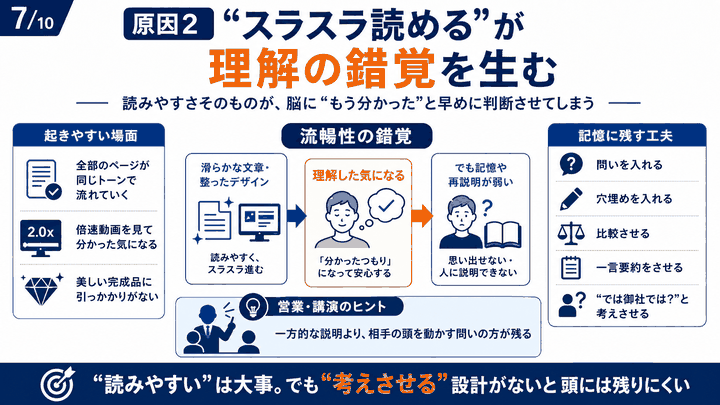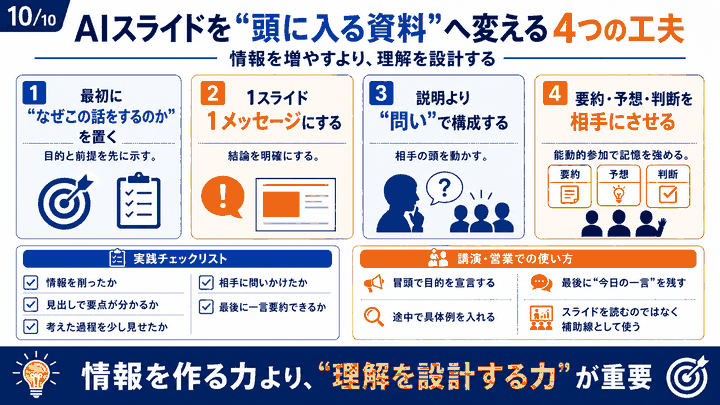
AIによる音声生成技術の進歩は目覚ましく、私たちのコンテンツ制作方法を大きく変えようとしています。特に最近では、単なる文字読み上げから、まるで人間同士が自然に会話しているかのような音声生成が可能になってきました。今回ご紹介するGoogle AI StudioのNative Speech Generation機能は、そんな最新技術の中でも特に注目すべきツールです。この機能を使えば、台本を用意するだけで、二人の話者による自然な日本語会話を無料で生成することができます。YouTubeコンテンツ、ポッドキャスト、インスタグラムのリール動画など、様々な用途に活用できるこの革新的な機能について、実際の使用例を交えながら詳しく解説していきます。
Google AI StudioのNative Speech Generationとは?
Google AI StudioのNative Speech Generation機能は、2025年5月23日現在、GoogleのI/Oで発表された最新の音声生成技術です。この機能の最大の特徴は、GoogleのGemini 2.5 ProおよびGemini 2.5 Flashモデルを活用したテキスト読み上げ(TTS)のプレビュー版として提供されていることです。
従来の音声読み上げ機能との大きな違いは、複数の話者に初めて対応している点にあります。現在は二人の話者による会話生成が可能で、将来的には三人、四人と拡張される可能性も示唆されています。このネイティブ音声出力機能は、単なる機械的な読み上げではなく、表現力豊かで微妙なニュアンスまで捉えることができます。
技術的な特徴として、ささやき声のような非常に細かな表現も再現可能で、24以上の言語に対応しており、言語間をシームレスに切り替えることができます。特に日本語での音声生成品質は非常に高く、自然な会話調での音声生成が可能です。
この機能が搭載されているGoogle AI Studioは、Googleが提供するAI開発プラットフォームの一部として無料で利用することができます。そのため、個人のコンテンツクリエイターから企業まで、幅広いユーザーが手軽に高品質な音声コンテンツを制作できるようになりました。
音声生成の仕組みとしては、まず台本をテキスト形式で用意し、それぞれの話者の声質や話し方の特徴を設定します。その後、AIが台本を解析して、自然な会話のリズムや感情表現を含んだ音声を生成します。生成される音声の長さは現在のところ約5分20秒が上限となっており、それ以上長い台本の場合は途中で切れてしまう可能性があります。
実際の音声品質と従来ツールとの違い
Google AI StudioのNative Speech Generation機能で生成される音声の品質は、従来の音声読み上げツールと比較して格段に向上しています。実際に生成された音声サンプルを聞くと、その自然さに驚かされます。
例えば、実際に生成された会話では「Miliaさん、こんにちは。今日も元気いっぱいだね。先生、こんにちは。聞いてくださいよ。最近インスタでスワイプすると次々と情報が出てくる投稿あるじゃないですか。あれ、すっごくおしゃれでわかりやすいなって思うんですけど、どうやって作ってるのか謎すぎて夜も眠れません」といった具合に、まるで実際の人間同士の会話のような自然な抑揚と感情表現が含まれています。
