ChatGPT Image1搭載Old Sora進化!リアル人物写真の再現UP

毎年リピートありがとうございます。
久しぶりのInstagram最新セミナー
イーンスパイアの横田です。
https://www.enspire.co.jp

さて、本題です。
ChatGPT画像生成AIモデルのGPT-Image1とMicrosoftの互換性
https://yokotashurin.com/etc/gpt-image1.html
2025年8月14日のブログで書いた内容ですが
ChatGPT5になったので画像生成も進化か?
ChatGPT Image1搭載Old Sora進化!リアル人物写真の再現UP
日本語テキスト入り精度UPしGoogle Nano-Bananaに対抗か?
https://www.youtube.com/watch?v=w65p4VlblI4
ChatGPT Image1搭載Old Sora進化!リアル人物写真の再現UP
🚀 GPT-Image1進化検証!人物再現と日本語精度が大幅向上中
🔬 検証の背景
検証日:2025年11月20日 📅
ChatGPT5搭載のGPT-Image1とOld Soraが進化しているのでは?
→ 2025年4月との比較検証を実施
🎯 検証ポイント
✅ リアルな人物写真の再現精度
✅ 日本語文字入りの精度
✅ 前回(2025年3-4月)からの進化度合い
✅ リアルな人物写真の再現精度
✅ 日本語文字入りの精度
✅ 前回(2025年3-4月)からの進化度合い
⬇️ 2025年4月の結果 ⬇️
📊 前回(4月)の検証結果
😅 顔の再現
羽生結弦の写真を自分の写真に変えて
→ 全然本人が再現できない
ネタとしては面白いが…
羽生結弦の写真を自分の写真に変えて
→ 全然本人が再現できない
ネタとしては面白いが…
📝 日本語の精度
チラシのデザイン作成
→ 文字がめちゃくちゃ
「頑張った」レベル
チラシのデザイン作成
→ 文字がめちゃくちゃ
「頑張った」レベル
💭 当時の結論
人物の顔の再現:❌ 難しい日本語の文字:△ まあまあ
Soraっぽい背景:✅ 綺麗に作れる
⬇️ 最新検証(11月) ⬇️
🆕 ChatGPT5(11月)の検証結果
🔄 同じプロンプトで再検証
2025年4月と同じ条件で画像生成を試行
2025年4月と同じ条件で画像生成を試行
発見❶:顔の再現はまだ課題
羽生結弦の写真 → 自分の顔に差し替え
→ ほとんど変わらない、再現できず
⚠️ ただし、差し替えではなく最初から顔写真を使うと精度UP!
発見❷:日本語文字が大幅進化!
チラシデザイン「IT販促SNS活動セミナー」
→ 文字が正確に再現
→ かなりレベルが上がった!
💡 重要な発見:元画像の品質が影響
1
仮説:古い写真(画質悪い)が原因では?
2
新しい写真で再検証
3
顔の再現性が向上!
💭 AIの認識パターン
• 同じ顔で毎回再現される(一貫性あり)• AI的には「100%これだ」と認識している
• 本人とは異なるが、AIの中では同一人物として処理
⬇️ さらなる発見 ⬇️
🎯 最適な画像生成方法の発見
❌ 非効率な方法
既存画像の顔を
差し替え
①元の顔を認識
②顔を消去
③新しい顔を再現
→ 3つの処理で精度低下
既存画像の顔を
差し替え
①元の顔を認識
②顔を消去
③新しい顔を再現
→ 3つの処理で精度低下
✅ 効率的な方法
最初から顔写真を
使って生成
処理がシンプル
→ 再現性が向上!
最初から顔写真を
使って生成
処理がシンプル
→ 再現性が向上!
💡 プロのコツ
差し替えを指示するのではなく、「この写真を使って画像を作って」と最初から指定する方が精度が高い!
差し替えを指示するのではなく、「この写真を使って画像を作って」と最初から指定する方が精度が高い!
🆚 他モデルとの比較
GPT-4o
(2025年4月)
顔:❌
日本語:△
デザイン:○
(2025年4月)
顔:❌
日本語:△
デザイン:○
GPT-5
GPT-Image1
(2025年11月)
顔:△→○
日本語:◎
デザイン:◎
GPT-Image1
(2025年11月)
顔:△→○
日本語:◎
デザイン:◎
Google Gemini
Nano-Banana
(2025年8月〜)
顔:◎完璧
日本語:△
デザイン:△
Nano-Banana
(2025年8月〜)
顔:◎完璧
日本語:△
デザイン:△
🎯 ベストな使い分け
✅ 顔の完璧な再現 → Google Gemini(Nano-Banana)
✅ 日本語+デザイン → ChatGPT(GPT-Image1)
→ 用途に応じて使い分けるのが賢い!
🚀 Old Soraの活用法
🎨 1回に4枚生成できる利点
Old Soraは4枚同時生成が可能
→ 日本語の再現性を4パターン比較できる!
1
4枚の画像が同時生成される
2
日本語が正確に再現できているか確認
3
デザインと文字の両方が良いものを選択
4
やり直しの手間が減る → 効率UP!
💡 実例:サムネイル作成の場合
左上:GPT5 Pro(全て正確)✅
左下:Team OK(全て正確)✅
右上:PRの「Pro」が小さい ❌
右下:「で」が2つ(でで)❌
→ 左上か左下を選択!
左上:GPT5 Pro(全て正確)✅
左下:Team OK(全て正確)✅
右上:PRの「Pro」が小さい ❌
右下:「で」が2つ(でで)❌
→ 左上か左下を選択!
🔧 Old Soraへのアクセス方法
New Sora画面 → 左下の「…」メニュー → 「Switch to Old Sora」
設定:3:2、1:1、2:3などの比率選択 + 4枚生成を選択
New Sora画面 → 左下の「…」メニュー → 「Switch to Old Sora」
設定:3:2、1:1、2:3などの比率選択 + 4枚生成を選択
🎬 New Soraの可能性
📹 動画生成で文字再現が完璧に!
New Soraでは動画生成時に日本語が完璧に再現
例:「龍ケ崎市商工会」「経営相談なら」などの文字が正確
💡 裏ワザ的活用法
1 New Soraで日本語入り動画を生成
2 動画をスクリーンショット
3 静止画として活用
→ 技術的に動画で実現できているなら、画像でもできるはず!
💼 実践的な作業効率化のコツ
💭 本質的な考え方
目的:「AIに画像を作らせること」ではない
目的:「制作物を早く作ること」
AIだけにこだわらない
顔の再現が難しい場合は…
顔の再現が難しい場合は…
AIで背景・デザイン生成
Soraで顔なしの画像を作成
Soraで顔なしの画像を作成
Canvaで顔を合成
自分の写真を別途配置
自分の写真を別途配置
結果:作業時間が大幅短縮!
