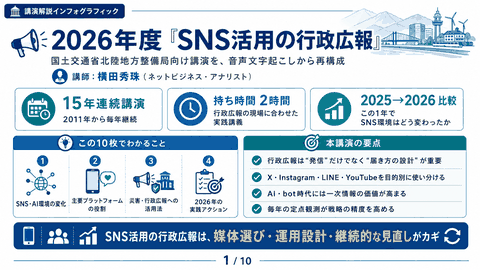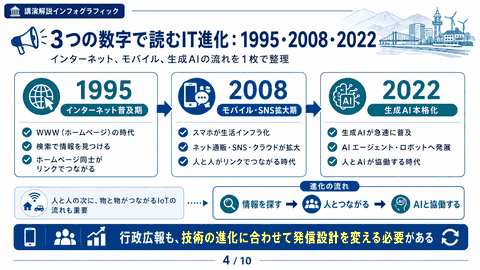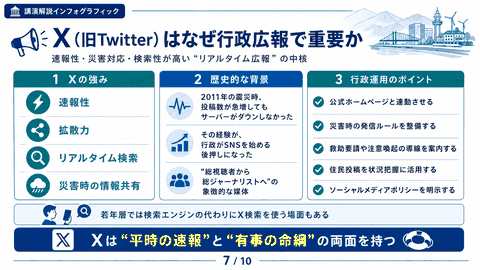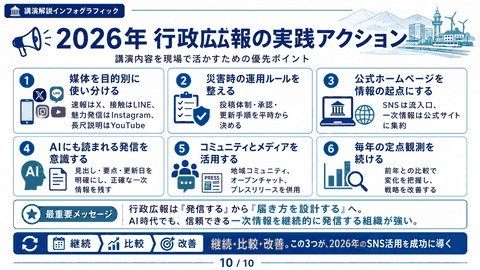
ChatGPT画像生成AIモデルのGPT-Image1とMicrosoftの互換性

米沢牛の握りに感動してる
瞬間(笑)美味かったです!
イーンスパイアの横田です。
https://www.enspire.co.jp

さて、本題です。
2025年7月に、ようやくMicrosoftの
Bing Image CreatorがDAL-LE3から
GPT-Image1に切替が完了しました。
OpenAI「ChatGPT」
https://chatgpt.com/
Microsoft「Copilot」
https://copilot.microsoft.com/
Microsoft「Bing Image Creator」
https://www.bing.com/images/create
I ❤️ IMG「画層のサイズ変更」
https://www.iloveimg.com/ja/resize-image
佐藤たかあき氏 4コマ漫画の制作事例
https://x.com/hatarakumeisi
GPT Image-1活用事例
https://chatgpt.com/share/e/6893fd39-5cbc-8007-9303-fe20b2fb88bb
それに合わせて色々と振り返りました。
https://www.youtube.com/watch?v=Z3iv2p8f-pk
ChatGPT画像生成AIモデルのGPT-Image1とMicrosoftの互換性
🚀 MicrosoftのAI画像生成が大進化!GPT-Image-1でビジネス活用
📰 重要アップデート情報
2025年3月の大きな変化
DALL-E3 から GPT-Image-1 へ完全移行!
ChatGPT、Bing Image Creator、Microsoft Copilotすべてで新エンジン採用
従来モデル 🏠
DALL-E3
限定的な画像生成機能
DALL-E3
限定的な画像生成機能
新モデル 🔥
GPT-Image-1
高度な画像編集・合成機能
GPT-Image-1
高度な画像編集・合成機能
⬇️ 進化のタイムライン ⬇️
⏰ アップデート履歴
2025年3月 – ChatGPTがGPT-Image-1に移行
2025年6月頃 – Microsoft Video Creator紹介時はまだDALL-E3
2025年8月現在 – Bing Image Creator、Copilotも完全移行
🎯 GPT-Image-1でできること
バナー画像の人物差し替え
左のバナーを右の人に差し替えて作成
左のバナーを右の人に差し替えて作成
服装の変更
人物の服装を別の画像の服に変更
人物の服装を別の画像の服に変更
家具配置シミュレーション
空の部屋におしゃれな家具を配置
空の部屋におしゃれな家具を配置
土地活用イメージ
土地に建物を合成してイメージ作成
土地に建物を合成してイメージ作成
💡 ビジネス活用のポイント
不動産業界では空室に家具を配置した「ホームステージング」風の画像で、お客様により具体的なイメージを提供できる
不動産業界では空室に家具を配置した「ホームステージング」風の画像で、お客様により具体的なイメージを提供できる
⚠️ 現在の制約事項
- 人物の顔の再現精度がまだ不十分
- 文字の再現・編集機能が限定的
- 16:9指定でも3:2で出力されることがある
- チラシの内容変更は現状困難
🔧 対策方法
画像サイズ変更は「I ❤️ IMG」サービス活用
Canvaのマジック拡張で余白部分を補完
画像サイズ変更は「I ❤️ IMG」サービス活用
Canvaのマジック拡張で余白部分を補完
📝 実用的な活用例
1
ブログ記事のイメージ画像生成
2
サムネイル画像をブログURLから自動生成
3
YouTubeサムネイルテンプレート作成
4
4コマ漫画の制作も可能
🎨 佐藤たかあきさんの事例
GPT-Image-1を活用した高品質な4コマ漫画制作
Twitterで多数の作品を公開中
🔧 各プラットフォームの特徴
Bing Image Creator 🎯
• GPT-4o & DALL-E3選択可能
• 1:1サイズ、1枚生成
• DALL-E3なら4枚生成可能
• GPT-4o & DALL-E3選択可能
• 1:1サイズ、1枚生成
• DALL-E3なら4枚生成可能
Microsoft Copilot 🚀
• 無制限に近い画像生成
• 高品質なサムネイル作成
• 文字入りデザインも得意
• 無制限に近い画像生成
• 高品質なサムネイル作成
• 文字入りデザインも得意
🏆 おすすめの使い分け
凝った作品やガチャ要素の高い4コマ漫画制作には、制限の少ないMicrosoft Copilotがおすすめ
凝った作品やガチャ要素の高い4コマ漫画制作には、制限の少ないMicrosoft Copilotがおすすめ
💼 ビジネス活用のメリット
- 時短効果 – 素材作成時間の大幅短縮
- コスト削減 – 外注費用の削減
- 表現力向上 – 言葉では伝えにくいイメージの視覚化
- 無料活用 – Microsoftツールで制限なし利用
- 柔軟性 – アイデア次第で無限の可能性
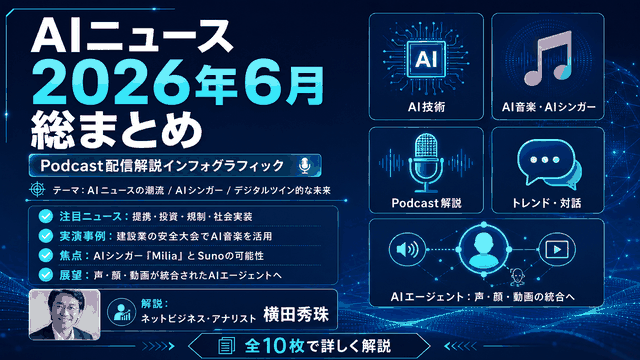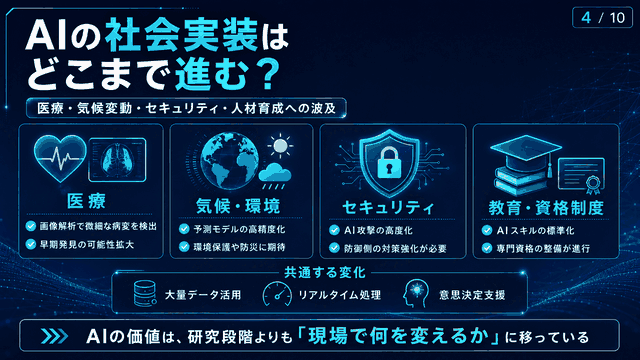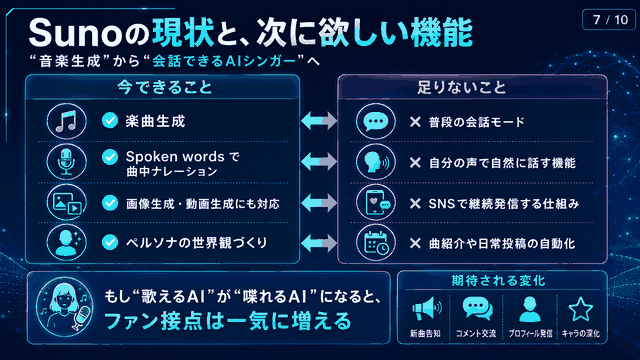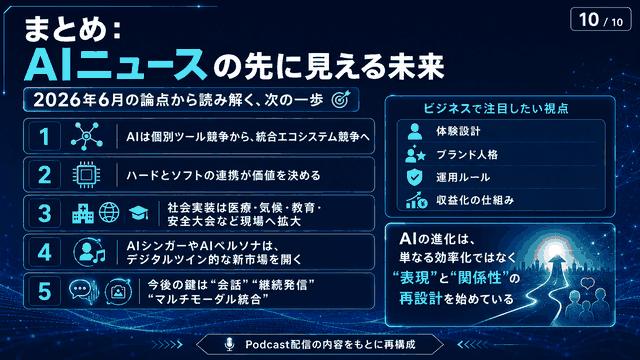
ChatGPT画像生成AIモデルのGPT-Image1とMicrosoftの互換性
MicrosoftのBing Image CreatorとCopilotの画像生成AIが、従来のDALL-E3からGPT-Image-1に切り替わりました。GPT-Image-1では不動産のイメージ画像作成やサムネイル生成など、ビジネス活用に適した機能が向上しました。ただし顔の再現や文字の正確な表示には限界があります。Microsoft版は無料で制限が少なく、4コマ漫画作成なども可能。Canvaのマジック拡張と組み合わせることで、より実用的な画像制作ができるようになりました。
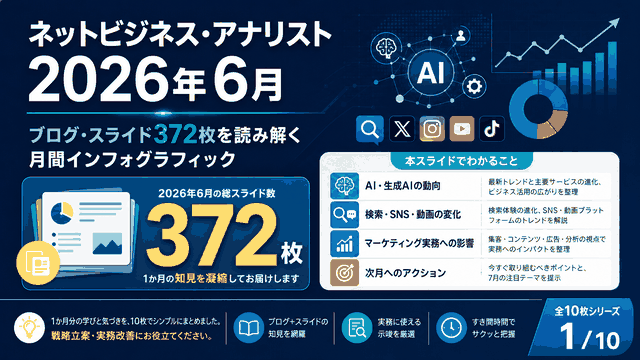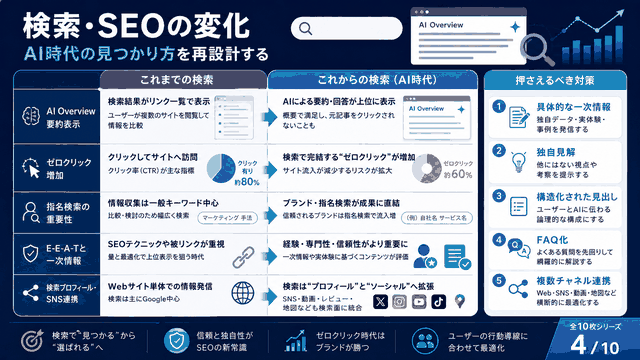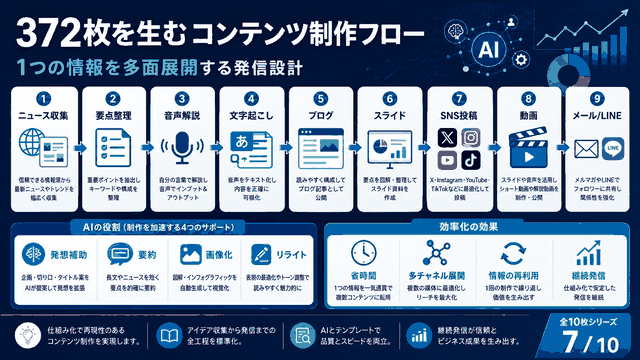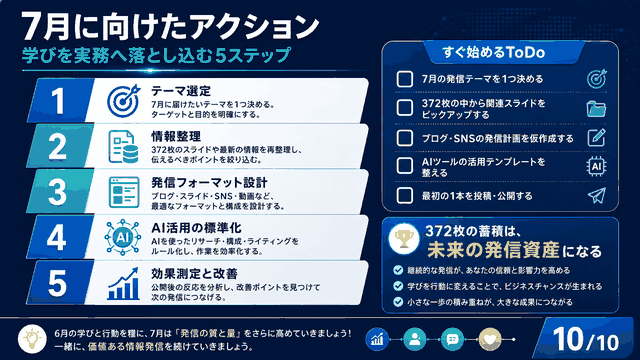
- はじめに
- GPT Image-1への大幅アップデート!画像生成AIの新時代到来
- 驚きの実演!GPT Image-1で実現する革新的な画像編集機能
- 知っておきたい限界と解決策:より効果的な活用のために
- ビジネスで差をつける!GPT Image-1の実践的活用法
- おわりに
はじめに
2025年8月14日現在、AI技術の進歩は私たちの想像を超えるスピードで進化し続けています。特に画像生成AI分野では、まさに革命的な変化が起こっています。今回ご紹介するのは、MicrosoftのBing Image CreatorがついにGPT Image-1に切り替わったという、見逃せない重要なアップデートです。これまでDAL-LE3を使っていた方も、初めて画像生成AIに触れる方も、この変化によってビジネスや創作活動が大きく変わる可能性があります。本記事では、実際の使用例から限界、そして解決策まで、網羅的にお伝えしていきます。画像生成AIの新時代を迎えた今、ビジネスでの活用方法を具体的に理解し、実践に活かしていただければと思います。