従来のGoogle NotebookLMとの比較において、最も大きな違いは台本の制御可能性にあります。NotebookLMでは資料をアップロードすると自動的に会話が生成されますが、話者が何を話すかはAIに委ねられており、ユーザーが一言一句を指定することはできませんでした。これに対して、Native Speech Generation機能では、話者の発言内容を完全にコントロールできるだけでなく、どのようなトーンで話すかまで細かく指定することが可能です。
音声の表現力についても大幅な向上が見られます。ささやき声、興奮した声、優しい口調、好奇心旺盛な話し方など、様々な感情や性格を声に反映させることができます。これにより、キャラクター設定に応じた適切な音声表現が可能になり、聞き手にとってより魅力的なコンテンツを作成できます。
また、日本語特有の微妙なニュアンスや敬語の使い分けも適切に表現されており、ビジネスシーンでの活用からカジュアルな会話まで、幅広い用途に対応できる品質を実現しています。漢字の読み間違いが稀に発生することはありますが、事前に台本でひらがなやカタカナに変換しておくことで、ほぼ完璧な音声生成が可能です。
生成速度についても優秀で、5分程度の会話であれば数分以内に音声ファイルが完成します。この高速処理により、コンテンツ制作のワークフローを大幅に効率化することができます。
具体的な使い方とセットアップ手順
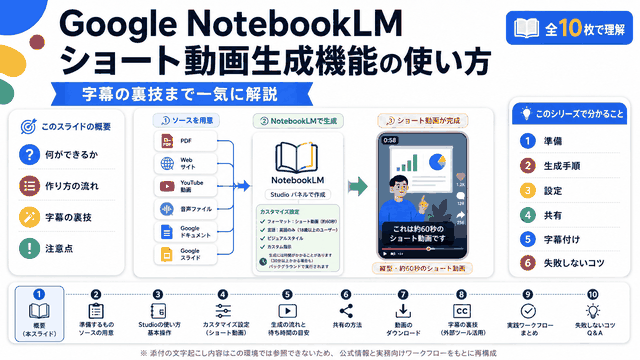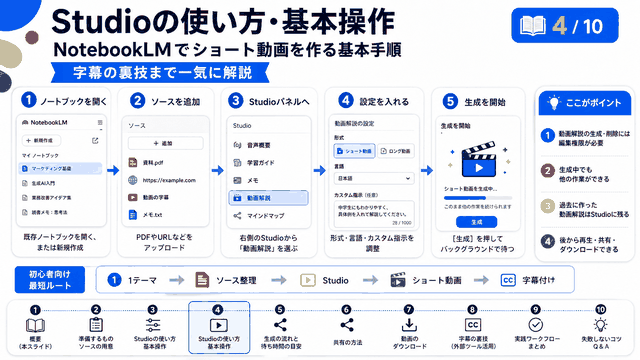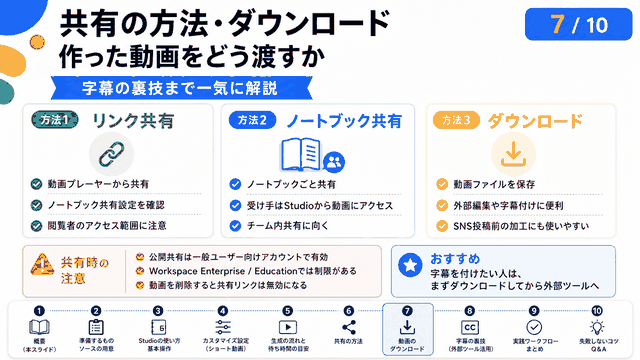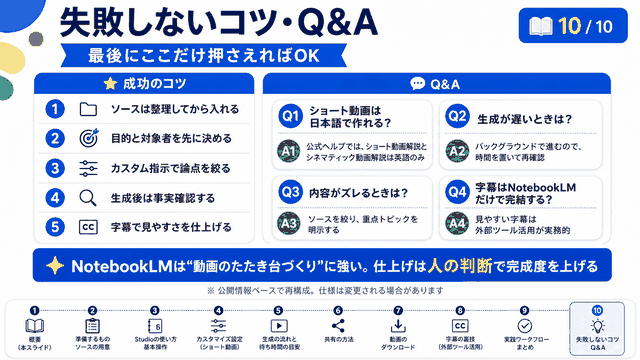
Google AI StudioのNative Speech Generation機能を使用するための具体的な手順を、ステップバイステップで解説していきます。
まず、Google AI Studioにアクセスし、アカウントにログインします。画面左側のメニューから「Generate Media」を選択し、その中の「Generate speech」をクリックします。これでNative Speech Generation機能にアクセスできます。
次に、AIモデルの選択を行います。「Gemini 2.5 Flash Preview TTS」が最新モデルとなっており、これを選択することで最高品質の音声生成が可能になります。モデル選択の下には、「Single-speaker audio」(一人話者モード)と「Multi-speaker audio」(複数話者モード)の選択肢があります。会話形式のコンテンツを作成する場合は、「Multi-speaker audio」を選択します。
Voice settingsセクションでは、各話者の設定を行います。Speaker 1とSpeaker 2それぞれについて、名前と声質を選択できます。声質は複数の選択肢が用意されており、男性声、女性声それぞれで異なる特徴を持った声を選ぶことができます。キャラクター設定に応じて適切な声を選択することが、自然な会話生成の鍵となります。
台本作成においては、Raw structure(生の構造)エリアに直接テキストを入力するか、別途作成した台本をコピー&ペーストします。台本の形式は特定のフォーマットに従う必要があり、「Read aloud in a warm, welcoming tone」といった指示文から始まり、「Speaker 1:」「Speaker 2:」といった形で各話者の発言を区別します。