🎯 効率化の鉄則
AI + Canva + 自分の素材 = 最速の制作フロー
「どうやったら早く仕事が終わるか」を常に考える
AI + Canva + 自分の素材 = 最速の制作フロー
「どうやったら早く仕事が終わるか」を常に考える
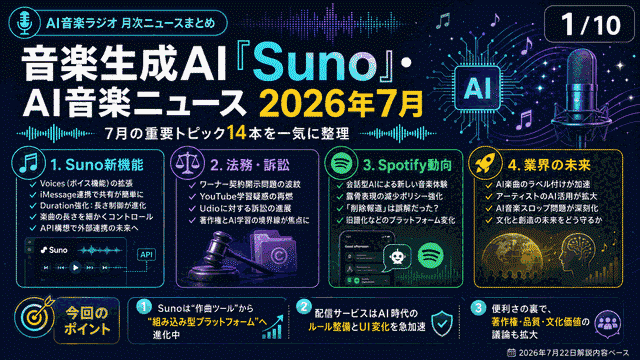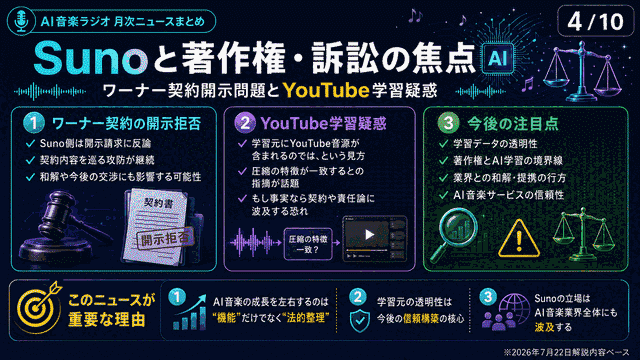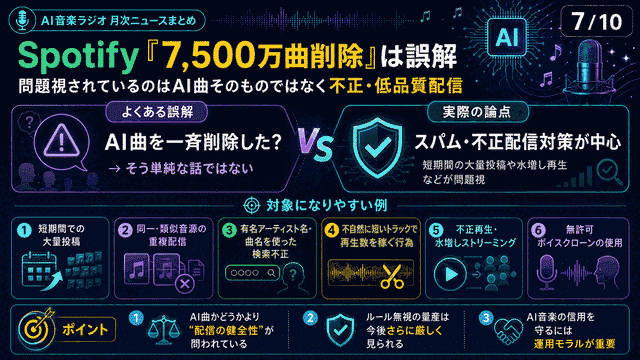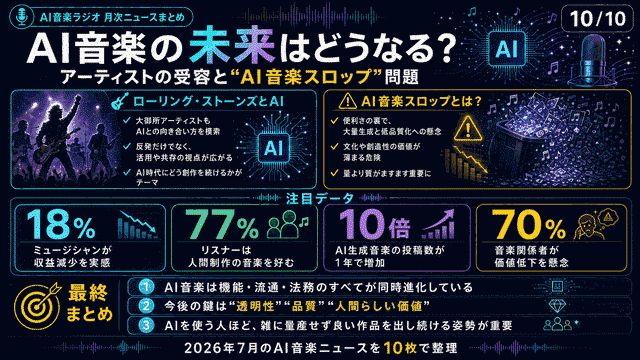
📈 まとめ:進化のポイント
✅ 大きく進化した点
📝 日本語文字の再現精度が大幅向上
🎨 デザイン全体の完成度が向上
🎬 New Soraで動画+文字が完璧に
△ まだ課題がある点
😅 顔の差し替えは精度が低い
📸 元画像の品質に影響を受ける
💡 賢い使い方
✨ 最初から顔写真を使って生成
🔄 Old Soraで4枚同時生成
🎯 用途別にモデルを使い分け
⚡ Canvaと組み合わせて効率化
ChatGPT Image1搭載Old Sora進化!リアル人物写真の再現UP
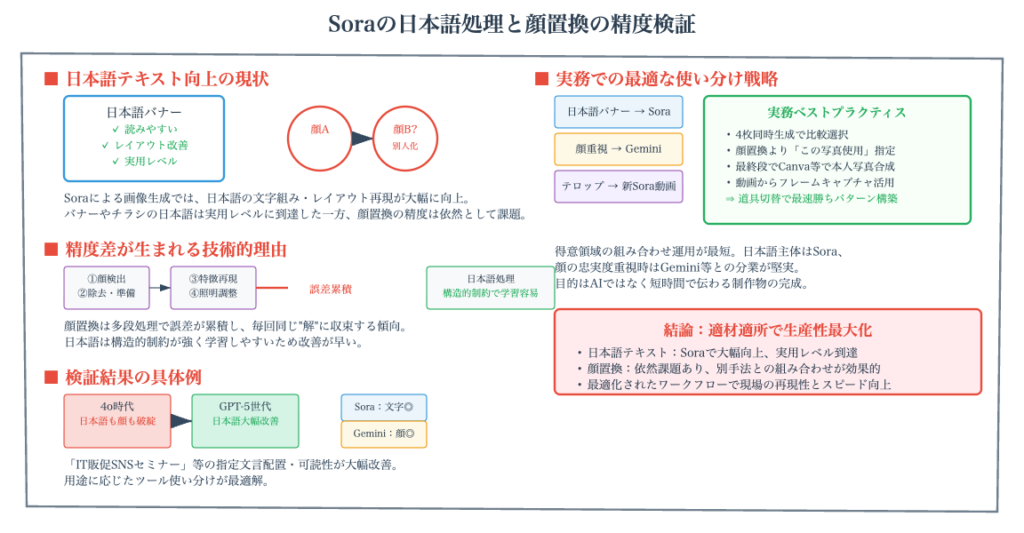
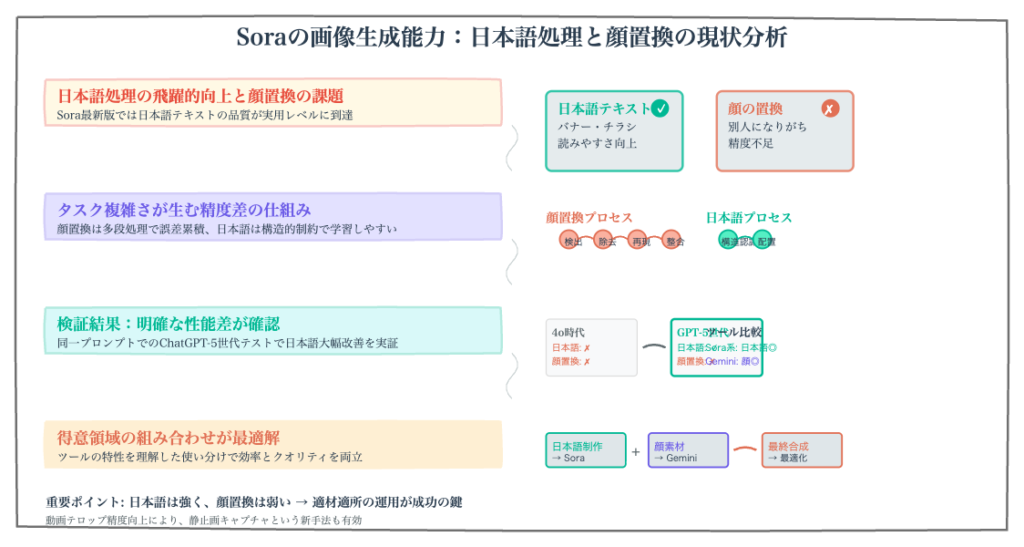
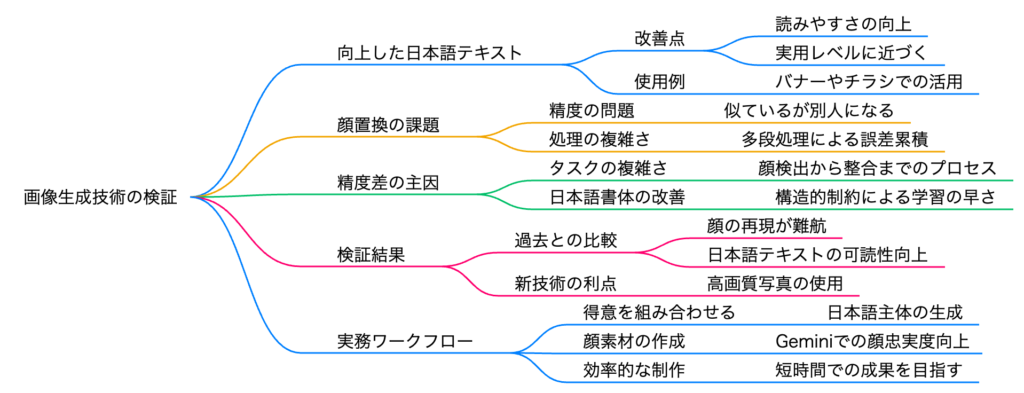
ChatGPTのGPT-Image1搭載のOld Soraが進化し、特に日本語文字入り画像の精度が大幅に向上した。人物写真の差し替えは依然として難しいが、最初から写真を指定して生成する方が再現性が高い。Old Soraは4枚同時生成が可能で比較選択に便利。New Soraの動画生成でも日本語テキストの再現が可能で、動画から静止画を取得する方法も有効。AI単体ではなくCanvaと組み合わせることで、効率的な制作が実現できる。
- はじめに
- ChatGPT GPT-Image1とOld Soraの進化検証:過去との比較から見えた驚きの変化
- 実際の検証結果を詳細レポート:人物写真と日本語文字の再現精度向上の実態
- 画像生成精度を劇的に向上させる新発見:差し替えではなく最初から作成する手法の優位性
- New SoraとOld Soraの実践的活用法:効率的な画像・動画制作のためのテクニック
- おわりに
- よくある質問(Q&A)
はじめに
AI画像生成技術の進化は、私たちの想像を遥かに超えるスピードで進んでいます。特に2025年に入ってから、ChatGPTに搭載されているGPT-Image1やSoraといった画像生成モデルの性能向上には目を見張るものがあります。数ヶ月前には実現が困難だった人物写真の高精度な再現や、日本語文字の正確な表示が、知らない間に大幅に改善されている可能性があることをご存知でしょうか。本記事では、ネットビジネス・アナリストである横田秀珠が、2025年11月20日時点での最新のAI画像生成技術を実際に検証した結果をお届けします。過去に実施した検証結果と最新の検証結果を詳細に比較することで、どれだけの進化を遂げたのか、そしてビジネスや実務でどのように活用すれば最も効果的なのかを徹底的に解説していきます。クリエイティブな作業の効率化を目指している方、ビジネスでのAI活用を検討されている方にとって、実践的で有益な情報が満載の内容となっています。
ChatGPT GPT-Image1とOld Soraの進化検証:過去との比較から見えた驚きの変化
検証の背景と目的
2025年11月20日木曜日、本日の検証テーマは「知らないうちに進化しているのではないか」という仮説の検証です。ChatGPTのGPT-Image1が搭載されているOld Soraについて、リアルな人物写真の再現精度が向上しているのではないか、そして日本語の文字入り精度も大幅に改善されているのではないか、という2つの観点から詳細な検証を実施しました。
実は、この検証は過去にも一度実施したことがあるテーマです。しかし、AI技術の進化スピードは極めて速く、わずか数ヶ月でも大きな変化が起こる可能性があります。そこで、同じプロンプトを使用して再度検証を行い、過去の結果と現在の結果を比較することで、実際にどれだけの進化があったのかを明らかにすることにしました。
過去の検証結果:2025年3月〜4月時点
まず、過去に実施した検証結果を振り返ります。使用したのはChatGPT-4o(2025年4月頃)のバージョンでした。当時の検証では、以下のような試みを行いました。
検証1:有名人の写真を自分の写真に差し替える試み
羽生結弦選手の写真が使用されているバナー画像に対して、「この写真を僕の写真に変えてバナー画像を作り直して」というプロンプトを入力しました。結果としては、ネタとしては面白く、笑いを取ることができるレベルではありましたが、本人の顔を正確に再現することは全くできませんでした。生成された画像は、本人とは似ても似つかない別人の顔になってしまっていました。
検証2:派手な服を着ている人物の顔を差し替える試み
次に、派手な服を着ている人物の画像に対して、「これを僕に着せて」というプロンプトを試しました。この場合も、顔が全く変わってしまい、本人を再現することはできませんでした。顔の特徴を保持しながら服装だけを変更するという処理は、当時の技術では実現困難でした。
検証3:建築物や空間の再現
一方で、Soraっぽい家に人物を配置する、あるいはSoraっぽい土地に家を建てるといった、人物の顔の再現を必要としない画像生成については、比較的良好な結果が得られました。これらの画像は「いい感じ」に仕上がり、実用レベルに近いクオリティでした。