GPT Image-1への大幅アップデート!画像生成AIの新時代到来
2025年8月14日、画像生成AI分野において重要な転換点を迎えました。MicrosoftのBing Image CreatorがChatGPTの画像生成AIモデルをGPT-Image-1へと切り替えたのです。この変更は単なるアップデートを超えて、私たちの画像生成体験を根本的に変革する可能性を秘めています。
従来、ChatGPTではDAL-LE3というモデルを使用して画像編集や生成を行っていました。しかし、2025年3月のアップデートにより、DAL-LEモデルから新しいGPT Image-1へと移行が行われました。当初は「4o-Image Generation」という名称で呼ばれることもありましたが、現在は正式にGPT-Image-1として統一されています。今後はImage-1、Image-2という形で連番でのバージョン管理が行われると予想されます。
興味深いことに、6月頃にMicrosoftのVideo Creatorを紹介した際、動画生成機能は既に新しいモデルが使用されていましたが、画像生成部分はまだDAL-LE3が動作していました。しかし現在では、この部分も完全にGPT Image-1へと切り替わっています。
さらに注目すべき点として、MicrosoftのCopilotの画像生成機能も同様にGPT-Image-1に移行しています。これにより、Microsoft製品全体での画像生成機能が統一され、より一貫した体験を提供できるようになりました。
ただし、Bing Image Creatorの表記において、まだ「DAL-LE3」と「GPT-4o」という表示が残っている場合があります。これは初期の「4o Image Generation」という名称の名残りと考えられますが、実際の機能としてはGPT Image-1が動作していると理解していただければと思います。
驚きの実演!GPT Image-1で実現する革新的な画像編集機能
GPT Image-1の登場により、従来では不可能だった高度な画像編集が可能になりました。ここでは実際の使用例を通して、その驚異的な機能をご紹介します。
人物画像の差し替え機能
まず注目すべきは、既存のバナー広告などの画像において人物の差し替えが可能になったことです。例えば、スポーツ選手が写っているバナー広告に対して、「左のバナー画像を右の人に差し替えて作って」という指示を出すことで、新しい人物に置き換えた画像を生成できます。ただし、この機能には限界があり、完全に同じ顔を再現することは現時点では困難です。結果として生成される人物は、元の人物とは異なる顔になってしまうことが多いのが現状です。
服装の変更機能
衣装の変更についても興味深い結果が得られます。「左の画像に映っている人に右の画像で着ている人の服を着させて」という指示を出すことで、確かに服装は変更されますが、やはり顔の部分は別人になってしまいます。この現象は、現在のGPT Image-1における人物再現の技術的限界を示しています。
空間への家具配置とライフスタイル提案
最も実用的で革新的な機能の一つが、空の住宅空間に家具を配置し、実際に人が住んでいるような雰囲気を作り出すことです。工務店などで完成見学会を行う際、まだ家具が入っていない状態の写真に対して、「おしゃれな感じの家具を配置して、部屋でくつろいでいる日本人の若い夫婦をリアルな写真で描いて」という指示を出すことで、驚くほどリアルな居住空間のイメージを作成できます。
この機能の優れた点は、ターゲット層に応じてカスタマイズできることです。若い夫婦向け、年配夫婦向け、子供がいる家庭向け、ペットを飼っている家庭向けなど、様々なライフスタイルに対応したイメージ画像を作成できます。従来、お客様は頭の中でイメージを膨らませるしかありませんでしたが、視覚的に具体化することで、より強い印象を与えることが可能になります。
建築・不動産業界での活用
建築や不動産業界においても実用的な活用例があります。「左の土地に右の家が立っているイメージの画像を作って」という指示により、実際の土地にプランの建物を配置したビジュアルを作成できます。パンフレットに掲載されている建物を、お客様が購入予定の具体的な土地に合成することで、完成後のイメージをより明確に伝えることができます。
現在の技術的限界
しかし、現在のGPT Image-1にも明確な限界があります。チラシの人物写真を差し替えたり、文字情報を正確に変更したりすることは困難です。文字の再現性や本人そのものの再現性において、まだ技術的な課題が残っています。これらの限界を理解した上で、適切な用途での活用が重要です。
知っておきたい限界と解決策:より効果的な活用のために
GPT Image-1は確かに革新的な機能を提供しますが、効果的に活用するためには現在の限界を理解し、適切な対処法を知っておく必要があります。
ブログ記事用イメージ画像の生成
ブログ記事やSNS投稿用のイメージ画像作成において、GPT Image-1は非常に有効です。例えば、「買い物したのを忘れてまた同じものを買ってしまった」というテーマの記事に対して、そのままの文章を入力することで、適切なイメージ画像を生成できます。このような直感的な使い方により、記事の内容を視覚的に表現することが可能になります。
サムネイル画像の自動生成
さらに高度な機能として、ブログのURLを指定してサムネイル画像を作成することができます。「このブログに最適なサムネイル画像を16対9の横向きで作って」という指示とともにブログのアドレスを入力すると、GPT Image-1がそのページの内容を解析し、適切なサムネイル画像を提案してくれます。例えば、アニメ画像のAI生成に関するブログであれば、その内容を反映したデザインのサムネイルが自動生成されます。
縦横比の問題と解決策
ただし、GPT Image-1には縦横比に関する課題があります。16対9での作成を指定しても、実際には異なる比率で出力されることがあります。また、画像の左右で余白のバランスが崩れることも頻繁に発生します。
この問題に対する解決策として、Canvaのマジック拡張機能の活用があります。GPT Image-1で基本的な画像を生成した後、Canvaに取り込んで余白部分を自動的に拡張することで、バランスの取れた画像に仕上げることができます。この組み合わせ技により、GPT Image-1の限界を補完できます。
Microsoft Copilotとの比較活用
興味深いことに、同じ指示をMicrosoft Copilotで実行すると、より良い結果が得られる場合があります。同一のブログURLを使用してサムネイル画像を作成した場合、Copilotの方がタイトルを適切に配置し、画像の見切れも少ない結果を出力することがあります。そのため、用途に応じてGPT Image-1とCopilotを使い分けることが効果的です。
YouTubeサムネイル作成の高度な活用法
YouTubeサムネイル作成においては、より戦略的なアプローチが可能です。まず自分の写真を撮影し、「YouTubeのタイトルという内容のタイトルデザインを生成してください。光沢を出してポップでリッチなデザインにして、YouTubeサムネイルでの使用に適したテンプレート写真をイラストにして、16対9の画像にしてください。画像の上下左右には文字を入れずに作成してください」という詳細な指示を出します。