台本作成を効率化するために、Google Geminiを活用することをお勧めします。Geminiに対して「横田工務店の社長である優しい男性に、好奇心旺盛の明るい女子学生のMiliaさんから失敗しない家づくりについてインタビューされている会話を5分くらいの長さで作って。Google AI StudioのGenerate speechで使うので、以下の形式に合わせて作って」といった具合に依頼し、サンプルフォーマットを提示すれば、適切な形式の台本を自動生成してもらえます。
台本の長さについては、現在5分20秒程度が上限となっているため、5分程度を目安に作成することをお勧めします。それ以上長い台本の場合、途中で音声生成が停止してしまう可能性があります。
台本の内容を入力し、話者設定を完了したら、画面右下の「Run」ボタンをクリックします。数分程度の処理時間を経て、音声ファイルが生成されます。生成された音声は即座に再生して確認でき、品質に満足できない場合は台本や設定を調整して再生成することも可能です。
台本作成のコツと活用方法
効果的な台本作成と、生成した音声コンテンツの活用方法について詳しく解説します。
台本作成において最も重要なのは、キャラクター設定の明確化です。単に「男性」「女性」といった区分ではなく、「優しい男性の社長」「好奇心旺盛の明るい女子学生」といった具体的な人物像を設定することで、より自然で魅力的な会話が生成されます。年齢、職業、性格、話し方の特徴などを詳細に設定することで、AIがそれらの特徴を音声に反映してくれます。
会話の構成については、起承転結を意識した流れを作ることが重要です。導入部分では互いの紹介や挨拶から始まり、本題に入り、クライマックスを経て、最後に締めくくりという自然な会話の流れを心がけます。また、一方的な説明ではなく、質問と回答、相槌や感想など、実際の会話に近い双方向のやり取りを意識することで、聞きやすいコンテンツになります。
専門用語や固有名詞については、正確な読み方を確保するため、ひらがなやカタカナで表記することをお勧めします。例えば「長岡造形大学」を「ながおかぞうけいだいがく」と表記することで、読み間違いを防ぐことができます。
コンテンツの活用方法としては、まずYouTubeでの音声コンテンツ配信が考えられます。画像やスライドと組み合わせることで、教育系コンテンツやビジネス系コンテンツとして活用できます。特に、専門知識の解説や商品紹介、サービス説明などに効果的です。
ポッドキャスト配信にも最適で、SpotifyやApple Podcastsなどのプラットフォームで音声のみのコンテンツとして配信することができます。通勤時間や作業中のBGMとして聴かれることが多いポッドキャストでは、自然な会話形式のコンテンツが特に好まれます。
インスタグラムのリール動画やストーリーズでも活用可能です。短時間の会話を生成し、視覚的な要素と組み合わせることで、エンゲージメントの高いコンテンツを作成できます。
企業のマーケティング活用としては、商品説明動画、FAQ回答、ブランドストーリーの紹介など、様々な用途が考えられます。従来のナレーション収録と比較して、コストと時間を大幅に削減しながら、高品質なコンテンツを制作することができます。