検証4:チラシデザインの生成
チラシのデザイン生成も試みましたが、デザインそのものはうまく機能しませんでした。しかし、当時の基準からすると「ここまで綺麗になった」と評価できるレベルにはなっていました。
検証5:日本語文字の精度
特に課題だったのが日本語文字の精度です。よく見ると、文字が崩れていたり、意味不明な文字列になっていたりと、めちゃくちゃな状態でした。ただし、2025年3月時点の技術水準としては「すごい頑張った」と評価できるレベルではありました。完璧ではないものの、AIが日本語を認識して表示しようとしている努力は見られました。
最新の検証準備:2025年11月時点
それでは、同じプロンプトを使用して、最近の時点(2025年11月)で再度検証を行った結果はどうだったのでしょうか。検証の前日、たまたまSoraで画像を作成してみたところ、驚くべきことに気付きました。自分の顔の再現性が明らかに高くなっていたのです。
Soraは1回の生成で4枚の画像を出力します。その4枚すべてにおいて、自分の顔が高い精度で再現されており、「これは使えるのではないか」と感じるレベルになっていました。このサムネイル画像を見て、「精度がめちゃくちゃ上がっているのではないか」という確信を持ちました。
そこで、過去に使用したのと同じプロンプトで、改めて検証を実施することにしました。過去との比較により、どれだけの進化があったのかを明確にすることができます。この検証により、AI画像生成技術の進化の実態と、実務での活用可能性について、具体的な知見を得ることができると考えました。
実際の検証結果を詳細レポート:人物写真と日本語文字の再現精度向上の実態
ChatGPT-5での検証結果
それでは、過去と同じプロンプトを使用して、ChatGPT-5に搭載されている画像生成モデルで検証を実施した結果をお伝えします。ChatGPT-5では、画像生成機能が進化しているとされていますが、実際のところはどうだったのでしょうか。
検証結果1:人物の顔の差し替え(ChatGPT-4oとの比較)
まず、過去にChatGPT-4oで生成した画像と、ChatGPT-5で生成した画像を比較しました。結果は予想外でした。実際のところ、ほとんど変わらなかったのです。「あれ?」と思うほど、顕著な改善は見られませんでした。
顔の再現という観点では、若干の違いはあるものの、依然として本人を正確に再現することはできていません。全然再現できていないという状況に変わりはありませんでした。2つ目の検証でも、同様に再現できていないという結果になりました。
検証結果2:空間・建築物の生成
次に、空っぽの家に人物を配置するという検証を行いました。この場合の結果は「まあまあかな」という程度でした。この検証については、過去の結果と比較しても大きな変化は見られず、同レベルのクオリティでした。家を建てる検証についても、同様に「まあまあかな」という評価になりました。
検証結果3:チラシデザインの生成(大きな進化を確認)
しかし、最後のチラシデザインの生成では、大きな変化が確認できました。ここが、かなり精度が上がっていたのです。顔の再現については、まだまだ完璧にはできていません。しかし、前回、つまり2025年3月〜4月時点の結果と比較すると、明らかな改善が見られました。
前回の結果を見返すと、全然再現できていない状態でした。文字も元のままで、ほとんど再現できていませんでした。しかし今回は、指示した内容を正確に反映していました。具体的には、「IT販促SNS活動セミナー」という文字列を指定したところ、それがしっかりと再現されていたのです。これは、かなりレベルが上がっていることを示す明確な証拠です。
日本語文字精度の向上
日本語の文字についても、まだまだ文字化けしている部分はあるものの、だいぶ良くなったことが確認できました。完璧ではありませんが、実用レベルに近づいてきていると言えます。この進化は、日本語でのビジネス利用を考える上で、非常に重要な改善点です。
仮説の立案:元画像の品質が影響しているのではないか
ここまでの検証結果を踏まえて、ひとつの仮説を立ててみました。それは、「もしかしたら、この元の写真が悪いのではないか」という仮説です。
使用していた元の写真は、かなり古い写真で、画質も良くありませんでした。この低品質な元画像が、再現精度の低さの原因になっているのではないか、と考えたのです。AIは元画像から特徴を抽出して新しい画像を生成しますから、元画像の品質が低ければ、生成結果も当然悪くなる可能性があります。
高品質な写真での再検証
そこで、同じ検証を、今度は高品質な最近の写真を使用して実施してみました。元画像を新しい、画質の良い写真に変更して、同じプロンプトで画像生成を試みたのです。
再検証の結果
結果は明らかでした。顔が変わったのです。前回の古い写真を使用した場合と比較すると、こちらの新しい写真を使用した方が、再現性は明らかに高くなっていました。
元の顔がはっきりと認識できる高品質な写真と、生成された画像を比較した場合、前回(古い写真使用時)よりも再現性が向上していることが確認できました。ただし、完璧に再現されているわけではなく、「ちょっと笑いが取れない」レベルになっていました。つまり、2回検証を実施したものの、「惜しい」という感じで、完全なネタとして笑いを取れるほどの差はない、という状況でした。
それでも、ここまで再現性がアップしたことは、確実な進化の証です。元画像の品質が、生成結果に大きく影響するという仮説が、この検証により裏付けられました。