この手法により、実際の写真をベースにしたイラスト風のサムネイルを作成し、そこに適切なタイトルデザインを組み合わせることができます。このような組み合わせ技術により、プロフェッショナルな品質のサムネイルを効率的に作成できます。
画像サイズ調整の実用的解決法
GPT Image-1で16対9の指定をしても実際には3対2で出力されるという問題については、I ❤️ IMGのような画像リサイズサービスの活用が有効です。縦横比を維持せずに1280×720ピクセルで強制的にリサイズすることで、多少の歪みは生じるものの、必要な縦横比を確保できます。
時間効率を重視する場合、完璧な品質よりも実用性を優先し、このような割り切った手法を採用することが推奨されます。画像生成の目的が時間短縮にある以上、後処理に時間をかけすぎては本末転倒になってしまうためです。
ビジネスで差をつける!GPT Image-1の実践的活用法
GPT Image-1の真価は、実際のビジネスシーンでの活用において発揮されます。ここでは、具体的な活用事例と推奨される使用方法をご紹介します。
4コマ漫画制作の可能性
GPT Image-1を使いこなすことで、4コマ漫画の制作も可能になります。実際の受講生である佐藤たかあきさんの事例では、非常に高品質な4コマ漫画を継続的に制作し、X(旧Twitter)で発信されています。このような創作活動は、ブランディングやコンテンツマーケティングの観点からも非常に価値があります。
4コマ漫画制作には試行錯誤が必要で、セリフの指示や構図の調整など、複数回の生成が必要になることが多いです。そのため、生成回数に制限があるサービスでは限界があります。
Microsoft製品での無制限活用
ここで重要になるのが、Microsoft製品の活用です。ChatGPTの無料プランでは1日数枚という生成制限がありますが、Microsoft製品(Bing Image CreatorやCopilot)を使用することで、ほぼ無制限に画像生成を行うことができます。これにより、より凝った作品制作や大量の画像生成が必要なプロジェクトにも対応できます。
Bing Image Creatorの特徴と活用法
Bing Image Creatorでは、GPT-4oとDAL-LE3のモデルを選択できる機能が提供されています。ただし、このツールの制約として、縦横比が1対1でしか作成できず、生成枚数も1枚に限定されています。しかし、無料で使用でき、おそらく生成制限もかからないため、気軽に試すことができます。
興味深いことに、DAL-LE3モデルを選択した場合は4枚同時生成が可能です。縦横比は1対1に限定されますが、多数の候補から最適なものを選択したい場合には、こちらのオプションが有効です。
Microsoft Copilotでの画像生成
Microsoft Copilotでも同様の画像生成機能が利用できます。画面下部の「画像を作成する」ボタンをクリックすることで、「以下の画像を作成してください」という入力フィールドが表示され、そこに具体的な指示を入力することで画像生成が可能です。
推奨される活用戦略
実用的な活用を考える場合、以下の戦略が推奨されます:
- 初期テストはChatGPTで行う – 基本的な動作確認や簡単な画像生成
- 本格的な制作はMicrosoft製品を活用 – 大量生成や繰り返し作業が必要な場合
- 品質重視の場合は複数サービスで比較 – 同じ指示で複数のサービスを試し、最適な結果を選択
- 後処理ツールとの組み合わせ – CanvaやI ❤️ IMGなどのツールで最終調整
ビジネス分野別活用例
- 不動産・建築業界: 物件の完成イメージ、ライフスタイル提案画像
- 小売・EC業界: 商品使用シーン、ライフスタイル画像
- コンテンツマーケティング: ブログ記事用画像、SNS投稿用ビジュアル
- 教育・研修: 説明用図解、ケーススタディ画像
- イベント・宣伝: ポスター素材、チラシ用画像
これらの活用により、従来は外注や専門スタッフが必要だった画像制作を、大幅にコストダウンしながら内製化することが可能になります。
おわりに
GPT Image-1への移行は、単なる技術的なアップデートを超えて、私たちのビジネス活動に根本的な変化をもたらす可能性を秘めています。従来では専門的なスキルや高額なソフトウェアが必要だった画像制作が、自然言語での指示だけで実現できるようになったことは、まさに革命的な変化といえるでしょう。
本記事でご紹介した様々な活用事例から分かるように、GPT Image-1は単純な画像生成ツールではなく、ビジネスの課題解決や顧客体験の向上に直接貢献できる実用的なソリューションです。不動産業界での物件イメージ提案、コンテンツマーケティングでの視覚的訴求力向上、そして日常業務での効率化まで、その応用範囲は非常に広範囲に及びます。
ただし、現在の技術には限界もあることを理解し、適切な用途での活用と、必要に応じた他ツールとの組み合わせが重要です。完璧を求めるのではなく、「十分に実用的」なレベルでの活用を心がけることで、大幅な業務効率化とコスト削減を実現できるでしょう。Microsoft製品での無制限利用により、これらの技術をコストを気にすることなく存分に活用できる環境が整いました。ぜひ皆様のビジネスシーンにおいて、この新しい技術を積極的に取り入れ、競争優位性の確立にお役立てください。
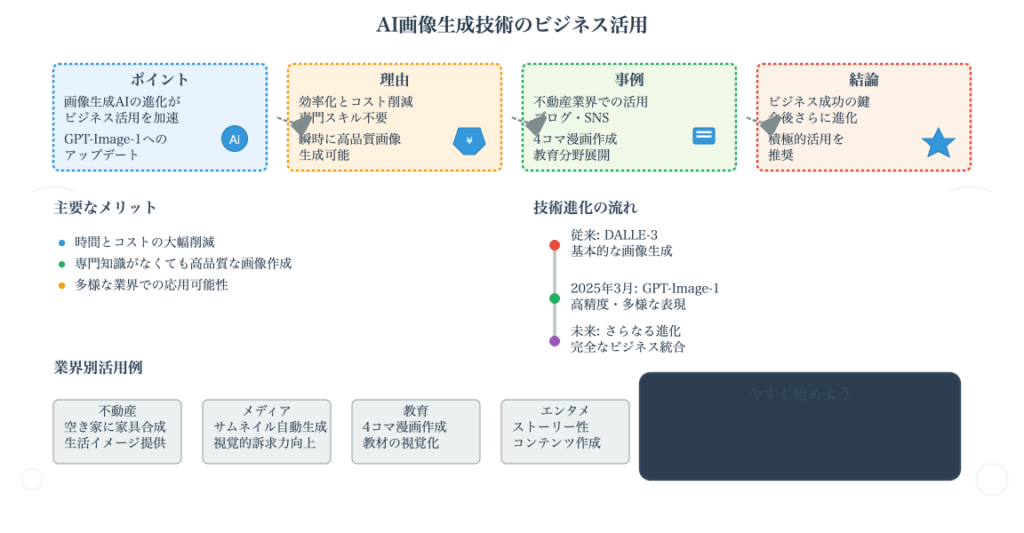
よくある質問(Q&A)
Q1: GPT Image-1とDAL-LE3の主な違いは何ですか?
A1: GPT Image-1は従来のDAL-LE3と比較して、より自然言語での指示理解能力が向上し、複雑な画像編集や既存画像との組み合わせ処理が可能になりました。特に、複数の画像を組み合わせた指示や、具体的なシーン設定での画像生成において大幅な性能向上が見られます。また、より現実的な人物や空間の描写が可能になっている点も大きな特徴です。
Q2: 無料で画像生成を大量に行いたい場合、どのサービスを使うべきですか?
A2: Microsoft製品(Bing Image CreatorやCopilot)の利用を強く推奨します。ChatGPTの無料プランでは1日数枚の制限がありますが、Microsoft製品ではほぼ無制限に画像生成が可能です。特に4コマ漫画制作や大量の商品画像生成など、繰り返し作業が必要な場合には、この無制限性が大きなアドバンテージとなります。
Q3: 生成された画像の縦横比が指定と異なる場合の対処法は?
A3: 2つの主要な解決策があります。1つ目はCanvaのマジック拡張機能を使用して不足部分を自動補完する方法、2つ目はI ❤️ IMGのようなリサイズサービスで強制的にピクセル指定でリサイズする方法です。品質を重視する場合は前者、効率を重視する場合は後者を選択することを推奨します。多少の歪みよりも時間効率を優先する場合が多いため、実際のビジネス利用では後者が選ばれることが多いです。
Q4: 人物の顔や文字を正確に再現することは可能ですか?
A4: 現在のGPT Image-1では、特定の人物の顔を正確に再現することや、文字情報を完璧に再現することは技術的に困難です。人物画像を差し替える際は別人の顔になってしまい、チラシなどの文字情報も正確には変更されません。これらの限界を理解した上で、雰囲気やコンセプトの伝達に重点を置いた活用方法を採用することが重要です。
Q5: ビジネス利用において最も効果的な活用シーンは何ですか?