教育分野では、語学学習教材、講義の補助資料、オンライン授業のコンテンツとしても活用できます。特に会話形式での学習は、学習者の理解度向上に効果的とされています。
コンテンツの最後には、チャンネル登録の呼びかけや高評価のお願い、コメント投稿の促進など、エンゲージメント向上のための要素を含めることで、より効果的なコンテンツマーケティングが可能になります。
おわりに
Google AI StudioのNative Speech Generation機能は、コンテンツ制作の可能性を大きく広げる革新的なツールです。無料で利用できるにも関わらず、商用レベルの高品質な音声コンテンツを生成できることは、個人クリエイターから企業まで、あらゆるコンテンツ制作者にとって大きなメリットとなります。台本を用意するだけで、まるで人間同士が自然に会話しているような音声を生成できる技術は、まさに現在のAI技術の進歩を象徴するものと言えるでしょう。この機能を活用することで、YouTubeコンテンツ、ポッドキャスト、インスタグラム投稿、企業のマーケティング資料など、様々な用途での音声コンテンツ制作が格段に効率化されます。今後のアップデートにより、さらに多くの話者への対応や、より長時間の音声生成が可能になることも期待されており、コンテンツ制作の未来はさらに明るいものとなりそうです。ぜひこの機会に、Google AI StudioのNative Speech Generation機能を試して、あなたのコンテンツ制作に新たな可能性を見出してください。
よくある質問(Q&A)
Q1: Google AI StudioのNative Speech Generation機能は完全に無料で使用できますか? A1: はい、現在のところGoogle AI StudioのNative Speech Generation機能は無料で利用することができます。Googleアカウントがあれば誰でもアクセス可能で、商用利用も含めて費用は発生しません。ただし、将来的に使用制限や有料化される可能性もあるため、利用規約を定期的に確認することをお勧めします。
Q2: 生成できる音声の長さに制限はありますか? A2: 現在、一度に生成できる音声の長さは約5分20秒が上限となっています。それ以上長い台本を用意しても、途中で音声生成が停止してしまいます。長いコンテンツを作成したい場合は、複数のセクションに分けて生成し、後から結合する方法をお勧めします。
Q3: 日本語以外の言語でも音声生成は可能ですか? A3: はい、Native Speech Generation機能は24以上の言語に対応しており、言語間のシームレスな切り替えも可能です。英語、中国語、韓国語など、主要な言語での音声生成が可能で、一つの会話の中で複数の言語を混在させることもできます。
Q4: 生成された音声ファイルの著作権や商用利用について教えてください。 A4: 生成された音声ファイルについては、Googleの利用規約に従って利用する必要があります。現在のところ、個人利用や商用利用も可能とされていますが、具体的な権利関係については利用規約を詳しく確認し、必要に応じて法的な助言を求めることをお勧めします。また、台本の内容についても、第三者の著作権を侵害しないよう注意が必要です。