重要な発見:AIの顔認識の一貫性
2つ目の検証を実施した際に、非常に重要な発見がありました。皆さんもお気づきかと思いますが、前回と今回で変わったこととして、同じように再現しようと頑張っているものの、再現した時には同じ顔で再現されるという特徴があったのです。
前回の検証でもそうでしたし、今回もそうでした。つまり、AIとしては、元画像の顔を認識して、「この顔と同じもの」を再現しているつもりなのです。そのAIの「つもり」というものが、AI自身にとっては100%正確だと認識されているため、毎回検証を実施しても、同じ顔で再現されるということがわかってきました。
これは、AIの顔認識と再現のメカニズムを理解する上で、非常に重要な知見です。AIは元画像から抽出した特徴を、一貫して適用しようとします。そのため、同じ元画像を使用する限り、何度生成しても同じような顔になるのです。人間から見れば「再現できていない」と感じても、AI自身は「正確に再現している」と判断しているということです。
チラシデザインでの高品質画像使用結果
チラシデザインの検証についても、高品質な写真を使用して実施してみました。結果として、かなり精度が上がっていることが確認できました。
ただし、前の写真の影響を引きずっている部分もあり、服装が派手な服になっているなどの特徴が見られました。しかし、デザイン全体に関しては、かなり文字も綺麗に入っており、「これならまあまあ使えるのではないか」という印象を受けるレベルになっていました。
もちろん、まだまだ文字化けしている部分や、完璧ではない箇所もあります。しかし、元画像と指示内容を正確に再現しているという点では、大きな進歩が見られました。この結果から、高品質な元画像を使用することの重要性が、改めて確認されました。
画像生成精度を劇的に向上させる新発見:差し替えではなく最初から作成する手法の優位性
さらなる検証から見えてきた重要な仮説
ここまでの検証結果を詳細に分析していくと、非常に興味深いパターンが見えてきました。画像生成の精度に影響を与えている要因について、新たな仮説が浮かび上がってきたのです。
誰かの顔を再現する、つまり画像内の顔を置き換えるという作業を考えてみましょう。この作業では、実は複数の処理をAIに同時に実行させていることになります。具体的には、以下の3つのステップが含まれています。
ステップ1:元の顔の認識と削除 まず、もともとあった顔写真を認識し、それを削除する(あるいは無視する)という処理が必要です。
ステップ2:新しい顔の認識 次に、差し替えたい新しい顔を認識し、その特徴を抽出する必要があります。
ステップ3:新しい顔の配置と調整 最後に、認識した新しい顔を、元の画像の適切な位置に配置し、周囲の画像と調和するように調整する必要があります。
このように、「顔を差し替える」という一見シンプルな指示の中には、実際には3つもの複雑な処理が含まれているのです。そして、これらの処理をすべて正確に実行することは、現在のAI技術にとって非常に困難なタスクなのです。
新しいアプローチ:最初から作成する方法
そこで、新しいアプローチを試してみることにしました。それが、「差し替える」のではなく、「最初から作成する」という方法です。
先ほど紹介した、サムネイル画像として作成した画像を思い出してください。あの画像は、何かを再現させたり、差し替えたりしたのではありません。最初から、指定した写真を使って、その写真を元に画像全体を作成するよう指示したものでした。
この方法であれば、元画像の顔を削除して新しい顔を配置するという複雑な処理が不要になります。単純に、提供した写真を基に、新しい画像を生成すれば良いのです。結果として、再現性は大幅に向上しました。
差し替えの複雑さと精度低下の関係
差し替えを指示すると、AIにとっては処理が複雑になり、それが精度の低下につながっていたのです。元画像の構造を理解し、その中の特定の要素(顔)だけを別のものに置き換えるというのは、極めて高度な画像処理能力が要求されます。
一方、最初から作成する場合は、提供された写真とテキストによる指示を基に、ゼロから画像を構築すれば良いだけです。この方が、AIにとってはシンプルで処理しやすいタスクなのです。
そのため、「この写真を使って、このような画像を作って」という風に指示してもらった方が、再現性も精度も上がるということがわかりました。差し替えを要求するのではなく、そのまま使って新規に作成するよう指示する方が、はるかに良い結果が得られるのです。
GoogleのGemini(Nano-Banana)との比較
ここで、興味深い比較をしてみましょう。実は、顔の再現という点では、Googleが大きな進化を遂げています。
2025年8月の終わりに、GoogleはNano-Bananaというモデルをリリースしました。このモデルの登場によって、Googleは人物の顔を完全に再現できるようになったのです。
例えば、同じようなプロンプトをGoogleのGeminiで試してみました。結果、Googleの場合は、顔を完璧に再現することができていました。これは、Nano-Bananaモデルの強力な顔認識・再現能力によるものです。
GoogleとChatGPTの得意分野の違い
ただし、Googleにも課題があります。それは、日本語フォントの生成です。顔は完璧に再現できるのですが、日本語の文字を正確に表示することは、まだまだ苦手なのです。文字が崩れたり、読めない状態になったりすることが多々あります。
また、デザイン面でも、まだ改善の余地があります。全体的なデザインのクオリティという点では、やや物足りない印象を受けることがあります。