A5: 不動産・建築業界での完成イメージ提案、コンテンツマーケティングでのブログ記事用画像生成、SNS投稿用ビジュアル制作が特に効果的です。従来は頭の中でイメージするしかなかった空間の活用例や、ライフスタイル提案を視覚化できることで、顧客の理解度と興味関心を大幅に向上させることができます。また、外注コストの削減と制作時間の短縮により、マーケティング活動の効率化も実現できます。
詳しくは15分の動画で解説しました。
https://www.youtube.com/watch?v=IFzU8f8Kv3k

0:00 📱 導入・今日のテーマ紹介
1:07 🔄 GPT-Image1への切り替えについて
2:16 🖥️ Microsoft Bing Image CreatorとCopilotの変更
3:17 🎨 GPT-Image1の実用例(バナー・顔写真差し替え)
4:25 🏠 家具配置とインテリアイメージ生成
5:34 🏘️ 土地活用とチラシ作成の応用例
6:44 ⚠️ GPT-Image1の現在の限界と課題
7:51 📝 ブログサムネイル自動生成の実演
8:57 ⚔️ ChatGPT vs Microsoft Copilot比較
10:04 🎬 YouTubeサムネイル作成テクニック
11:10 📐 画像サイズ調整の効率的な方法
12:15 📚 4コマ漫画作成の活用事例
13:22 💡 Microsoft製品での画像生成推奨理由
14:24 🎯 まとめ・ビジネス活用への提案
上記の動画はYouTubeメンバーシップのみ
公開しています。詳しくは以下をご覧ください。
https://yokotashurin.com/youtube/membership.html
YouTubeメンバーシップ申込こちら↓
https://www.youtube.com/channel/UCXHCC1WbbF3jPnL1JdRWWNA/join
ChatGPT画像生成AIモデルのGPT-Image1とMicrosoftの互換性
🤖 GPT-Image-1 ChatGPTの最新画像生成AIモデルで、2025年3月にDALL-E3から切り替わりました。当初は4o-Image Generationと呼ばれていましたが、正式名称がGPT-Image-1に決定。画像の合成や編集機能が向上し、ビジネス用途での活用可能性が広がりました。今後Image-2などの連番での展開が予想されています。
🔍 Bing Image Creator Microsoftが提供する無料の画像生成ツールで、GPT-4oとDALL-E3のモデルを選択可能です。縦横比1対1の制約がありますが、無料で制限なく利用できる点が特徴。DALL-E3モデルでは4枚同時生成が可能で、複数の候補から選択できるガチャ的な使い方ができます。
🧠 Microsoft Copilot マイクロソフトのAIアシスタントサービスで、画像生成機能も搭載されています。GPT-Image-1に対応し、「画像を作成する」ボタンから簡単に画像生成が可能。ChatGPTの制限を受けずに、ほぼ無制限で画像生成ができるため、試行錯誤を重ねる作業に適しています。
🎨 画像生成AI テキストプロンプトから自動的に画像を作成する人工知能技術です。ビジネス用途では、バナー広告、サムネイル、イメージ画像の作成に活用できます。ただし現在の技術では、人物の顔の正確な再現や文字の組み込みには限界があり、用途に応じた使い分けが重要です。
💼 ビジネス活用 画像生成AIをビジネスシーンで実践的に使用することを指します。不動産の完成イメージ作成、商品のバナー広告、ブログのサムネイル生成など、従来は専門デザイナーが必要だった作業を効率化できます。コスト削減と作業時間の短縮を同時に実現する新しいワークフローとして注目されています。
📸 サムネイル作成 動画やブログ記事の表紙となる縮小画像の制作です。GPT-Image-1では、ブログのURLを入力するだけで内容に適したサムネイルを自動生成できます。16対9の横向き指定も可能で、YouTubeやブログ投稿に最適化された画像を効率的に作成できる機能として重宝されています。
📚 4コマ漫画 4つのコマで構成される短編漫画形式で、GPT-Image-1の高度な活用例として紹介されています。受講生の佐藤たかあきさんの作品が例として挙げられ、X(旧Twitter)で多数の作品を公開中。セリフの指示や構成に工夫が必要ですが、創作活動の新しい可能性を示しています。
🏷️ バナー広告 商品やサービスを宣伝するための横長の画像広告です。GPT-Image-1では既存のバナーに人物を差し替える機能がありますが、顔の再現精度には課題があります。それでも基本的なレイアウトや雰囲気の変更は可能で、マーケティング素材の制作効率化に貢献しています。
🎭 Canvaマジック拡張 Canvaが提供する画像編集機能の一つで、AIを使って画像の不足部分を自動的に補完・拡張します。GPT-Image-1で生成した画像の余白問題を解決する組み合わせ技として活用されています。画像の左右のバランス調整や、サイズ変更時の自然な背景拡張が可能です。
📐 縦横比調整 画像のアスペクト比を目的に応じて変更することです。GPT-Image-1は16対9指定でも3対2で出力される問題があるため、I ❤️ IMGなどのサービスを使用してピクセル指定での強制調整が推奨されています。時間効率を重視し、多少の歪みは許容する実用的なアプローチが提案されています。
超要約1分ショート動画こちら↓
https://www.youtube.com/shorts/ATCodbojjGU

ChatGPT画像生成AIモデルのGPT-Image1とMicrosoftの互換性
第1章 アーキテクチャの飛躍:GPT-Image-1の定義とDALL-E 3からの進化
人工知能による画像生成の分野は、急速な技術革新の連続であり、その最前線でOpenAIは常にベンチマークを更新し続けてきました。この進化の系譜を理解することは、最新モデルの能力と、それがMicrosoftのような巨大なエコシステムにどのように統合され、どのような価値をもたらすかを把握するための基礎となります。本章では、画期的なテキストからの画像生成モデルであったDALL-E 3の功績を振り返り、その後継として登場したGPT-Image-1が、単なる性能向上に留まらない、根本的なアーキテクチャの転換を意味するものであることを詳述します。この進化は、特殊化された単一目的のモデルから、テキスト、画像、その他のモダリティを統一的に扱うネイティブなマルチモーダルアーキテクチャへの移行という、より広範な業界トレンドを象徴しています。

1.1 DALL-Eの遺産:テキストからの画像生成における金字塔
DALL-E 3は、2023年9月にOpenAIによって発表され、それまでの画像生成モデルと比較して「著しく多くのニュアンスと詳細」を理解する能力を持つとされ、大きな注目を集めました 。その能力は、単に高解像度で美しい画像を生成するだけでなく、ユーザーの意図をより深く汲み取り、プロンプトに忠実な結果を出力する点にありました。
この成功の核心には、ChatGPTとのネイティブな統合がありました 。DALL-E 3は、単独の画像生成エンジンとして機能するのではなく、ChatGPTという強力な大規模言語モデル(LLM)と密接に連携するように設計されていました。ユーザーが単純なアイデアを投げかけると、ChatGPTが「ブレインストーミングのパートナーであり、プロンプトの洗練者」として機能し、より詳細で豊かな画像生成のためのプロンプトを自動的に生成しました 。この仕組みにより、プロンプトエンジニアリングの専門知識が少ないユーザーでも、意図した通りの複雑な画像を容易に作成できるようになったのです。この対話的なアプローチは、ユーザーエクスペリエンスを劇的に向上させ、生成される画像の品質と一貫性を高める上で決定的な役割を果たしました。
DALL-E 3が提供した主な機能は多岐にわたります。これには、向上した画質、プロンプトへの高い忠実度、画像内での読みやすいテキスト生成(タイポグラフィ)、正方形、縦長、横長といった複数のアスペクト比への対応、そして人間や動物の解剖学的構造のよりリアルな描写が含まれていました 。これらの機能は、クリエイティブな表現の幅を大きく広げました。
開発者向けには、2023年11月からAPI経由での提供が開始され、アプリケーションへの統合が可能になりました 。APIでは、生成される画像のスタイルを「vivid」(より写実的でドラマチック)または「natural」(より自然で写実的でない)から選択できる
styleパラメータや、画質を「standard」または「hd」(より細かいディテールと一貫性)から選択できるqualityパラメータなどが提供されました 。