Q5: 音声の品質を向上させるためのコツはありますか? A5: 音声品質を向上させるためには、まず台本の作り込みが重要です。自然な会話の流れを意識し、感情表現や相槌を適切に配置することで、より人間らしい音声が生成されます。また、漢字の読み間違いを防ぐため、固有名詞や専門用語はひらがなやカタカナで表記することをお勧めします。話者の設定も詳細に行い、キャラクターに応じた適切な声質を選択することで、より魅力的なコンテンツになります。
詳しくは15分の動画で解説しました。
https://www.youtube.com/watch?v=kwJMrjm7ESI

0:00 📱 導入・今日のテーマ紹介
0:47 🎤 Google Gemini 2.5のTTS機能説明
1:57 🎧 実際の音声サンプル再生
3:03 🆓 無料版での利用開始方法
4:03 ⚙ モデル設定とスピーカー選択
5:12 📝 台本構造の理解と作成準備
6:19 👥 キャラクター設定とシナリオ作成
7:26 ✍ 具体的な台本作成プロセス
8:35 📋 生成された台本の確認と調整
9:44 🎭 スピーカー設定と音声選択
10:53 🔧 最終調整と実行準備
12:00 🎬 実際の音声生成と再生
13:25 📊 生成結果の評価と改善点
14:32 🎯 活用方法とまとめ
上記の動画はYouTubeメンバーシップのみ
公開しています。詳しくは以下をご覧ください。
https://yokotashurin.com/youtube/membership.html
YouTubeメンバーシップ申込こちら↓
https://www.youtube.com/channel/UCXHCC1WbbF3jPnL1JdRWWNA/join
Google AI Stuidoで2人の会話を台詞テキスト読み上げ音声合成
🤖 Google AI Studio
GoogleのAI開発プラットフォームで、音声生成機能Native speech generationを提供。無料版でも利用可能で、テキストから自然な日本語音声会話を生成できる革新的なツールです。ユーザーは台本を作成するだけで、複数の話者による表現豊かな音声コンテンツを制作できます。
🎤 Native speech generation
Google AI Studioの音声生成機能で、複数話者による自然な音声会話を生成可能。従来のテキスト読み上げとは異なり、ささやき声などの微細なニュアンスも表現でき、24以上の言語に対応し、言語間のシームレスな切り替えも実現しています。
💎 Gemini 2.5 Pro/Flash
Googleの最新AI言語モデルで、TTS(テキスト読み上げ)機能を搭載。表現力豊かな音声出力により、自然な対話を実現します。台本作成時の原稿生成にも活用でき、指定した形式に合わせたコンテンツを効率的に作成できる優れたAIアシスタントです。
👥 Multi-speaker audio
複数話者による音声生成モードで、現在は2人までの対話に対応。将来的には3人以上の会話も可能になる予定です。各話者に異なる声質や性格を設定でき、リアルな対話シーンを音声で再現できる画期的な機能として注目されています。
📝 台本作成
Geminiを活用した効率的な会話台本の生成方法。キャラクター設定(性格、年齢、性別など)と会話内容を指定することで、Google AI Studioの形式に適合した台本を自動生成。手動での台本作成の手間を大幅に削減し、クオリティの高いコンテンツ制作を可能にします。
⏱️ 5分制限
現在の技術制約により、音声生成は約5分20秒が上限。それ以上長い内容は途中で切れてしまうため、台本作成時は5分程度の長さで依頼することが推奨されています。この制限内でも十分に充実したコンテンツを制作できる実用的な時間設定です。