一方、ChatGPTのGPT-Image1は、デザイン面で優れています。日本語フォントの精度も向上してきており、全体的なバランスが良いのです。したがって、この部分については、ChatGPTのGPT-Image1を使用する方が賢明だと言えます。
Soraを活用した効率的な画像生成
どうせ画像生成を行うのであれば、Soraを活用することをお勧めします。特に、Old Soraには大きなメリットがあります。
Soraの最大の利点は、1回の生成で4枚の画像を出力してくれることです。この機能は、実務上非常に便利です。
画像生成には、どうしても時間がかかります。プロンプトを入力してから、画像が完成するまで待たなければなりません。その間、ずっと画面を見ている必要はなく、他の作業をすることができます。しかし、できあがった画像を確認して、もし期待通りでなければ、また最初からやり直しになります。これを繰り返すと、どんどん時間がかかってしまいます。
しかし、1回に4枚出力されるのであれば、その4枚の中から最も良いものを選択できます。これにより、やり直しの回数を大幅に減らすことができ、作業効率が飛躍的に向上します。
実例:4枚から最適な画像を選ぶプロセス
実際の例を見てみましょう。Soraで4枚の画像を生成した場合、どのように選択するかを解説します。
選択基準1:日本語の正確性
まず最も重要なのは、日本語がちゃんと再現できているかという点です。これは実用上、非常に重要な基準です。
4枚の画像を見ていくと、以下のような状況が確認できました。
- 左上の画像:日本語が正確に再現できている
- 左下の画像:日本語が正確に再現できている
- 右上の画像:基本的には再現できているが、肝心な「GPT-5 Pro」の「Pro」の文字が小さくなってしまっている。これでは、訴求力が弱まってしまうため、あまり良くない
- 右下の画像:「Team」の後に「で」という文字があり、「でOK」となるべきところが「でOOK」となってしまっている。「o」が2つある状態で、これは明らかに間違い
このように、4枚の中で、右上と右下の画像は除外されます。
選択基準2:デザインの質と訴求力
次に、残った左上と左下の画像について、デザインの質を比較します。
今回のケースでは、「Team」という言葉を強調したかったという意図がありました。「Team」がちゃんと青色になっていたり、「Gemini 3.0 Pro」に色がついていたりする方が、視覚的な訴求力が高くなります。
このような観点から比較すると、左上の画像の方が優れていると判断できました。そのため、今回は左上の画像を採用したという経緯があります。
Soraの4枚同時生成の価値
このように、4枚を同時に生成できると、選択肢が広がります。1枚だけ生成して、それがダメだったら最初からやり直し、というプロセスを繰り返すよりも、はるかに効率的です。
最初から複数の選択肢があることで、その中から最適なものを選ぶという、より洗練されたワークフローが可能になります。これは、実務で画像生成を活用する上で、非常に重要なポイントです。
ぜひ皆さんも、この方法を参考にしてみてください。効率的な画像生成のために、Soraの4枚同時生成機能は、非常に有効なツールとなるはずです
New SoraとOld Soraの実践的活用法:画像・動画制作テクニック
Old Soraへのアクセス方法
現在、Soraには「New Sora」と「Old Sora」の2つのバージョンが存在します。それぞれに特徴があり、用途によって使い分けることが重要です。ここでは、Old Soraへのアクセス方法と、その活用法について詳しく解説します。
New SoraからOld Soraへの切り替え
新しいSoraは、動画生成に特化しています。画面を開くと、デフォルトでは動画生成モードになっています。しかし、画像生成を行いたい場合は、Old Soraに切り替える必要があります。
切り替え方法は簡単です。画面の右下に「Open New Sora」というボタンが表示されています。これは、今Old Soraを使用しているときに、New Soraに移動するためのボタンです。
逆に、New Soraを使用しているときには、画面の左下にメニューボタン(「…」で表示されている三点リーダー)があります。このボタンをクリックすると、メニューが表示され、その中に「Switch to Old Sora」という項目があります。これをクリックすることで、Old Soraに移動できます。
Old Soraでの画像生成設定
Old Soraに移動したら、画像生成の設定を行います。モードを「Image(画像)」に切り替えてください。すると、画像生成のための各種設定が可能になります。
設定項目としては、以下のようなものがあります。
- アスペクト比:3対2、1対1、2対3など、用途に応じて選択できます
- 生成枚数:4枚を選択することができます
4枚同時生成を選択することで、先ほど説明したような、複数の選択肢から最適な画像を選ぶというワークフローが実現できます。これらの設定を行ってから、プロンプトを入力して画像を生成していくと良いでしょう。
Old Soraの優位性:なぜ今でも使うべきなのか
「新しいSoraがあるのに、なぜわざわざ古いSoraを使うのか」と疑問に思われるかもしれません。しかし、Old Soraには、現時点でも大きな価値があります。
前述の通り、以前と比較して、画像生成の精度はだいぶ良くなっています。特に日本語の文字精度が向上しており、実用レベルに近づいてきています。そのため、ビジネスでの利用価値が高まっているのです。