しかし、DALL-E 3には明確な限界も存在しました。そのAPIは、テキストプロンプトから新しい画像を生成することに特化しており、既存の画像を編集する機能(インペインティングやアウトペインティングなど)をネイティブにサポートしていませんでした 。この点が、後継モデルである
GPT-Image-1との最も重要な差別化要因となります。
1.2 後継モデル:ネイティブなマルチモーダルモデルとしてのGPT-Image-1
GPT-Image-1は、DALL-Eシリーズの公式な後継モデルとして位置づけられており、ChatGPTにおける次世代の画像生成能力を担っています 。しかし、このモデルは単なるDALL-Eのバージョンアップではありません。その本質は、アーキテクチャの根本的な転換にあります。
GPT-Image-1は、DALL-Eのような独立した画像生成モデルではなく、より大きなネイティブなマルチモーダルアーキテクチャであるGPT-4oの一部として機能します 。これは、AI開発における重要なパラダイムシフトを示唆しています。従来の拡散モデル(diffusion model)ベースのアプローチとは異なり、
GPT-Image-1は自己回帰型(autoregressive)の「画像オートリグレッサー」を採用しています。これは、LLMがテキストをトークン単位で生成するのと同様に、画像をトークン(画像の小さなパッチ)単位で逐次的に生成する手法です 。このアーキテクチャにより、テキストの文脈や世界の知識を画像生成に緊密に結びつけることが可能になり、より複雑で首尾一貫した画像の生成が実現します。
このアーキテクチャの最も重要な帰結は、GPT-Image-1がテキスト入力だけでなく、画像入力も受け付けて画像を出力できるという点です 。このネイティブなマルチモーダル性が、DALL-E 3では不可能だった高度な編集機能を実現するための技術的基盤となっています。モデルが既存の画像を「見て」理解し、その上でテキストによる指示に従って修正を加えることができるのです。
1.3 GPT-Image-1の主要な能力向上点
GPT-Image-1は、その新しいアーキテクチャを基盤として、いくつかの重要な能力向上を実現しています。
第一に、プロンプトへの忠実度とテキストレンダリング能力の飛躍的な向上です。このモデルは「卓越したプロンプトへの忠実度、ディテールのレベル、そして品質」を提供すると評価されており 、画像内にテキストを正確かつ自然にレンダリングする能力は、旧世代のモデルが抱えていた大きな課題を克服するものです 。
第二に、そして最も革新的なのが、高度な編集機能のサポートです。GPT-Image-1は、既存の画像の編集、スタイルの変更、複数の画像の組み合わせをネイティブにサポートします 。具体的には、マスク(透明な領域)を使用して画像の特定領域を編集するインペインティングや、画像のキャンバスを外側に拡張するアウトペインティングといった機能が含まれます 。これらの機能は、モデルが画像入力を直接処理できるようになったことの直接的な恩恵であり、クリエイティブなワークフローを根本から変える可能性を秘めています。単にゼロから画像を生成するだけでなく、既存のビジュアルアセットを対話的に、かつプログラムを通じて改良していくという、新しい利用方法を切り拓きます。
第三に、APIレベルでのより詳細な制御が可能になった点です。GPT-Image-1のAPIでは、出力画像が入力画像の特徴をどの程度維持するかを制御するinput_fidelity(’low’または’high’)や、画像の背景を透明にするか不透明にするかを指定するbackground(’transparent’または’opaque’)といった、編集タスクに特化した新しいパラメータが導入されています 。
1.4 比較分析:アーキテクチャと能力
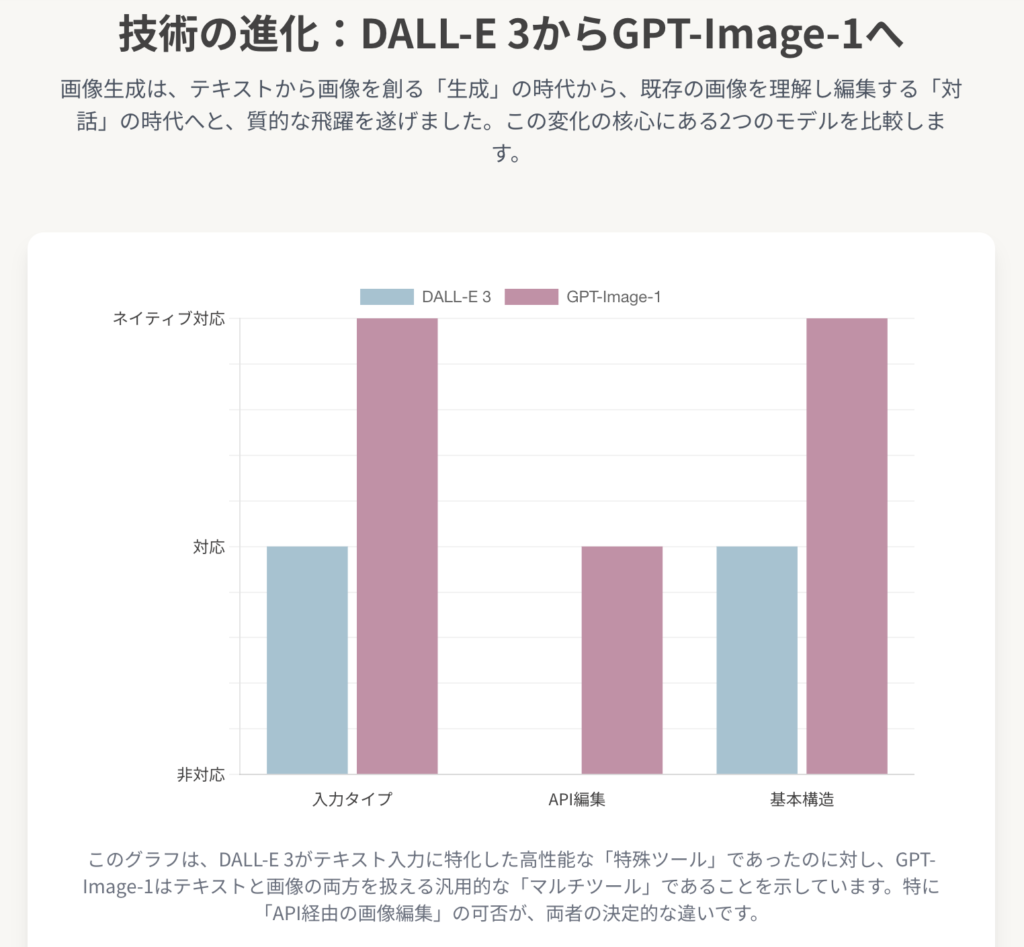
DALL-E 3とGPT-Image-1の違いは、単なる性能の差ではなく、その設計思想とアーキテクチャの根本的な違いに起因します。DALL-E 3は、テキストから画像を生成することに特化した、非常に高性能な「特殊ツール」でした。一方、GPT-Image-1は、テキストと画像を同等に扱うことができる、より汎用的で強力な「マルチツール」であるGPT-4oアーキテクチャの視覚的表現能力と言えます。
この進化は、AI開発のトレンドが、個別のタスクに特化したモデルを組み合わせるアプローチから、複数のモダリティを単一の統一されたフレームワーク内でシームレスに処理するネイティブなマルチモーダルシステムへと移行していることを明確に示しています。この統合されたアプローチは、開発の複雑さを軽減し、より高度なクロスモーダルタスク(例えば、会話の文脈全体を考慮して画像を編集する、など)を可能にし、最終的にはより直感的でシームレスなユーザーエクスペリエンスを生み出します。
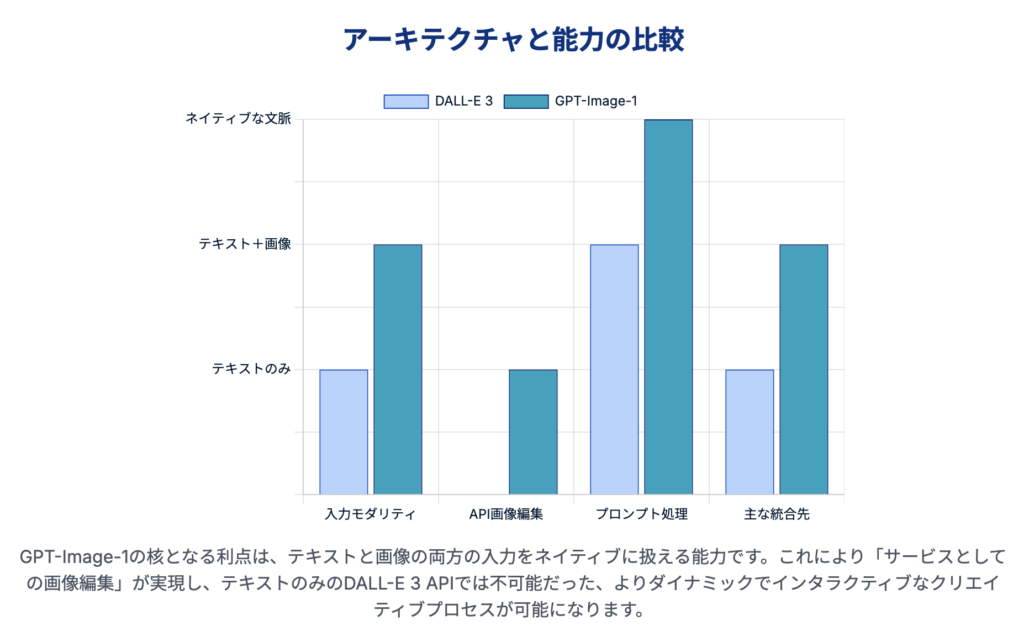
以下の表は、両モデルの主要な特徴と能力を比較したものです。
| 特徴 | DALL-E 3 | GPT-Image-1 |
| 基盤アーキテクチャ | 主に拡散モデルベース、ChatGPTと連携 | GPT-4oファミリー内の自己回帰型モデル |
| API識別子 | dall-e-3 | gpt-image-1 |
| 入力モダリティ | テキストのみ | テキスト + 画像 |
| API経由の画像編集 | 非対応 | 対応(インペインティング、スタイル変更等) |
| プロンプト洗練 | ChatGPTが外部からプロンプトを拡張 | モデル自体が文脈をネイティブに理解 |
| テキストレンダリング | 良好 | 非常に高精度 |
| 主な初期統合先 | ChatGPT Plus, Bing Image Creator | GPT-4o, 次世代Copilot, Azure OpenAI |
この比較から明らかになるのは、「画像編集サービス(Image Editing as a Service)」が新たなフロンティアとして浮上していることです。テキストからの画像生成が一般化しつつある現在、プログラムを通じて、あるいは対話形式で既存の画像を反復的に編集・改良できる能力は、高い付加価値を持つ差別化要因となります。デザイナー、マーケター、開発者にとって、これは単に新しい画像を生成するだけでなく、既存のビジュアルコンテンツを進化させていくための全く新しいワークフローを可能にします。この能力こそが、プラットフォームがDALL-E 3からGPT-Image-1へとアップグレードされる最も強力な動機となっています。
第2章 一般消費者向け統合:MicrosoftエコシステムにおけるOpenAI画像モデル
OpenAIの先進的な画像生成技術は、研究室のデモに留まらず、Microsoftとの戦略的パートナーシップを通じて、数億人が日常的に利用する製品群へと深く統合されています。この統合は、一般ユーザーやスモールビジネスがAIの力を直接体験する主要な窓口となっています。しかし、Microsoftの製品ブランディングは頻繁に進化し、背後でどの技術が使われているのかが分かりにくいという側面もあります。本章では、Microsoftの主力AI製品である「Microsoft Copilot」と、クリエイティブスイートである「Microsoft Designer」に、OpenAIの画像生成モデル(DALL-E 3およびGPT-Image-1/GPT-4o)がどのように組み込まれているかを解き明かし、その背景にある戦略的な意図を分析します。
2.1 Microsoft Copilot:AIコンパニオンの進化
MicrosoftのAI戦略の中心に位置するのが「Copilot」ブランドです。このブランドは、当初「Bing Chat」として知られていたサービスから進化し、現在ではMicrosoftのAIアシスタント機能全般を指す統一ブランドとして確立されています 。この進化の過程で、画像生成機能は重要な役割を果たしてきました。
Microsoftはまず、Bingの「Image Creator」ツールにOpenAIのDALL-E 2を実装し、その後、より高性能なDALL-E 3へとアップグレードしました 。このImage Creatorは、Copilot(旧Bing Chat)の対話インターフェース内から、あるいは独立したウェブサイトとして利用でき、ユーザーがテキストプロンプトから画像を生成するための主要な手段となりました。この段階では、Copilotの画像生成のバックエンドはDALL-E 3が担っていました。
しかし、2025年5月、MicrosoftはCopilotの画像生成能力を「4o image generation」でアップグレードしたと公式に発表しました 。これは、Copilotの画像生成エンジンが、DALL-E 3から