🎯 キャラクター設定
音声生成の品質向上のため、各話者に詳細な人物設定を行う重要なプロセス。性格(明るい、優しい、好奇心旺盛など)、属性(年齢、職業など)、話し方の特徴を明確に定義することで、より自然で魅力的な音声対話を実現できます。
📺 コンテンツ活用
生成した音声は、YouTube、ポッドキャスト、Instagram、TikTokなど様々なプラットフォームで活用可能。特にSNSでの情報発信や教育コンテンツ、エンターテイメント分野での応用が期待され、個人や企業のコンテンツマーケティングに革新をもたらす可能性があります。
🔧 Voice settings
各話者の声質や話し方を細かく調整できる機能。複数の声のオプションから選択でき、キャラクターに最適な音声を設定可能。この設定により、より個性的で魅力的な音声キャラクターを作成でき、聞き手の印象に残るコンテンツ制作が実現できます。
🆓 無料利用
Google AI Studioの大きな魅力の一つは、無料版でもNative speech generation機能が利用できること。個人クリエイターや小規模事業者でも気軽にプロフェッショナル品質の音声コンテンツを制作でき、コンテンツ制作の民主化を促進する画期的なサービスです。
超要約1分ショート動画こちら↓
https://www.youtube.com/shorts/S7KpvTVBOtA

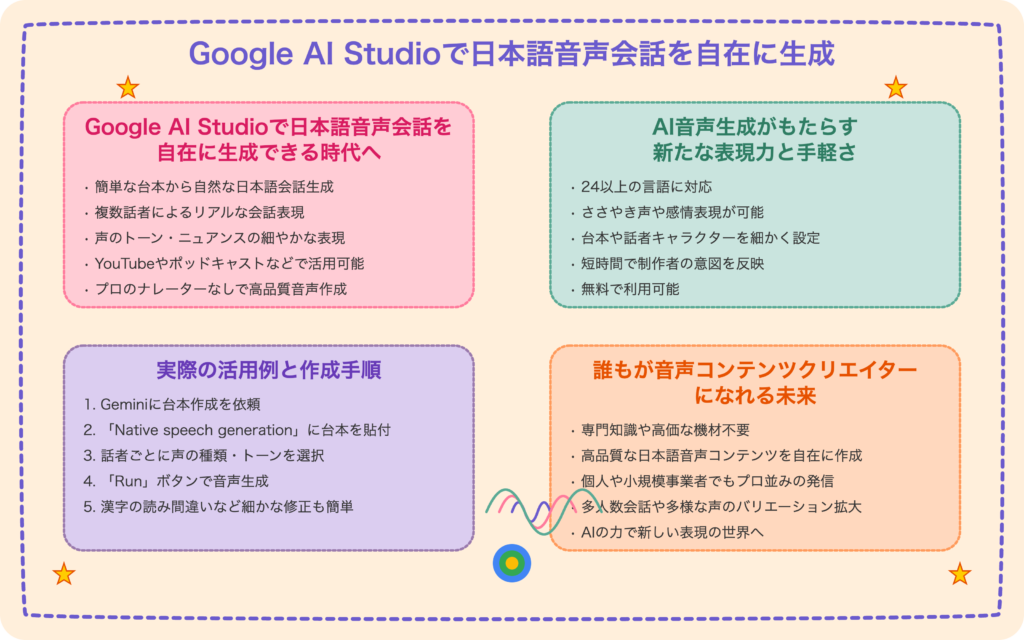
Google AI Studioで日本語音声会話を自在に生成できる時代へ
Google AI Studioの「Native speech generation」機能は、日本語音声コンテンツ制作に革命をもたらしています。台本から自然で高品質な複数話者音声会話を、声のトーンやニュアンスまで調整し、プロへの依頼不要、無料かつ短時間で生成可能です。これにより、YouTubeやポッドキャストなど多様なメディアで活用できるコンテンツ制作が手軽になり、漢字の読み間違いなどの修正も容易です。専門知識や高価な機材なしに、個人や小規模事業者でもプロ並みの音声コンテンツを発信できるようになり、誰もが音声コンテンツクリエイターになれる新しい表現の時代が到来します。
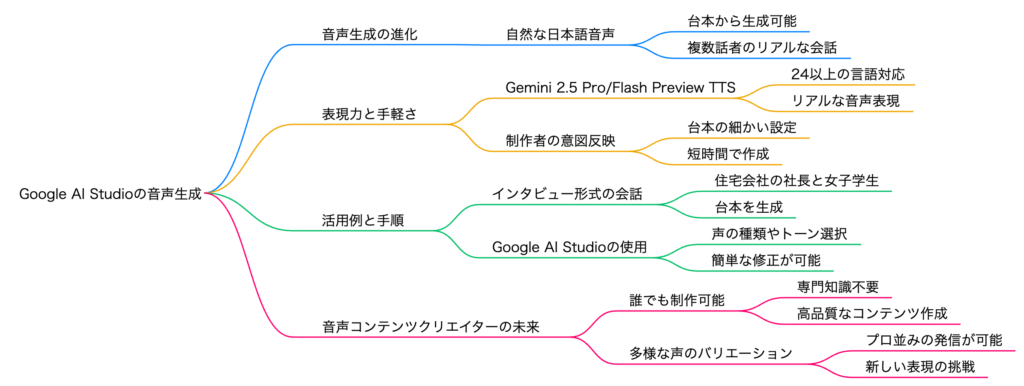
1. AI音声生成がもたらす新たな表現力と手軽さ
Google AI Studioの「Native speech generation」機能は、日本語の音声コンテンツ制作に革新をもたらしています。この機能を使えば、事前に用意された台本から、驚くほど自然な日本語の音声会話を生成することが可能です。単一話者だけでなく、複数話者によるリアルな会話も実現し、まるで実際に人が話しているかのような臨場感を生み出します。さらに、声のトーンやニュアンスといった細かな表現まで調整できるため、感情のこもった物語の朗読から、情報伝達のための冷静なナレーション、さらにはキャラクター性を持たせた会話劇まで、多様な表現ニーズに対応できます。