ぜひ皆さんにも、実際に使ってみていただきたいと思います。過去にOld Soraを試して、満足のいく結果が得られなかった方も、現在の性能を改めて確認してみる価値は十分にあります。
New Soraの動画生成能力とその活用法
一方で、New Soraには、Old Soraにはない強力な機能があります。それが、動画生成機能です。実際に、New Soraで動画を作成してみた事例をいくつか紹介します。
事例1:室内デザインの動画
少し前に作成した動画の例です。室内の様子を撮影したような動画で、光の入り方が非常に気持ち良く表現されていました。家具の配置も、空間にぴったりと調和しており、高いクオリティでした。
動画内では、「君のセンスのおかげだよ、ありがとう」といった会話も含まれており、これらも正確に再現されていました。このように、静止画だけでなく、動画としても美しい映像を生成できることが、New Soraの大きな強みです。
文字の動画での再現可能性
静止画で文字が再現できるのであれば、動画でも文字を再現できるのではないか、という仮説を立てました。そこで、実際に試してみることにしました。
事例2:ボディーケアサロンの宣伝動画
具体的な事例として、愛染さんという受講生の方のボディーケアサロンの宣伝動画を作成しました。この動画では、サロンの名前やサービス内容を示す文字を、動画内に表示させることに成功しました。
文字が動画内で正確に再現されており、プロモーション素材として十分に使用できるレベルのクオリティでした。画面の右側には、使用したプロンプトも表示されており、このようなテキストを反映させることが、すでに動画レベルでできているということが確認できました。
動画から静止画へ:逆転の発想
ここで、非常に興味深い発想が生まれました。動画レベルで文字の再現ができているのであれば、画像レベルでもできるはずだ、という論理です。
さらに、もし画像生成で思うような結果が得られない場合は、動画を作成してから、その動画の中から良いシーンをスクリーンショット(画面キャプチャー)として切り出せば良いのではないか、という発想です。
動画→静止画変換のメリット
この方法には、いくつかのメリットがあります。
- 動画では文字が正確に再現されやすい
- 動画の中から、最も良いフレームを選択できる
- 複数のフレームから選べるため、選択肢が増える
- 動画としても使用できるため、一石二鳥
この方法は、従来の「画像を作る」という発想とは逆転した、新しいアプローチです。しかし、技術的には動画ができるのだから、画像もできなければいけない、という理屈は完全に正しいのです。
実践事例:地域商工会の宣伝動画
もう一つ、具体的な事例を紹介します。地元の商工会のために作成した宣伝動画です。
動画の内容としては、以下のようなメッセージが含まれていました。
「地元のお店も、物作り企業も、農業も、サービス業も、龍ケ崎市商工会がサポートします。経営相談なら」
そして動画内には、「経営相談なら龍ケ崎市商工会」という文字が表示され、さらに電話番号まで正確に表示されていました。これを見ていただければわかるように、日本語を完璧に再現できているのです。
プロンプトの詳細
この動画を作成する際に使用したプロンプトでは、表示したい文字を詳細に指示しました。画面右側に表示されているプロンプトを見ると、「こういう字を入れてね」という風に、具体的に指示しているだけなのです。
それだけで、このような高品質な動画が生成されました。プロンプトの書き方さえ理解すれば、誰でも同様の動画を作成できるということです。
効率的なワークフロー:動画と静止画の使い分け
これらの検証結果を踏まえると、以下のようなワークフローが最も効率的だと考えられます。
ステップ1:目的の明確化 まず、最終的に必要なのが静止画なのか、動画なのか、あるいは両方なのかを明確にします。
ステップ2:動画生成 New Soraを使用して、テキストを含む動画を生成します。プロンプトには、表示したい文字を明確に記載します。
ステップ3:動画の確認 生成された動画を確認し、文字が正確に表示されているか、全体的なクオリティは十分かをチェックします。
ステップ4:静止画の抽出(必要に応じて) 静止画が必要な場合は、動画の中から最も良いシーンをスクリーンショットで切り出します。これにより、高品質な静止画を得ることができます。
ステップ5:両方の活用 動画はそのまま動画素材として使用し、切り出した静止画は、ウェブサイトやSNS、印刷物などで使用します。
このワークフローにより、一度の作業で動画と静止画の両方を得ることができ、非常に効率的です。
実務での活用における重要な考え方
ここで、非常に重要な考え方について述べたいと思います。それは、「AIに画像を作らせること自体が目的ではない」ということです。
本当の目的は作業の効率化
私たちがAIを使用する本当の目的は、自分が作成する必要がある成果物を、より早く作るためです。AIに完璧な画像を生成させることに固執する必要はありません。
例えば、先ほどの検証で、顔の再現がうまくいかないという結果が出ました。しかし、それにこだわる必要は全然ないのです。逆の発想をすれば良いのです。
Canvaとの組み合わせ戦略
顔なしで画像を作成しておいて、顔は別途、自分の実際の写真を用意します。そして、Canvaなどのデザインツールを使用して、後から顔写真を組み合わせれば良いのです。この方が、はるかに早く、確実に、望む結果を得ることができます。