GPT-Image-1を内包するGPT-4oアーキテクチャへと移行したことを意味します。このアップグレードにより、ユーザーはより豊かなディテールと優れた構図を持つ画像を生成できるようになっただけでなく、以前の会話の文脈やユーザーがアップロードした画像を基に、画像をより高度に洗練させることが可能になりました 。これは、
GPT-Image-1が持つネイティブなマルチモーダル性と編集能力が、一般消費者向け製品に直接的に反映された例です。
Copilotには無料版と有料版(Copilot Pro)が存在します。無料版でもGPT-4oのような強力なモデルを利用できますが、月額20ドルのCopilot Proサブスクリプションに登録すると、ピークタイムにおける優先的なアクセス権や、1日あたりにより多くの「ブースト」(画像生成の高速化クレジット)が付与されるといった特典があります 。
2.2 Microsoft Designer:専用クリエイティブスイート
Microsoft Copilotが対話ベースの汎用AIアシスタントであるのに対し、「Microsoft Designer」は、ビジュアルコンテンツの作成に特化した、より専門的なツールとして位置づけられています 。Designerは、テンプレート、デザイン提案、そしてインタラクティブなグラフィカルユーザーインターフェースを提供し、ユーザーがプレゼンテーション資料、ソーシャルメディア投稿、招待状などを効率的に作成できるよう支援します。
重要な点として、Microsoft Designerの画像生成機能は、公式にDALL-E 3モデルを使用していることが明記されています 。実際に、Copilot(Bing Image Creator)で画像を生成したユーザーが「カスタマイズ」ボタンをクリックすると、Microsoft Designerのインターフェースにリダイレクトされるというワークフローが確認されています 。これは、Copilotでの迅速なアイデア出しから、Designerでのより構造化されたデザイン作業へとシームレスに移行する流れを示しており、その過程でDALL-E 3が活用されていることを裏付けています。
また、Designerには「ジェネレーティブフィル」(インペインティング)や「ジェネレーティブエキスパンド」(アウトペインティング)といった、画像の特定部分を埋めたり、境界線の外側に画像を拡張したりする機能が「近日公開」として予告されています。これらの機能はDALL-E 3の画像編集モデルによって提供されると説明されていますが 、これはDALL-E 3自体の能力が拡張されているか、あるいは将来的には
GPT-Image-1の編集機能がDesignerに統合されることを示唆するマーケティング上の表現である可能性も考えられます。
2.3 ユーザーエクスペリエンスと命名戦略:意図的な抽象化
多くのユーザーやアナリストが指摘するように、MicrosoftのAI製品ラインナップと、その背後にある技術の命名には、ある種の分かりにくさが存在します 。Microsoftは、
DALL-E 3、GPT-4o、gpt-image-1といった具体的なモデル名を前面に出すのではなく、「Copilot」というブランド名と、「アップグレードされた画像生成」といったユーザーにとっての便益を強調する戦略をとっています。
この戦略には明確な理由があります。これは、急速に進化する技術スタックの上に、安定した一貫性のあるブランド体験を構築するための「抽象化レイヤー」として機能します。技術が進化するたびにエンドユーザーを再教育することなく、バックエンドのモデルをシームレスに交換することを可能にします。ユーザーは「GPT-4o-2024-05-13」ではなく、「Copilot」という信頼できるブランドを使い続ければよいのです。これにより、Microsoftのエンジニアリングチームは、マーケティング部門が市場全体を再教育する必要なく、継続的にバックエンドを最高のモデルにアップグレードし続けることができます。これは、製品と基盤技術を意図的に切り離す、古典的かつ強力なプラットフォーム戦略です。
この戦略の結果として、Microsoftの製品ポートフォリオには、モデルの能力を反映した二層構造の製品戦略が浮かび上がってきます。最上位に位置するのは、最新かつ最高のモデルであるGPT-4o(GPT-Image-1)を搭載し、高度な対話型編集と推論能力を提供する「Microsoft Copilot」(特にPro版)です 。これは、MicrosoftのAI技術の粋を集めた「ヒーロープロダクト」と言えます。一方で、テンプレートベースのデザイン作成など、特定の高頻度タスクに特化した「Microsoft Designer」は、引き続き強力でありながらも、よりコスト効率が高い可能性があるDALL-E 3を活用しています 。GPT-4oの持つ完全なマルチモーダル能力は、Designerの中核的なユースケースにとっては過剰スペック(かつ高コスト)である可能性がありますが、「何でもできる」というCopilotの約束を果たすためには不可欠です。このように、Microsoftは、各製品の目的とコストパフォーマンスを考慮し、最適なモデルを戦略的に配置しているのです。

第3章 開発者向けフロンティア:Azure OpenAI ServiceにおけるGPT-Image-1
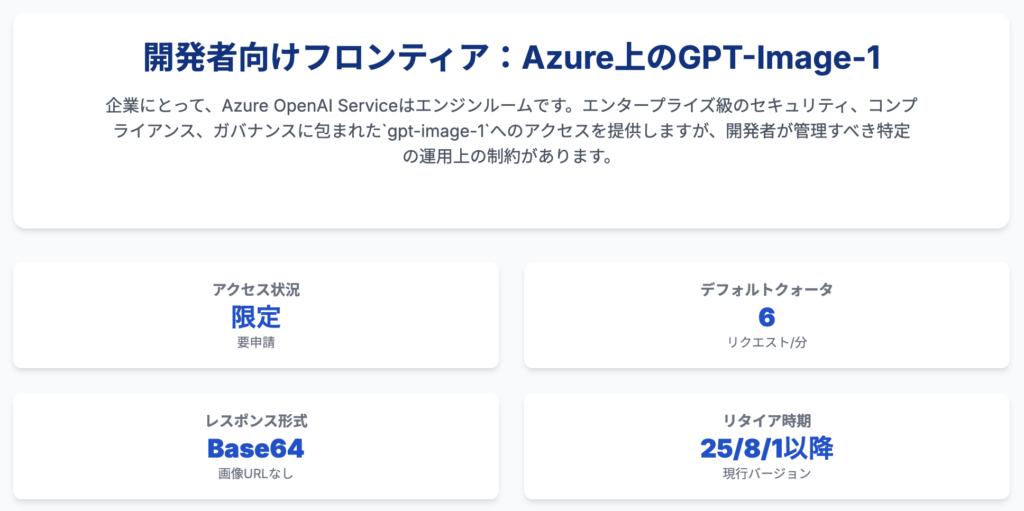
Microsoftの一般消費者向け製品がAI技術の「ショーケース」であるとすれば、Azure OpenAI Serviceは、開発者や企業がその力を自社のアプリケーションやワークフローに組み込むための「エンジンルーム」です。特に、最新の画像生成モデルであるGPT-Image-1は、Azureプラットフォーム上でエンタープライズグレードの機能として提供されており、その利用には特有のアクセス方法、API仕様、そして運用上の考慮事項が存在します。本章では、技術的な意思決定を行う開発者やアーキテクトを対象に、Azure OpenAI ServiceにおけるGPT-Image-1の利用可能性、アクセス手順、地域展開、APIの実装詳細、価格設定、クォータ、そしてモデルのライフサイクル管理について、網羅的かつ実践的な情報を提供します。
3.1 利用可能性、アクセス、およびリージョン展開
Azure上でGPT-Image-1を利用する際の最初のステップは、その提供ステータスを理解することです。このモデルは、一般提供(GA)されているサービスではなく、「限定アクセスプレビュー」として提供されています 。これは、誰でもすぐに利用できるわけではないことを意味します。
アクセスするには、Microsoftが提供する特定のフォームを通じて正式な申請が必要です 。重要なのは、すでにGPT-4やo3といった他のプレビューモデルへのアクセス権を持つ顧客であっても、
GPT-Image-1へのアクセスは別途申請する必要があるという点です 。このゲートキーピングの仕組みは、このモデルがカジュアルな実験用ではなく、特定の基準を満たすエンタープライズユースケースを想定したプレミアムなサービスであることを示唆しています。
アクセスが許可された後、モデルは特定のAzureリージョンにデプロイする必要があります。現在GPT-Image-1がサポートされているリージョンは以下の通りです 。
- West US 3
- East US 2
- UAE North
- Poland Central
Azureでは、デプロイメントのタイプとして「グローバル」「データゾーン(EUまたはUS)」「リージョナル」といった選択肢があり、これらはデータの保存場所に関するコンプライアンス要件、パフォーマンス、そして価格設定において異なるトレードオフを提供します 。
3.2 API実装と技術仕様
Azure上でGPT-Image-1を利用するためのAPI実装は、OpenAIのネイティブAPIと似ていますが、Azure特有の仕様が存在します。
APIエンドポイントの構造は以下の形式を取ります 。
APIリクエストには、2025-04-01-previewのように、使用するAPIのバージョンを明示的に指定する必要があります 。
Azure上のGPT-Image-1で利用可能な主要なパラメータは以下の通りです。
prompt: プロンプトの最大長は4,000文字です 。size: 画像サイズ。1024x1024、1024x1536、1536x1024のいずれかである必要があります 。quality: 画質。low、medium、highから選択します 。n: 生成する画像の数 。response_format: これはAzureにおける重要な技術的制約です。このパラメータはサポートされておらず、Azure上のGPT-Image-1は常にBase64でエンコードされた画像データを返します 。OpenAIのAPIが画像のURLを返すことができるのとは対照的です。
また、GPT-Image-1の核となる機能である画像編集(インペインティングなど)も、Azure上で専用のImage Edit APIを通じて利用可能です 。