この技術の登場により、これまでプロのナレーターや声優に依頼しなければ得られなかった高品質な音声コンテンツが、誰でも手軽に制作できるようになりました。特筆すべきは、その手軽さにあります。Google AI Studioは無料で利用でき、数分の音声コンテンツであれば短時間で生成が完了します。これにより、多額の費用や時間をかけずに、YouTube動画、インスタグラムのリール、ポッドキャスト、企業のプロモーション用音声、e-ラーニング教材など、幅広いメディアで活用できるコンテンツ制作が、より身近なものとなるでしょう。時間やコストの制約から音声コンテンツの導入を躊躇していた個人や中小企業にとって、これはまさに画期的な変化と言えます。
2. 実際の活用例と作成手順
Google AI Studioの「Native speech generation」機能は、その高い汎用性から多岐にわたる音声コンテンツの制作に応用可能です。具体的な活用例として、住宅会社の社長と女子学生のインタビュー形式の会話を考えてみましょう。まず、Google GeminiなどのAIアシスタントに依頼して、対談形式の台本を作成します。台本が完成したら、それを「Native speech generation」のインターフェースに貼り付けます。次に、台本内の話者ごとに、声の種類(男性、女性、子供など)やトーン(明るい、落ち着いた、力強いなど)を細かく選択します。数多くのバリエーションの中から最適な声を選ぶことで、よりリアルで説得力のある会話を演出できます。
これらの設定が完了したら、「Run」ボタンを押すだけで、瞬時に指定した台本通りの音声ファイルが生成されます。生成された音声コンテンツは、YouTubeの動画、インスタグラムのストーリーズやリール、さらにはポッドキャストの番組など、多様なメディアで活用できます。さらに、生成された音声に漢字の読み間違いや不自然なイントネーションがあった場合でも、台本の一部を修正し再度生成するだけで、細かな修正が簡単に可能です。このような手軽な修正プロセスは、コンテンツ制作における試行錯誤の自由度を高め、クリエイターの創造性を大きく後押しします。
3. 誰もが音声コンテンツクリエイターになれる未来
Google AI Studioの登場は、音声コンテンツ制作のあり方を根本から変え、誰もが音声コンテンツクリエイターになれる未来を拓いています。これまでは、高品質な音声コンテンツを制作するには、専門的な録音機材の購入や、音声編集の高度な専門知識が必要でした。しかし、「Native speech generation」機能は、これらの障壁を完全に払拭します。インターネットに接続されたデバイスさえあれば、専門知識や高価な機材がなくても、誰でも簡単にプロ並みの日本語音声コンテンツを作り出せるようになりました。
この技術の進化は、特に個人クリエイターや小規模事業者にとって大きな福音です。プロのナレーターや声優に依頼する費用や時間的な制約なしに、プロ並みの品質を持つ音声コンテンツを自らの手で生成し、発信することが可能になります。複数人の会話や、多様な声のバリエーションにも柔軟に対応できるため、物語性のあるコンテンツから、企業のプレゼンテーション、教育コンテンツ、さらには個人の趣味としての朗読など、表現の幅は無限に広がります。これまで映像やテキスト表現が中心だった個人や事業者が、音声という新しい表現の世界に気軽に挑戦し、より多くの人々に自らのメッセージやアイデアを届けることができる時代が、今まさに到来しています。
#Gemini #GoogleAIStudio #横田秀珠 #Geminiセミナー #Geminiコンサルタント #Gemini講座 #Gemini講習 #Gemini講演 #Gemini講師 #Gemini研修 #Gemini勉強会 #Gemini講習会