よく言っていることですが、何のためにこのことをやっているかというと、AIに画像を作らせることは目的ではなく、自分が作る成果物を早く作るためにAIを使いたいわけです。だから、別にそれ(AIだけでの完結)にこだわらなくても良いのです。
CanvaとAIを組み合わせて、早く作った方が良いのです。あまりAIだけにこだわらないで、もっと早く仕事を終わらせるにはどうしたら良いか、ということを考えていくことが重要です。
総合的な活用戦略
以上のことを踏まえると、Soraを使っていくこと、特にNew Soraを使っていくことを、積極的に考えていくと良いでしょう。
動画生成の能力は確実に向上しており、日本語の文字も正確に表示できるようになってきています。この技術を活用しない手はありません。
同時に、Old Soraも画像生成において進化しており、特に日本語の精度向上は実用上大きな意味があります。用途に応じて、New SoraとOld Soraを使い分け、さらには従来のデザインツールとも組み合わせることで、最も効率的で高品質な成果物を生み出すことができるのです。
重要なのは、柔軟な発想と、目的を見失わないことです。AIは強力なツールですが、それはあくまでも手段であり、目的ではありません。最終的なゴールは、質の高い成果物を、効率的に作り出すことなのです。
おわりに
本記事では、ChatGPT GPT-Image1とSoraの進化について、実際の検証結果を基に詳細に解説してきました。2025年3月〜4月時点と2025年11月時点の比較から、AI画像生成技術は確実に進化していることが確認できました。特に日本語文字の精度向上とデザイン能力の改善は、実務での活用可能性を大きく広げるものです。また、今回の検証を通じて、いくつかの重要な知見が得られました。元画像の品質が生成結果に大きく影響すること、差し替えではなく最初から作成する方が精度が高いこと、そしてAIだけに固執せず他のツールと組み合わせることの重要性です。New Soraの動画生成能力と、そこから静止画を切り出すという逆転の発想も、実践的な価値があります。技術は日々進化していますが、その進化を効果的に活用するためには、柔軟な思考と実践的なアプローチが必要です。AIはあくまでも私たちの作業を効率化するためのツールであり、最終的な目標は質の高い成果物を迅速に生み出すことです。本記事で紹介した手法やワークフローが、皆様のビジネスやクリエイティブ活動に少しでもお役に立てれば幸いです。ネットビジネス・アナリスト横田秀珠でした。ありがとうございました。
よくある質問(Q&A)
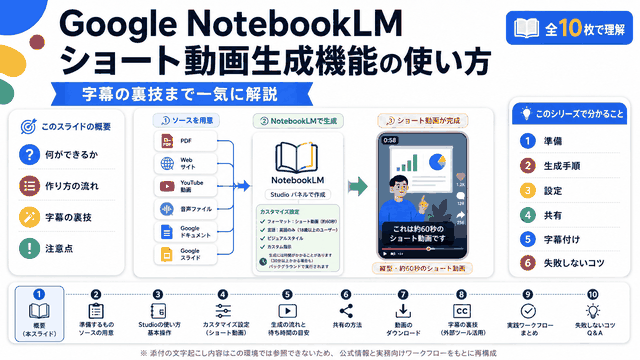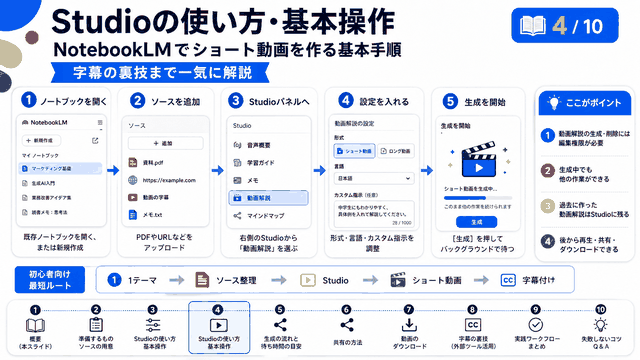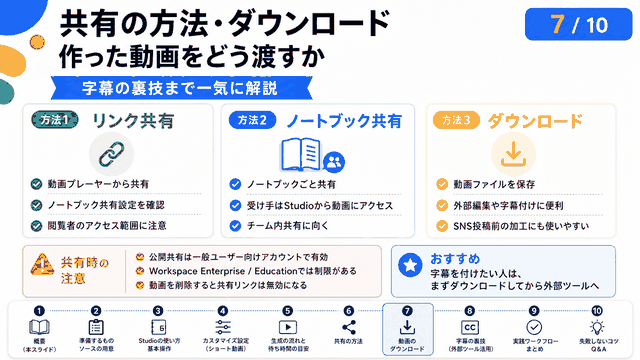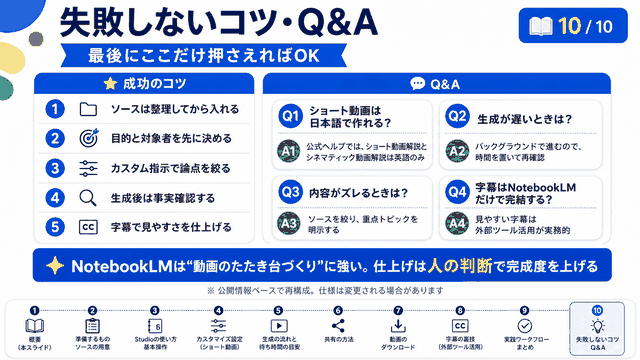
Q1: ChatGPT-5とChatGPT-4oでは、画像生成の精度にどれくらい違いがありますか?
A: 検証の結果、人物の顔の再現という点では、ChatGPT-5とChatGPT-4oの間に顕著な差は見られませんでした。どちらも、既存の画像内の人物の顔を別の人物の顔に差し替えるという作業については、まだ完璧な精度には達していません。ただし、チラシやポスターのようなデザイン制作、特に日本語文字の精度については、明らかな向上が確認できました。指定した文字列を正確に再現できる確率が高くなり、実用レベルに近づいています。建築物や空間の生成については、両バージョンとも同程度の品質を維持しています。総合的には、デザイン制作や文字入り画像の生成において、改善が見られると言えます。
Q2: Old SoraとNew Soraは、どのように使い分けるべきですか?
A: Old SoraとNew Soraは、それぞれ異なる用途に最適化されています。Old Soraは静止画像の生成に特化しており、1回の生成で4枚の画像を出力できる点が大きな特徴です。この機能により、複数の選択肢から最適な画像を選べるため、効率的な画像制作が可能です。日本語文字の精度も向上しており、ビジネス用途のバナーやチラシ制作に適しています。一方、New Soraは動画生成に特化しており、日本語テキストを含む高品質な動画を作成できます。用途としては、プロモーション動画や説明動画の制作に向いています。実践的には、静止画が必要な場合はOld Sora、動画が必要な場合はNew Sora、そして動画を作成してから良いシーンを静止画として切り出すという使い方も効果的です。
Q3: AIで人物の顔を再現する際、精度を上げるためのポイントは何ですか?
A: 顔の再現精度を上げるためには、いくつかの重要なポイントがあります。第一に、元画像の品質が極めて重要です。高解像度で、顔がはっきりと写っている最近の写真を使用することで、再現精度が大幅に向上します。古い写真や低画質の画像を使用すると、AIが正確に特徴を抽出できず、精度が低下します。第二に、プロンプトの書き方が重要です。既存の画像内の顔を「差し替える」という指示ではなく、最初から指定した写真を使って画像全体を作成するよう指示した方が、精度が高くなります。差し替えの場合、AIは元の顔の削除、新しい顔の認識、配置と調整という3つの複雑な処理を行う必要があり、精度が低下する原因となります。第三に、現時点ではGoogleのGemini(Nano-Bananaモデル)の方が顔の再現精度は高いため、用途に応じて使い分けることも検討すべきです。
Q4: Soraで生成した画像の日本語文字の精度は、実務で使えるレベルですか?