3.3 価格設定、クォータ、およびコスト管理
GPT-Image-1の価格設定は、画像1枚あたりではなく、消費されるトークンに基づいた複雑なモデルを採用しています。コストは、入力と出力、そしてそのモダリティ(テキストか画像か)によって細かく分類されています 。
- 入力テキストトークン: 例:$5.00 / 100万トークン(グローバル)
- 入力画像トークン: 例:$10.00 / 100万トークン(グローバル)
- 出力画像トークン: 例:$40.00 / 100万トークン(グローバル)
さらに、データゾーンやリージョナルデプロイメントを選択した場合、コンプライアンスとデータ主権の保証と引き換えに、グローバルSKUに比べて価格が上乗せされます(例:入力テキストが5.00から5.50になる)。
アプリケーションのスケーラビリティを計画する上で極めて重要なのがクォータ制限です。Azure上のGPT-Image-1のデフォルトクォータは、2キャパシティユニットに設定されており、これは1分あたり6リクエストに相当します 。大規模なアプリケーションを構築する際には、この制限を前提とした設計(キューイングやリトライロジックの実装など)が不可欠です。
3.4 モデルのライフサイクル管理
エンタープライズ環境では、技術の予測可能性が重要です。Microsoftは、Azure OpenAI Serviceで提供されるモデルに対して、明確な廃止・リタイアポリシーを設けています 。プレビューモデルは、提供開始時に「それより早くはリタイアしない」という日付が設定されます。
現在提供されているgpt-image-1のバージョン2025-04-15については、2025年8月1日より前にはリタイアしないことが保証されています 。これにより、開発者はモデルのサポート期間を予測し、将来的なアップグレード計画を立てることが可能になります。
以下の表は、開発者がAzure上でGPT-Image-1を利用する際に必要となる主要な運用情報をまとめたものです。
| パラメータ | Azureにおける仕様 |
| アクセスステータス | 限定アクセスプレビュー(要申請) |
| サポートリージョン | West US 3, East US 2, UAE North, Poland Central |
| APIエンドポイント | https://<resource>.openai.azure.com/openai/deployments/<deployment>/... |
| 最新APIバージョン例 | 2025-04-01-preview |
| 価格(グローバル) | 入力テキスト: $5/M, 入力画像: $10/M, 出力画像: $40/M |
| 価格(データゾーン/リージョナル) | 入力テキスト: $5.50/M, 入力画像: $11/M, 出力画像: $44/M |
| デフォルトクォータ | 2キャパシティユニット(6 リクエスト/分) |
| レスポンス形式 | Base64エンコード画像のみ |
| 現行モデルバージョン | 2025-04-15 |
| リタイア時期 | 2025年8月1日より前にはリタイアしない |
この表は、複数のMicrosoft Learnドキュメントに散在する断片的な情報を、開発者にとって最も重要かつ実践的な形式で集約したものです 。
Azureが提供するサービスは、単にOpenAIのモデルへのアクセスを提供するだけではありません。リージョンごとのデータ管理 、プライベートネットワーク、厳格なアクセス制御 、予測可能なリタイアスケジュール 、そしてコンプライアンス要件に基づいた価格体系 といった、エンタープライズグレードの管理・統制機能を「ラッパー」として付加価値を提供しています。Microsoftは、APIそのものだけでなく、信頼性、ガバナンス、そしてセキュリティを販売しているのです。
また、gpt-image-1のような最先端モデルを「限定アクセス」とすることは、計算リソースが限られている初期段階での需要管理という実用的な側面に加え、サービスのプレミアムな位置づけを強化する戦略的な意図も含まれています。アクセスに申請を必要とすることで、Microsoftはこのサービスをカジュアルな利用ではなく、真剣なエンタープライズユースケース向けの最先端ツールとしてブランディングし、その価格設定を正当化しています。
さらに、Azure APIがBase64エンコードされた画像のみを返すという技術的な選択 は、一見些細に見えますが、アーキテクチャに大きな影響を与えます。URL形式のレスポンスは帯域幅とストレージを開発者のアプリケーションからオフロードしますが、Base64形式はアプリケーション側で完全なデータペイロードを処理する必要があり、メモリや帯域幅に影響します。この選択は、セキュリティとデータ管理を優先するAzureの姿勢を反映していると考えられます。一時的で公開アクセス可能なURLの管理に伴う複雑さを回避し、データをAPIレスポンス内に閉じることで、エンタープライズ環境で求められるより堅牢なセキュリティ体制を維持しているのです。
第4章 戦略分析:OpenAIとMicrosoftのパートナーシップの力学
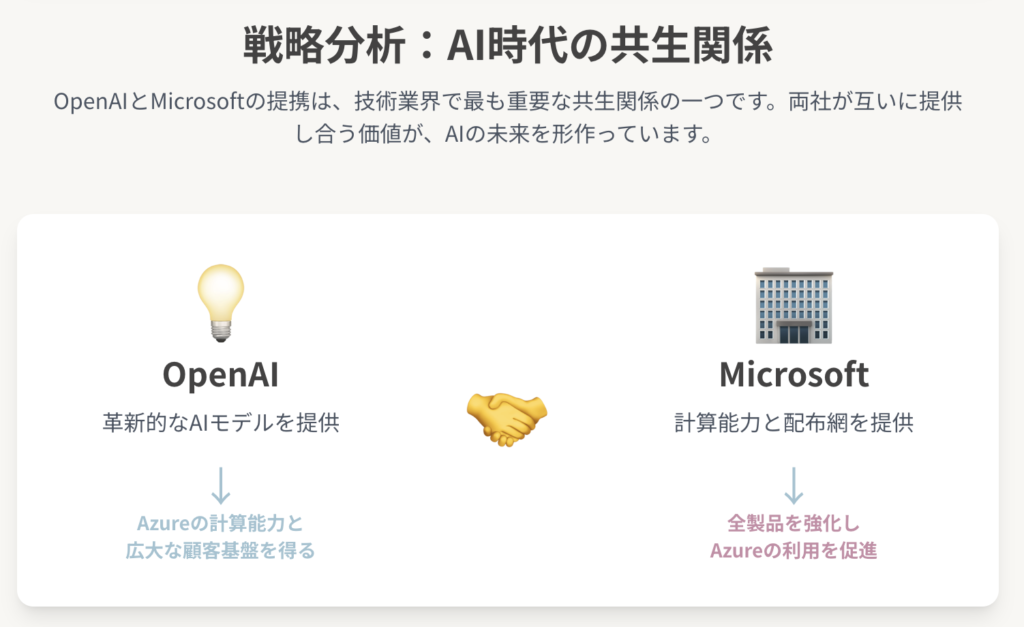
OpenAIの革新的なAIモデルとMicrosoftの広範なエコシステムの統合は、単なる技術的な提携以上の意味を持ちます。それは、現代のテクノロジー業界における最も重要な共生関係の一つであり、AIの未来を形作る上で中心的な役割を果たしています。このパートナーシップの構造と力学を理解することは、開発者が自身のプロジェクトでどちらのプラットフォーム(OpenAIのネイティブAPIか、Azure OpenAI Serviceか)を選択すべきか、そしてこの技術が今後どのような方向に進んでいくのかを判断するための鍵となります。
4.1 深い共生関係
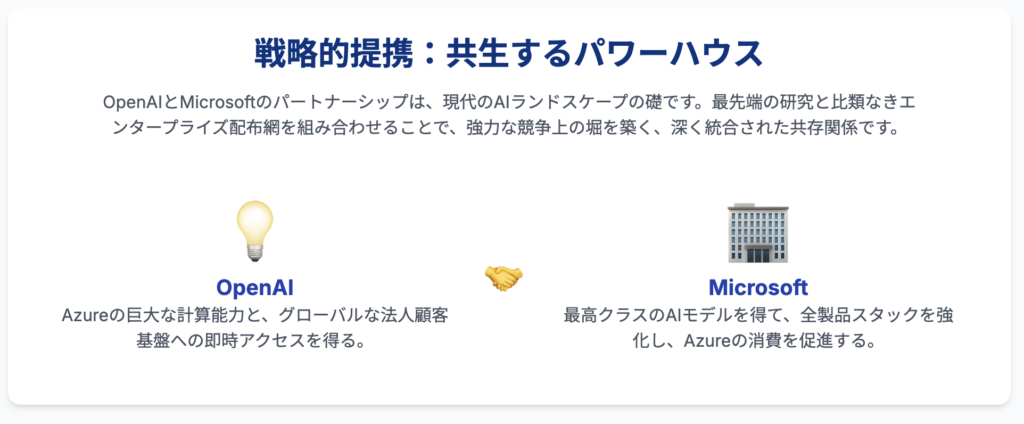
このパートナーシップは、両社にとって計り知れない価値をもたらす、相互依存的な関係に基づいています。
Microsoftの利益: Microsoftは、OpenAIの最先端モデルを自社の中核製品群(Azure、Microsoft 365、Windows)に統合することで、製品のインテリジェンスと競争力を劇的に向上させています 。これにより、クラウドサービスの利用(Azureの消費)とソフトウェアのサブスクリプションを促進します。130億ドルとも言われる巨額の投資は、AIプラットフォームへの移行期において主導権を握るための戦略的な賭けです 。
OpenAIの利益: 一方、OpenAIは、巨大なモデルのトレーニングとデプロイに不可欠な、Microsoftの広大なAzureハイパースケールコンピューティングインフラへのアクセスを得ます 。さらに、Azureを通じてMicrosoftの膨大なエンタープライズ顧客ベースに即座にリーチできるため、強力な販売・流通チャネルを確保できます。
この関係は、単なる顧客とベンダーの関係ではありません。Azure OpenAI ServiceのAPIは、OpenAIとMicrosoftが共同で開発しており、互換性とスムーズな移行を保証しています 。この深いレベルでの共同開発と統合こそが、両社にとっての強力な競争優位性の源泉となっています。
4.2 開発者向け意思決定フレームワーク:OpenAI API vs. Azure OpenAI Service
開発者が画像生成機能をアプリケーションに組み込む際、OpenAIのネイティブAPIを直接利用するか、Azure OpenAI Serviceを経由するかの選択に直面します。この選択は、プロジェクトの要件や組織の状況によって決まります。
OpenAIのネイティブAPIを選択すべき場合:
- 迅速なプロトタイピング: 最新の機能がリリースされた瞬間にアクセスし、素早くアイデアを試したい場合。
- 個人の開発者やスタートアップ: 厳格なコンプライアンス要件がなく、俊敏性を最優先する場合。
- 最先端機能への最速アクセス: OpenAIが発表する最新の実験的な機能をいち早く試したい場合。
Azure OpenAI Serviceを選択すべき場合: これは、エンタープライズアプリケーションや、以下の要件を持つあらゆるプロジェクトにとって、ほぼ必須の選択肢となります。
- エンタープライズグレードのセキュリティとプライバシー: プライベートネットワーク、Azure Active Directory(現Microsoft Entra ID)との統合、詳細なアクセス制御など、堅牢なセキュリティ機能が必要な場合。
- データ主権とコンプライアンス: データゾーンやリージョナルデプロイメントを利用して、データを特定の地理的境界内(例:EU内)に保持する必要がある場合 。これはGDPRなどの規制遵守に不可欠です。
- 他のAzureサービスとの統合: Azure Storage、Azure AI Search、Azure Functionsなど、既存のAzureエコシステムとシームレスに連携させたい場合。
- 統一された請求と管理: AI関連のコストを既存のAzure契約の下で一元管理し、コスト分析を行いたい場合。
- 予測可能性と安定性: Microsoftが提供するマネージドサービス、SLA(サービス品質保証)、そして予測可能なモデルのリタイアスケジュールに依存したい場合 。
この選択は、テクノロジー開発における古典的な「俊敏性(Agility)対安定性(Stability)」のトレードオフを反映しています。OpenAIのネイティブAPIは俊敏性を提供し、最新のイノベーションに素早くアクセスできます。一方、Azure OpenAI Serviceは安定性を提供し、より管理され、安全で、予測可能な環境を提供しますが、機能の提供にはわずかなタイムラグが生じる可能性があります。このパートナーシップが両方の選択肢を提供することで、個人のホビイストからフォーチュン500企業まで、市場のあらゆるセグメントを効果的にカバーしているのです。
4.3 将来展望:統合されたAIの軌跡
GPT-Image-1の統合は、単なる機能追加ではなく、より広範で長期的なトレンドの一部です。今後のAIの進化は、以下の方向に進むと予測されます。
エージェント型ワークフローへ: GPT-4oや将来のGPT-5のような高度なモデルがMicrosoft 365 Copilotに統合されることは、AIが単一のタスクを実行するツールから、複数のアプリケーションを横断して複雑なタスクを自律的に実行する「エージェント」へと進化することを示唆しています 。例えば、「先週のプロジェクトXに関するメールを要約し、関連するWord文書を見つけ出し、その内容を基にカスタム画像を生成してPowerPointのスライドを作成する」といった一連の作業を、単一の指示で実行する未来が現実味を帯びてきています 。
シームレスなマルチモダリティ: GPT-Image-1で見られたアーキテクチャの転換は、今後さらに加速します。テキスト、画像、さらには動画(Soraの登場 )の生成と編集の境界線はますます曖昧になり、最終的にはCopilotのような単一の対話インターフェースを通じて、あらゆる形式のデータを直感的に操作できるようになるでしょう。
「Copilotスタック」の完成: Microsoftは、Azure上の基盤モデル から、カスタマイズレイヤー(Copilot Studio )、そしてエンドユーザーアプリケーション(Microsoft 365やWindowsに組み込まれたCopilot )に至るまで、完全なAIスタックを構築しています。この垂直統合されたエコシステムは、競合他社が容易に模倣することが困難な、強力な競争上の「堀(Moat)」を形成しています。
GoogleのImagenのような競合モデルが存在する中で、Microsoftの真の強みは、その圧倒的な配布・統合能力にあります。Microsoftは、OpenAIの技術を、Microsoft 365やWindowsを通じて何百万人ものエンタープライズユーザーの日常的なワークフローに直接組み込んでいます 。さらに、Azure OpenAI Serviceは、企業が安心してAIを導入するための、信頼性とコンプライアンスを備えたオンランプを提供します。この深く、広範なエンタープライズ統合こそが、単一のモデル性能ベンチマークでは測れない、Microsoftの決定的な競争優位性となっているのです。すでにMicrosoftエコシステムに投資している企業にとって、たとえ特定のベンチマークでわずかに優れたサードパーティのモデルが存在したとしても、Azure OpenAI Serviceを利用する方がはるかに容易で安全な選択となるでしょう。

第5章 結論と実践的な提言
本レポートでは、OpenAIの画像生成モデルGPT-Image-1と、それがMicrosoftのエコシステム全体でどのように統合され、どのような互換性を持つかについて、詳細な分析を行ってきました。技術的な仕様から戦略的な意図までを掘り下げることで、この強力なテクノロジーが開発者や企業にとって何を意味するのかが明らかになりました。本章では、これまでの分析結果を統合し、テクノロジー専門家が取るべき具体的な行動指針を提言します。
5.1 分析結果の統合
本レポートの分析から、以下の重要な結論が導き出されます。
- 技術の進化: 画像生成技術は、テキスト入力のみに対応したDALL-E 3から、テキストと画像の両方を入力として受け付け、高度な編集能力を持つ、ネイティブなマルチモーダルアーキテクチャGPT-4oの一部である
GPT-Image-1へと、質的な飛躍を遂げました。この進化は、単なる性能向上ではなく、AIが情報を処理する方法における根本的なパラダイムシフトを意味します。 - Microsoftの二重戦略: Microsoftは、この進化する技術を自社製品に統合するにあたり、巧妙な二重戦略を採用しています。フラッグシップ製品であるMicrosoft Copilotには、最新かつ最高の能力を持つGPT-4o/
GPT-Image-1を迅速に導入し、プレミアムな体験を提供します。一方で、Microsoft Designerのような特定のユースケースに特化したアプリケーションでは、依然として強力かつコスト効率の高いDALL-E 3を活用しています。これは、製品の目的と経済合理性に基づいた戦略的なモデル配置です。 - Azureにおけるエンタープライズ提供: 開発者にとって、Azure OpenAI Service上で提供される
GPT-Image-1は、単なるAPIではありません。それは、セキュリティ、コンプライアンス、ガバナンス、そして予測可能性といったエンタープライズグレードの要件を満たすために設計された、厳格に管理されたサービスです。限定アクセスプレビューという提供形態は、そのプレミアムな位置づけと、Microsoftがエンタープライズ市場を最優先していることの証左です。
5.2 テクノロジー専門家への提言
上記の分析結果を踏まえ、開発者、アーキテクト、そしてテクノロジーリーダーは、以下の実践的な提言を考慮することが推奨されます。
- アイデア創出とプロトタイピング段階において: 無料版のMicrosoft Copilotや、OpenAIのネイティブAPIを積極的に活用し、GPT-4oの画像生成および編集能力を低コストかつ最大限の柔軟性で実験してください。これにより、技術の可能性を迅速に把握し、新しいユースケースを模索することが可能になります。
- 本番環境向けアプリケーションの開発において: 機密データを扱う、高い可用性が求められる、あるいはGDPRのようなコンプライアンス基準を満たす必要があるアプリケーションを開発する場合、Azure OpenAI Serviceの利用は必須と考えるべきです。プロジェクトのライフサイクルの早い段階で、
GPT-Image-1へのアクセス申請を開始してください。限定アクセスであるため、承認には時間がかかる可能性があります。 - 予算策定とアーキテクチャ設計において: Azure上で
GPT-Image-1を利用するプロジェクトを計画する際、アーキテクトは、入力テキスト、入力画像、出力画像で異なるトークンベースの価格設定を正確に理解し、コストを見積もる必要があります。また、デフォルトの低いリクエストクォータ(1分あたり6リクエスト)を前提とし、キューイング、バッチ処理、リトライロジックなどを組み込んだ堅牢なシステムを設計することが不可欠です。さらに、APIのレスポンスがURLポインタではなくBase64エンコードされたデータであることを念頭に置き、アプリケーション側でデータペイロードを処理するためのメモリと帯域幅を確保する必要があります。 - 戦略的展望において: テクノロジーリーダーは、
GPT-Image-1の統合を単なる画像生成機能の追加として捉えるべきではありません。これは、より深く統合された、自律的なエージェント型AI能力への序章です。今後の戦略計画では、これらの新しいマルチモーダルかつマルチアプリケーションなワークフローを活用して、既存のビジネスプロセスの自動化を推進し、新たなイノベーションを創出する方法に焦点を当てるべきです。GPT-Image-1は、AIが単なるツールから、真の協働パートナーへと進化する未来を予感させる、重要なマイルストーンなのです。
#GPTImage1 #ChatGPT #横田秀珠 #ChatGPTセミナー #ChatGPTコンサルタント #ChatGPT講座 #ChatGPT講習 #ChatGPT講演 #ChatGPT講師 #ChatGPT研修 #ChatGPT勉強会 #ChatGPT講習会