A: 2025年11月時点での検証結果では、日本語文字の精度は大幅に向上しており、実務で使用できるレベルに近づいてきています。ただし、完璧ではなく、まだ文字化けや誤字が発生する可能性はあります。実務で使用する際のポイントとしては、Soraの4枚同時生成機能を活用することが重要です。4枚生成すれば、その中に文字が正確に表示されているものが含まれる確率が高くなります。生成後は必ず文字の正確性を確認し、重要な部分(会社名、サービス名、価格など)が正しく表示されているかをチェックすべきです。また、New Soraで動画を生成してから、文字が正確に表示されているフレームをスクリーンショットで切り出すという方法も効果的です。動画の方が文字の再現精度が高い傾向があります。完璧を求めるのではなく、生成された複数の選択肢から最適なものを選ぶというアプローチが現実的です。
Q5: AIだけでなくCanvaなどの他のツールと組み合わせるべき理由は何ですか?
A: AIと従来のデザインツールを組み合わせる最大の理由は、作業効率と成果物の品質を最大化するためです。AIには得意な分野と不得意な分野があります。例えば、本検証では人物の顔の正確な再現が難しいことがわかりました。この場合、AIに完璧な顔の再現を求めて何度も生成を繰り返すよりも、AIには背景やデザイン全体を作成させ、顔部分は実際の写真をCanvaで後から配置する方が、はるかに効率的で確実です。重要なのは、「AIに画像を作らせること」自体が目的ではなく、「質の高い成果物を早く作ること」が本来の目的だということです。AIだけに固執すると、時間がかかりすぎたり、満足のいく結果が得られなかったりする可能性があります。柔軟な発想で、AIの強みを活かしながら、従来のツールの確実性も活用することで、最も効率的で高品質な成果物を生み出すことができます。この組み合わせ戦略こそが、実務でAIを活用する上での最も実践的なアプローチと言えるでしょう。
詳しくは15分の動画で解説しました。
https://www.youtube.com/watch?v=Z7cbM4brOkA

0:00 📢 導入・テーマ紹介
1:12 📅 過去の検証結果(2025年4月)
2:20 ✨ 最近の精度向上を発見
3:31 🔄 ChatGPT-5での再検証
4:42 🖼️ 新しい写真での検証結果
5:53 📰 チラシデザインの精度向上
7:00 💡 精度が落ちる理由と解決策
8:09 🆚 GoogleとSoraの比較
9:17 4️⃣ 4枚出力の選び方
10:21 🔀 Old SoraとNew Soraの切り替え
11:35 🎬 動画生成での文字再現実例
12:47 📸 動画キャプチャ活用法
13:54 🎯 まとめ・実践的アドバイス
上記の動画はYouTubeメンバーシップのみ
公開しています。詳しくは以下をご覧ください。
https://yokotashurin.com/youtube/membership.html
YouTubeメンバーシップ申込こちら↓
https://www.youtube.com/channel/UCXHCC1WbbF3jPnL1JdRWWNA/join
ChatGPT Image1搭載Old Sora進化!リアル人物写真の再現UP
🖼️ GPT-Image1 ChatGPTに搭載されている最新の画像生成AIモデルです。従来のモデルに比べて日本語テキストの再現性や画像の精度が向上しており、特にデザイン性の高い画像生成が可能になりました。Old Soraと組み合わせることで、ビジネス用途のバナーやチラシなどの制作に活用できます。
🎬 Old Sora / New Sora ChatGPTに搭載された画像・動画生成機能の新旧バージョンです。Old Soraは4枚同時の画像生成に対応し、New Soraは動画生成に特化しています。Old Soraは画像制作に便利で、New Soraで生成した動画から静止画をキャプチャする使い方も効果的です。用途に応じて切り替えて使用することが推奨されています。
🇯🇵 日本語文字精度 AI画像生成における日本語テキストの再現性の高さを指します。2025年の進化により、以前は文字化けが多かった日本語が、かなり正確に画像内に表示できるようになりました。完璧ではないものの、ビジネス用途で実用的なレベルに達しつつあり、チラシやバナー制作での活用が期待されています。
👤 人物写真再現 既存の画像内の人物写真を別の人物に差し替える機能です。AIによる顔の認識と再現には一定の限界があり、差し替えよりも最初から指定した写真で新規に画像を生成する方が精度が高いことが検証で判明しました。元写真の画質も再現性に影響します。
💬 プロンプト AIに対して指示を出すテキストのことです。画像や動画を生成する際に、どのような内容を作成してほしいかを具体的に記述します。プロンプトの書き方によって生成結果が大きく変わるため、効果的な指示文の作成スキルが重要になります。動画生成でのテキスト指定もプロンプトで行います。
🎨 画像生成 AIを使ってテキストの指示から画像を自動生成する技術です。Old Soraでは一度に4枚の画像を生成できるため、複数のデザイン案から最適なものを選択できます。バナー、チラシ、サムネイルなどの制作に活用でき、制作時間の短縮とコスト削減が期待できます。
📹 動画生成 New Soraの主要機能で、テキストプロンプトから動画コンテンツを生成します。日本語テキストの再現性が高く、企業名や電話番号なども正確に表示できます。生成した動画からスクリーンショットを撮ることで、高精度な静止画像を得る方法も紹介されています。
🤖 Gemini Googleが開発したAIモデルで、2025年8月にリリースされたNano-Bananaモデルにより、人物写真の再現性が飛躍的に向上しました。顔の再現では優れていますが、日本語フォントやデザイン性ではChatGPTのGPT-Image1に劣る部分があり、用途によって使い分けが推奨されています。
🛠️ Canva連携 AI画像生成とデザインツールCanvaを組み合わせた効率的な制作方法です。AIで背景やレイアウトを生成し、Canvaで顔写真や細部を調整することで、完全にAIだけに頼るよりも早く高品質な成果物を作れます。目的は作業効率化であり、AIは手段の一つという考え方が重要です。
⚡ 効率化 AI活用の本質的な目的です。AIに完璧を求めるのではなく、複数のツール(ChatGPT、Sora、Canvaなど)を組み合わせて、最短時間で目標を達成することが重要という考え方。制作物を早く仕上げるために何が最適かを常に考え、柔軟にツールを選択することが推奨されています。
超要約1分ショート動画こちら↓
https://www.youtube.com/shorts/3DIeoRKnr-Y

ChatGPT Image1搭載Old Sora進化!リアル人物写真の再現UP
#ChatGPT #Gemini #横田秀珠 #ChatGPTコンサルタント #ChatGPTセミナー #ChatGPT講師 #ChatGPT講演 #ChatGPT講座 #ChatGPT研修 #ChatGPT勉強会